
XML-файлы используются для хранения и обмена структурированными данными. До широкого распространения JSON XML был основным форматом для описания, хранения и передачи структурированной информации. Сегодня XML встречается реже, но он по‑прежнему актуален в интеграции с унаследованными системами, конфигурацией серверов, спецификациях и документации.
Важно: DOM загружает весь документ в память. Для больших XML-файлов лучше рассмотреть SAX или StAX.
Требования для обработки XML в Java
Java SE включает API для обработки XML (JAXP). Главные подходы:
- DOM: Document Object Model предоставляет классы для работы с элементами, узлами и атрибутами. DOM загружает весь документ в память — удобно для небольших и средних файлов.
- SAX: Simple API for XML — событийный парсер. Низкое потребление памяти, но сложнее в коде, так как нужно реализовывать обработчики событий.
- StAX: Streaming API for XML — потоковый парсер с pull‑архитектурой. Баланс между удобством и производительностью.
Для базовой работы в примерах ниже используются следующие пакеты:
import javax.xml.parsers.*;
import javax.xml.transform.*;
import org.w3c.dom.*; Подготовка примерного XML-файла
Для понимания примеров используем фрагмент XML (взятый из общедоступного образца):
Gambardella, Matthew
XML Developer's Guide
Computer
44.95
2000-10-01
An in-depth look at creating applications
with XML.
Ralls, Kim
...snipped... Обратите внимание: имена тегов чувствительны к регистру и должны совпадать в коде и в XML.
Чтение XML с помощью DOM API: базовые шаги
- Создайте фабрику и билдера DocumentBuilder:
DocumentBuilderFactory factory = DocumentBuilderFactory.newInstance();
DocumentBuilder builder = factory.newDocumentBuilder();- Загрузите документ и получите корневой элемент (в примере это
):
// XML file to read
File file = "";
Document document = builder.parse(file);
Element catalog = document.getDocumentElement(); После этого у вас есть доступ ко всему XML-документу, начиная с корня.
Извлечение данных через DOM API
DOM предоставляет доступ к точкам дерева. Частые задачи: получить список элементов, отфильтровать текстовые узлы, найти первый вложенный элемент с данным именем.
Пример получения всех детей элемента catalog и фильтрации только элементов:
NodeList books = catalog.getChildNodes();
