Поиск контента на конкретном сайте через Google
Многие сайты имеют поле поиска, но если контента много и он плохо каталогизирован, пользователям бывает трудно найти нужные материалы. В таких случаях быстрее и точнее искать через Google. Главное — не ограничиваться простым вводом слова: использовать операторы и фильтры Google, чтобы быстро «вытащить» проиндексированные страницы.
1. Простой поиск по ключевым словам
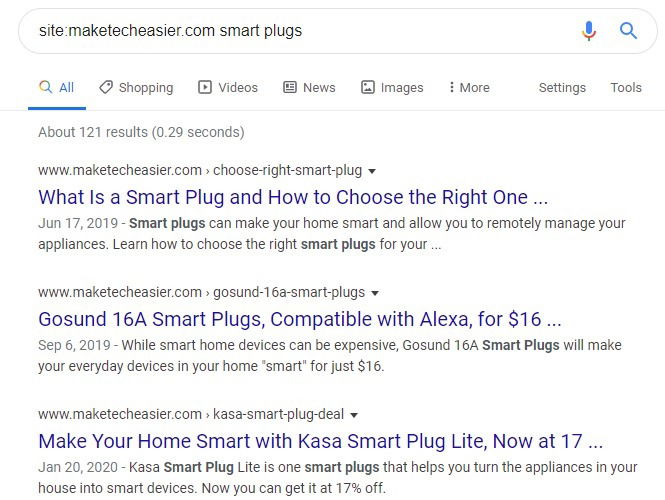
Запомните один основной приём: добавляйте оператор site: перед доменом, чтобы ограничить результаты одним сайтом. Это работает для любого домена, у которого есть проиндексированные страницы.
Пример запроса (введите в поисковую строку Google):
site:domain-name.com keyword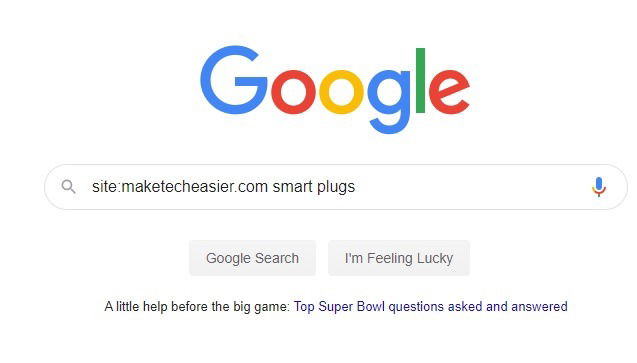
Все результаты будут только с указанного домена. Этот приём полезен, когда вы знаете ключевое слово или фразу, но не помните точный URL.
Советы:
- Заключайте фразу в кавычки, чтобы искать точное вхождение: site:example.com “точная фраза”.
- Используйте минус для исключения слов: site:example.com термин -реклама.
- Комбинируйте с intitle: для поиска по заголовкам страниц: site:example.com intitle:отчёт.
2. Поиск по диапазону дат
Если вас интересуют материалы за конкретный период (например, старые новости), используйте инструменты Google для фильтрации по дате. На странице результатов нажмите «Инструменты» → «Любой период» → «Пользовательский диапазон» и укажите даты.
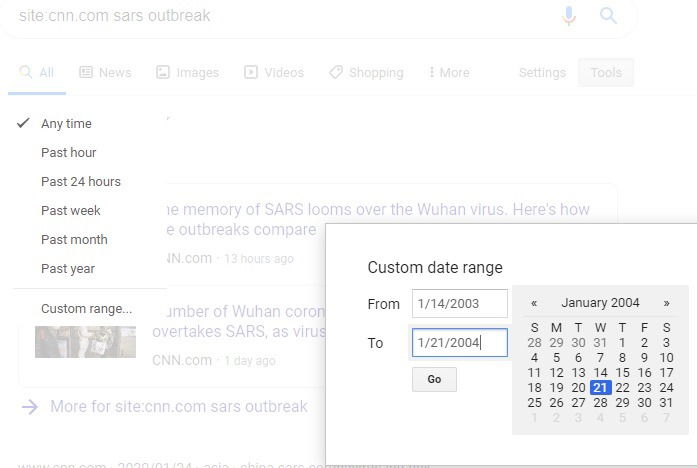
После установки диапазона вы увидите только материалы из этого периода. Это особенно полезно для новостных архивов и исторического исследования.
