Как проверять использование ресурсов контейнеров Docker

Быстрые ссылки
The Docker Stats Command
Getting More Info
Finding Resource Metrics With the Docker API
Viewing Running Processes
Summary
Хотя Docker легче классических виртуальных машин, большое количество контейнеров может быстро исчерпать ресурсы хоста. Ниже описаны способ и инструменты для проверки загрузки железа и счёта процессов внутри контейнеров, а также практики для диагностики и реагирования.
Команда Docker Stats
Встроенный механизм Docker для просмотра потребления ресурсов — docker stats. Эта команда показывает табличный вывод по контейнерам. Для каждого контейнера отображается поток актуальных метрик.
Вывод команды включает потребление CPU и такие агрегированные показатели, как сетевой и дисковый трафик за время жизни контейнера. Столбец Memory показывает текущую память и лимит памяти, заданный контейнеру. Если лимит не указан, отобразится объём доступной оперативной памяти хоста. Финальный столбец:
PIDSпоказывает количество процессов, запущенных процессами контейнера.

По умолчанию остановленные контейнеры исключены. Их можно добавить с флагом
-a(--all) к команде. В этом случае показатели CPU и памяти будут недоступны в реальном времени, но можно увидеть агрегированные за время жизни контейнера метрики, например сетевую активность.
Команду docker stats можно применять к одному или нескольким контейнерам так же, как и к другим командам CLI Docker: перечислите через пробел ID или имена контейнеров. Вывод покажет только указанные контейнеры.
docker stats first-container second-containerdocker stats поддерживает кастомную форматировку. Флаг --format принимает строку с плейсхолдерами Go и позволяет выбирать только нужные столбцы.
Пример: показать имена контейнеров с процентом CPU и использованием памяти:
docker stats --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}"Тип форматирования table добавляет заголовки столбцов. Уберите table, если вам нужен «сырой» вывод без табуляции. Если вы используете одну и ту же строку форматирования регулярно, имеет смысл завести shell‑псевдоним.
Important:
docker stats— это источник быстрого мониторинга. Он удобен для оперативной оценки, но не заменяет долговременное наблюдение с хранением метрик и алертингом.
Получение более подробной информации через cgroups
Для детального анализа можно обратиться к контрольным группам ядра (cgroups). Это механизм ядра Linux для лимитирования и учёта ресурсов группы процессов; метрики доступны в псевдо‑файловой системе.
Существуют две версии cgroups. cgroups v2 поддерживается в Docker 20.10+ и ядре Linux 4.15+, но документация по v2 неполна; поэтому в некоторых окружениях удобнее работать с v1.
Чтобы найти cgroup контейнера, выясните, какая версия активна, и получите полный ID контейнера (полная форма, не усечённая). Полный ID можно получить через:
docker ps --no-truncДалее комбинируйте полный ID с путём к каталогу cgroups на вашей системе. Для cgroups v1 пример пути к статистике памяти:
cat /sys/fs/cgroup/memory/docker//memory.stat Файл memory.stat содержит детальные поля по потреблению, лимитам, страничной активности и использованию swap. Аналогичные файлы существуют для CPU и блочных операций.
Советы по работе с cgroups:
- Читайте только для анализа — не меняйте содержимое вручную.
- При использовании systemd пути могут иметь префикс
system.sliceилиdocker-— проверьте и адаптируйте путь..scope - На cgroups v2 структура и названия файлов отличаются; изучите документацию вашей ОС.
Доступ к метрикам через Docker API
Более прямой способ получить данные — Docker API. По умолчанию он доступен через Unix‑сокет демона Docker. Эндпоинт /containers/{id}/stats возвращает подробные данные об использовании ресурсов. Замените {id} на ID контейнера.
curl --unix-socket /var/run/docker.sock "http://localhost/v1.41/containers/{id}/stats" | jqВ этом примере curl использует сокет Docker через флаг --unix-socket. Docker API вернёт JSON; jq сделает вывод читабельным в терминале.
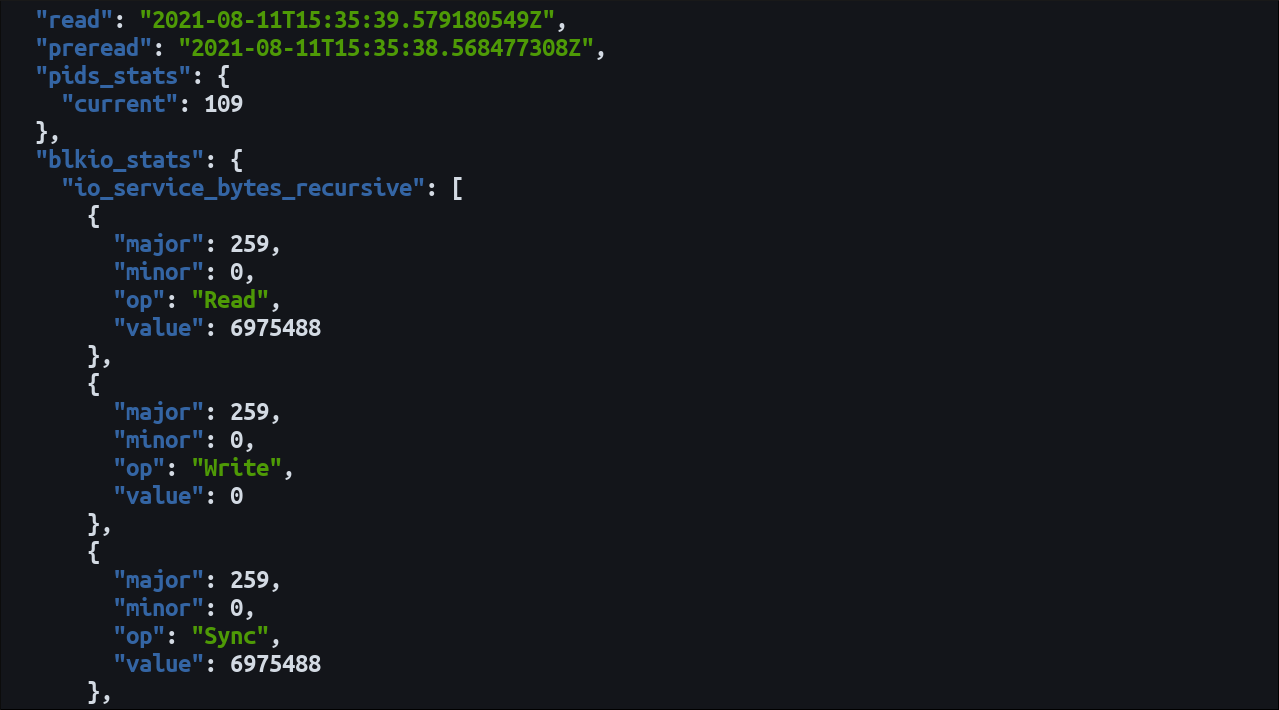
API отдаёт «сырые» числовые значения, удобные для машинной обработки или встраивания в систему мониторинга/дашборд. Для человека данные часто требуют нормализации (проценты, преобразование байт в удобные единицы).
Пример получения только текущего CPU и памяти (упрощённо) в jq:
curl --silent --unix-socket /var/run/docker.sock "http://localhost/v1.41/containers/{id}/stats?stream=false" | jq '{name:.name, cpu:.cpu_stats.cpu_usage.total_usage, mem:.memory_stats.usage}'Параметр stream=false возвращает один снимок, а не поток.
Просмотр запущенных процессов
Отдельная команда docker top показывает текущий список процессов внутри указанного контейнера:
docker top my-containerКоманда перечисляет процессы контейнера на момент выполнения. В отличие от stats, это не потоковая информация. Вы увидите PID, пользователя и команду каждого процесса.