for (int i = 0, ii = 0, n = books.getLength() ; i < n ; i++) {
Node child = books.item(i);
if ( child.getNodeType() != Node.ELEMENT_NODE )
continue;
Element book = (Element)child;
// work with the book Element here
} Полезная утилита: найти первый вложенный элемент с заданным именем:
static private Node findFirstNamedElement(Node parent, String tagName)
{
NodeList children = parent.getChildNodes();
for (int i = 0, in = children.getLength() ; i < in ; i++) {
Node child = children.item(i);
if (child.getNodeType() != Node.ELEMENT_NODE)
continue;
if (child.getNodeName().equals(tagName))
return child;
}
return null;
} DOM рассматривает текст внутри элемента как узлы типа TEXT_NODE. Часто текст разбит на несколько соседних текстовых узлов, поэтому удобна функция для извлечения всего текста элемента:
static private String getCharacterData(Node parent)
{
StringBuilder text = new StringBuilder();
if ( parent == null )
return text.toString();
NodeList children = parent.getChildNodes();
for (int k = 0, kn = children.getLength() ; k < kn ; k++) {
Node child = children.item(k);
if (child.getNodeType() != Node.TEXT_NODE)
break;
text.append(child.getNodeValue());
}
return text.toString();
} Пример кода, собирающего информацию о книгах и печатающего её:
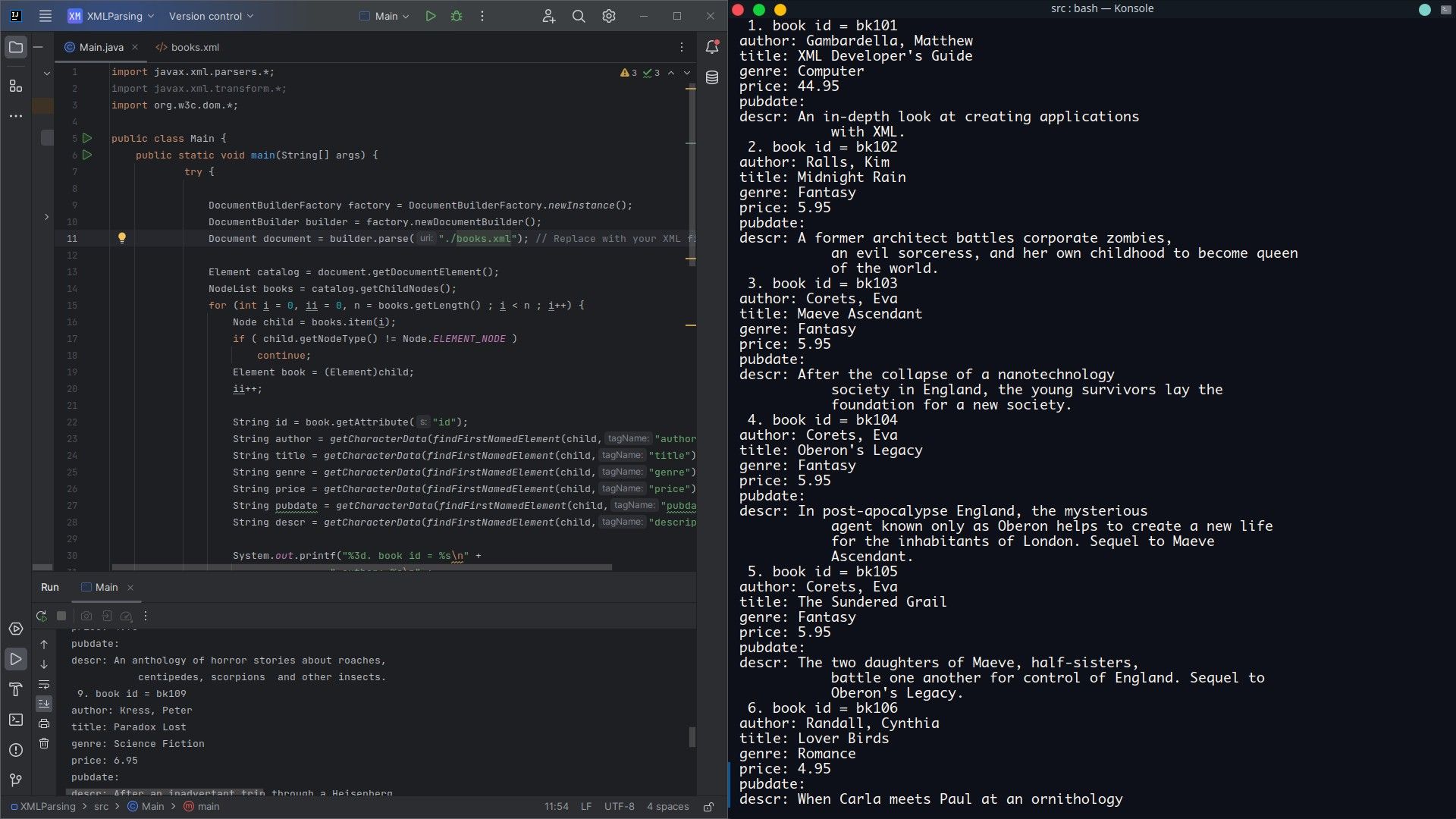
NodeList books = catalog.getChildNodes();
for (int i = 0, ii = 0, n = books.getLength() ; i < n ; i++) {
Node child = books.item(i);
if (child.getNodeType() != Node.ELEMENT_NODE)
continue;
Element book = (Element)child;
ii++;
String id = book.getAttribute("id");
String author = getCharacterData(findFirstNamedElement(child, "author"));
String title = getCharacterData(findFirstNamedElement(child, "title"));
String genre = getCharacterData(findFirstNamedElement(child, "genre"));
String price = getCharacterData(findFirstNamedElement(child, "price"));
String pubdate = getCharacterData(findFirstNamedElement(child, "pubdate"));
String descr = getCharacterData(findFirstNamedElement(child, "description"));
System.out.printf("%3d. book id = %s\n" +
" author: %s\n" +
" title: %s\n" +
" genre: %s\n" +
" price: %s\n" +
" pubdate: %s\n" +
" descr: %s\n",
ii, id, author, title, genre, price, pubdate, descr);
} Вывод будет содержать подробную информацию по каждой книге.