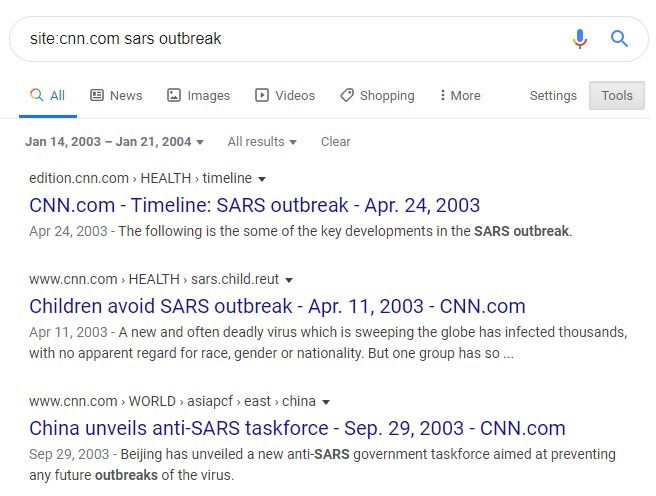
Полезно: сочетайте фильтр дат с site: и точными фразами, чтобы сузить поиск до нужного временного окна.
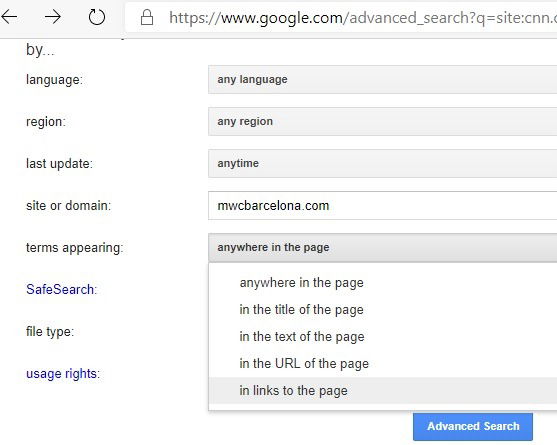
3. Включите «Расширенный поиск» и используйте формальные операторы
В меню «Инструменты» часто есть ссылка на «Расширенный поиск» — там собраны дополнительные поля и подсказки по операторам. Это простой графический интерфейс для сложных запросов.
Поиск конкретных типов файлов на сайте
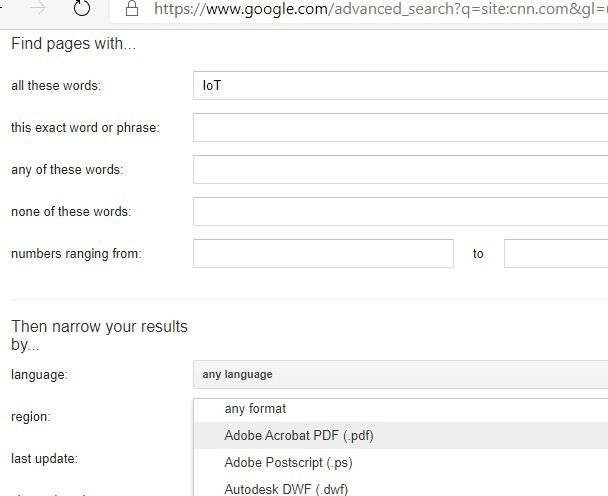
Чтобы найти, например, PDF, презентации или таблицы на сайте, используйте filetype: или воспользуйтесь полем «Тип файла» в расширенном поиске.
Примеры запросов:
- site:eventsite.com filetype:pdf IoT
- site:company.com filetype:xlsx отчет
Так вы быстро находите конференционные материалы, годовые отчёты и технические документы.
Найти ссылки и URL, связанные с ключевым словом
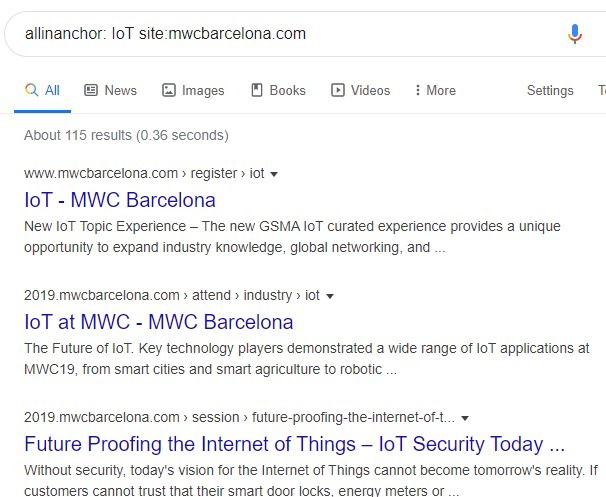
Один из полезных приёмов — искать страницы, где ключевое слово встречается в анкорах внешних или внутренних ссылок. Для этого используют операторы вроде allinanchor: и inanchor:. Они помогают найти страницы, на которые ссылаются с определённым анкором.
Пример запроса:
- allinanchor:site:example.com “ключевое слово”
Это помогает собрать список релевантных страниц по теме на сайте, даже если сами страницы слабо оптимизированы.
4. Поиск по хештегам
Если событие освещалось с хештегом, можете искать с символом # перед ключевым словом и задать нужный период. Это удобно для анализа реакции на мероприятия, кампании и конференции.
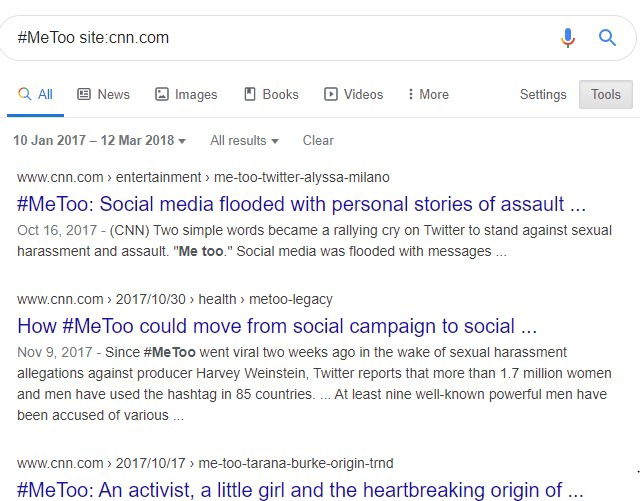
Совет: сочетайте #хештег с site: и диапазоном дат для максимальной точности.
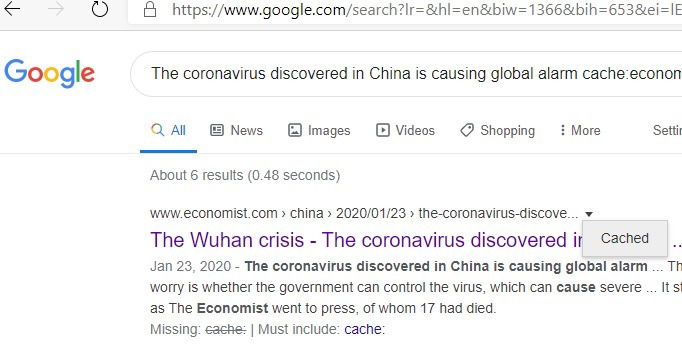
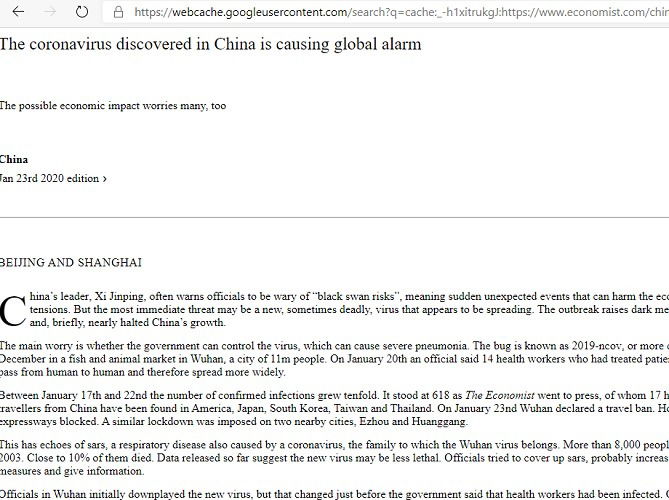
5. Обход платных стен (кэш Google)
Некоторые сайты блокируют доступ после нескольких прочтений. Если вы хотите быстро просмотреть содержимое статьи, попробуйте кэш Google.