Запись XML с помощью Transform API
Java предоставляет XML Transform API. Часто используют т.н. identity‑преобразование, чтобы сериализовать DOM‑дерево обратно в XML.
Рассмотрим пример: добавим новую
Данные можно получить из properties-файла. Пример properties:
id=bk113
author=Jane Austen
title=Pride and Prejudice
genre=Romance
price=6.99
publish_date=2010-04-01
description="It is a truth universally acknowledged, that a single man in possession of a good fortune must be in want of a wife." So begins Pride and Prejudice, Jane Austen's witty comedy of manners-one of the most popular novels of all time-that features splendidly civilized sparring between the proud Mr. Darcy and the prejudiced Elizabeth Bennet as they play out their spirited courtship in a series of eighteenth-century drawing-room intrigues. Шаги:
- Спарсить существующий XML, как показано выше:
File file = ...; // XML file to read
Document document = builder.parse(file);
Element catalog = document.getDocumentElement(); - Загрузить properties:
String propsFile = "";
Properties props = new Properties();
try (FileReader in = new FileReader(propsFile)) {
props.load(in);
} - Получить значения и создать элемент book с дочерними элементами:
String id = props.getProperty("id");
String author = props.getProperty("author");
String title = props.getProperty("title");
String genre = props.getProperty("genre");
String price = props.getProperty("price");
String publish_date = props.getProperty("publish_date");
String descr = props.getProperty("description");
Element book = document.createElement("book");
book.setAttribute("id", id);
List elnames = Arrays.asList("author", "title", "genre", "price",
"publish_date", "description");
for (String elname : elnames) {
Element el = document.createElement(elname);
Text text = document.createTextNode(props.getProperty(elname));
el.appendChild(text);
book.appendChild(el);
}
catalog.appendChild(book); - Сериализовать и записать XML:
TransformerFactory tfact = TransformerFactory.newInstance();
Transformer tform = tfact.newTransformer();
tform.setOutputProperty(OutputKeys.INDENT, "yes");
tform.setOutputProperty("{http://xml.apache.org/xslt}indent-amount", "3");
// на консоль
tform.transform(new DOMSource(document), new StreamResult(System.out));
// или в файл
tform.transform(new DOMSource(document), new StreamResult(new File("output.xml")));Теперь документ сохранён с добавленной записью
Когда DOM не подходит
- Очень большие XML-файлы (десятки мегабайт и более): DOM потребляет много памяти, так как загружает дерево целиком.
- Потоковые сценарии обработки, где данные приходят по сети и должны обрабатываться по мере поступления.
Альтернатива: SAX или StAX. SAX хорошо для простых задач чтения при ограниченной памяти. StAX удобен, когда нужен контроль порядка событий и частичное изменение потока.
Альтернативные подходы и их применимость
- SAX: низкая нагрузка на память, хорош для чтения. Событийная модель затрудняет случайный доступ и модификацию дерева.
- StAX: pull‑парсер. Удобнее в коде, чем SAX. Позволяет читать и писать одновременно, хорошо подходит для потоковой трансформации.
- XPath вместе с DOM или StAX: поиск узлов по выражениям XPath упрощает выборку нужных элементов.
- Библиотеки третьих сторон (например, JAXB, Jackson для XML, XOM, dom4j): дают более удобные API, маппинг на POJO и дополнительные функции.
Пошаговая методология (микро‑SOP)
- Оцените размер и характер XML (разовый файл, поток, большой объём).
- Выберите модель: DOM (удобно редактировать), StAX/SAX (производительно), или библиотеку‑мэппер (удобство работы с объектами).
- Напишите тесты: парсинг, сериализация, регрессия структуры.
- При изменении XML сохраняйте исходную кодировку и префиксы namespace, если они важны.
- Обрабатывайте ошибки: парсинг, I/O, валидность схемы (XSD) — логируйте и возвращайте понятные сообщения.
Шпаргалка — быстрое руководство
- Создать DocumentBuilder: DocumentBuilderFactory.newInstance().newDocumentBuilder()
- Спарсить файл: builder.parse(new File(“path.xml”))
- Получить корень: document.getDocumentElement()
- Добавить элемент: document.createElement(“tag”) и parent.appendChild(newNode)
- Добавить текст: document.createTextNode(“text”)
- Сериализация: TransformerFactory.newInstance().newTransformer().transform(…)
Контрольные списки по ролям
Разработчик:
- Проверить соответствие имён тегов и атрибутов.
- Обработать null‑значения и отсутствующие теги.
- Написать модульные тесты на парсинг и сериализацию.
Тестировщик:
- Проверить поведение на пустом/неполном/невалидном XML.
- Замерить потребление памяти и время обработки для реального объёма данных.
- Проверить кодировку и спецсимволы.
Оператор/DevOps:
- Автоматизировать миграцию и бэкапы XML-файлов перед изменением.
- Настроить ротацию логов и мониторинг ошибок парсинга.
Частые ошибки и как их избежать
- Несоответствие имён тегов в коде и в XML. Решение: централизуйте имена тегов в константах.
- Игнорирование пространств имён (namespaces). Если XML использует namespace, включите соответствующую обработку в DocumentBuilderFactory.
- Ожидание единственного текстового узла, когда их несколько. Используйте getCharacterData или объединяйте соседние TEXT_NODE.
Важно: всегда валидируйте входные XML‑файлы, если приложение требует строгой структуры (например, с XSD).
Ментальные модели и эвристики
- «DOM = дерево в памяти»: удобно читать и модифицировать, но дорого по памяти.
- «SAX = события»: хорош для однонаправленного прохода без модификации дерева.
- «StAX = контроль»: удобный компромисс для потоковой обработки с возможностью выборочного чтения/записи.
Фактбокс — ключевые ориентиры
- DOM: подходит для файлов до нескольких мегабайт в типичных JVM. При сотнях мегабайт возможны OOME.
- SAX/StAX: используются для потоков и больших файлов. StAX проще в коде, чем SAX.
- Transformer: удобен для сериализации DOM в красивый XML с отступами.
(Значения приведены качественно; конкретные пороги зависят от JVM, настроек памяти и структуры XML.)
Советы по совместимости и миграции
- При миграции с устаревших библиотек проверьте поддержку XML namespace и чтение/запись BOM/кодировок.
- Если ваша система использует XSD, добавьте этап валидации перед использованием данных.
- Для интеграции с REST/JSON подумайте о преобразовании XML↔JSON в отдельном слое, чтобы минимизировать количество компонентов, работающих напрямую с XML.
Критерии приёмки
- Приложение корректно читает все обязательные теги и атрибуты из тестового XML.
- При добавлении новой записи (book) документ сохраняется и читается обратно без потери данных.
- Обработка невалидного XML не приводит к необработанным исключениям; ошибки логируются.
- Тесты покрытия включают сценарии с отсутствующими тегами, дополнительными неизвестными тегами и разными кодировками.
Заключение
Парсинг и модификация XML в Java — практический навык, который пригодится при интеграции с унаследованными системами и при работе с конфигурациями. DOM и Transform API удобны для задач, где требуется удобное обращение к дереву и простая сериализация. Для больших данных и потоковой обработки рассмотрите StAX или SAX.
Ключевые шаги: выбрать правильную модель (DOM/SAX/StAX), централизовать имена тегов, покрыть код тестами и обработать ошибки ввода.
Сводка:
- DOM удобен для редактирования и небольших/средних документов.
- StAX/SAX — для больших или потоковых данных.
- Transformer позволяет легко записывать отформатированный XML.
Если нужно, могу добавить пример с использованием StAX или показать, как применять XPath для выборки узлов.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