Алгоритм:
- Скопируйте точный заголовок статьи.
- В строке поиска введите cache:URL или поищите по заголовку вместе с site: и словом “cache”.
Пример поиска кэша по заголовку:
cache:site:example.com "Точный заголовок статьи"Кэш может показать старую версию страницы — обычно с текстом и изображениями, но интерфейс на такой странице может отображаться хуже. Это законный способ увидеть проиндексированную версию страницы. Помните о юридических и этических ограничениях: уважайте права авторов и условия использования сайта.
Ещё несколько методов обхода: использовать специализированные агрегаторы, интернет-архивы (Wayback Machine) и легальные subscribe/preview-инструменты — они иногда дают доступ к содержимому без полной подписки.
Когда эти приёмы не сработают (примеры)
- Страницы не были проиндексированы Google. Тогда site: ничего не вернёт.
- Контент скрыт за авторизацией на стороне сервера и недоступен роботам.
- Сайт использует инструменты, которые запрещают индексирование через robots.txt или через метатеги noindex.
- Материалы недоступны по лицензии или находятся под сильной правовой защитой.
Важно: если Google не видит страницу, то и вы не найдёте её через описанные методы.
Альтернативы и смежные подходы
- Веб-архивы (archive.org) — для исторических снимков страниц.
- Поиск по CDN или зеркалам сайта — иногда контент кэшируют на других доменах.
- Прямой API сайта (если доступен) — надежный способ получить структурированные данные.
- Использование специализированных поисковых движков (например, для научных статей или патентов).
Мини-методика: быстрый чек-лист (5 шагов)
- Сформулируйте ключевую фразу или заголовок.
- Выполните site:domain keyword.
- Примените filetype: и фильтр дат, если нужно.
- Попробуйте allinanchor: и inurl: для поиска ссылок/URL.
- Проверьте кэш и веб-архив, если страница скрыта.
Чек-лист для ролей
- Журналист: ищите по диапазону дат, используйте кавычки для точных цитат, проверьте кэш.
- Исследователь/аналитик: ищите отчёты по filetype:pdf и filetype:xlsx внутри домена.
- Маркетолог/SEO: анализируйте allinanchor: и intitle:, чтобы найти темы с сильными внутренними ссылками.
Критерии приёмки
- Найдена хотя бы одна релевантная страница по ключевому запросу внутри сайта.
- Если ожидался PDF/отчёт — найден файл формата filetype:* на домене.
- Для исторических запросов — результаты ограничены выбранным диапазоном дат.
Глоссарий (в одну строку)
- site:: оператор Google для ограничения поиска доменом; filetype:: поиск по расширению файла; cache:: показывает сохранённую версию страницы; allinanchor:: поиск по тексту ссылок (анкорам).
Безопасность и конфиденциальность
- Поиск по Google не нарушает авторские права, если вы просматриваете проиндексированные страницы в публичном доступе.
- Не пытайтесь обходить платные стенки с целью массового скачивания или распространения защищённого контента.
- Уважайте robots.txt и правила сайта; автоматизированный парсинг может нарушать условия использования.
Краткое руководство — пошаговый пример (сценарий)
- Есть задача: найти PDF-отчёт по IoT на сайте конференции example-event.com за 2019 год.
- Запрос: site:example-event.com filetype:pdf IoT 2019
- Если много шумовых результатов — уточните: site:example-event.com “IoT” filetype:pdf “2019”.
- Если не найдено — проверьте архивную копию на archive.org или попробуйте связаться с организаторами.
Важные замечания
Важно: не все операторы Google гарантированно работают одинаково на всех рынках и в разных версиях выдачи. Если вы не видите нужного результата — попробуйте изменить формулировку, диапазон дат или проверьте настройки локализации поиска.
Заключение
Google предоставляет мощные инструменты для поиска внутри конкретного сайта. Комбинируя оператор site: с фильтрами по дате, типу файла и дополнительными операторами, вы существенно повышаете шанс найти глубоко спрятанный контент. Эти приёмы полезны для журналистов, исследователей, SEO‑специалистов и обычных пользователей.
Какой из приёмов вы уже пробовали? Напишите в комментариях.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