Аналогично, ту же информацию можно получить через API, заменив /stats на /top.
Docker не предоставляет интегрированного способа просмотра использования ресурсов по отдельному процессу внутри контейнера. Для этого лучше подключиться к контейнеру и установить top или htop:
docker exec -it my-container shapt update && apt install htop -y
htop
Эти инструменты дают более глубокий взгляд на активность процессов.
Практическая методика анализа (мини‑методология)
- Быстрая проверка:
docker stats --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.PIDs}}"— найдите явных потребителей. - Снимок процессов:
docker topилиdocker exec -it— проверьте, что запущено.ps aux - Исторические и детальные данные: запрос к API
/containers/{id}/stats?stream=falseи анализ cgroup (memory.stat / cpuacct.stat). - Если нужно диагностировать per‑process: подключиться и использовать
htop/pidstat/perf. - Внедрить метрики в мониторинг: экспортируйте данные в Prometheus/Influx/Grafana для алертов и долгосрочного хранения.
Чек‑лист по ролям
DevOps / SRE
- Внедрить сбор метрик (Prometheus node_exporter + cAdvisor или Dockerd metrics).
- Настроить дашборды для CPU/памяти/пидов/сети/IO.
- Определить SLO/SLI для CPU и памяти.
Разработчик
- Локально проверять потребление при нагрузочном тесте (
docker stats). - Стрессовать приложение и фиксировать потенциальные утечки памяти.
Инженер по безопасности
- Мониторить аномалии в использовании процессов и сетевого трафика.
- Проверять незапланированные процессы внутри контейнеров.
SOP: Быстрая реакция на перегрузку контейнера
- Идентифицировать контейнер:
docker stats→ найти пиковый CPU/Memory. - Получить PID‑лист:
docker topиdocker exec -it.ps aux - Снять снимок метрик API:
curl --unix-socket /var/run/docker.sock "http://localhost/v1.41/containers/{id}/stats?stream=false" | jq .. - Если процесс можно безопасно рестартовать — перезапустить сервис в контейнере или контейнер целиком:
docker restart. - Если это приводит к повтору — откатить на предыдущую версию образа и пометить инцидент для RCA.
Критерии приёмки
- После исправления загрузка CPU/Memory возвращается в норму в течение 5 минут.
- Нет повторяемых падений сервиса в течение 24 часов.
- Запись действий и root‑cause анализа загружены в систему инцидентов.
Тест‑кейсы и критерии приёмки для мониторинга
- Настроить
docker statsэкспорт в тестовую систему: проверить, что контейнер видно и отображаются CPU/Memory/PIDs. - Симуляция утечки памяти: запустить нагрузку, наблюдать увеличение Memory и срабатывание алерта.
- Проверка
stream=falseAPI: получить единичный снимок и убедиться в валидности JSON. - Проверка cgroups: открыть /sys/fs/cgroup// и убедиться, что значения соответствуют ожиданиям по лимитам.
Решение проблем: когда встроенные инструменты не помогают (критические случаи)
- Если
docker statsпоказывает нормальные значения, но приложение падает — проблема может быть внутри процесса (утечка памяти, блокировки в коде). - Если cgroup не отражает лимиты — проверьте, использует ли ваша система cgroups v2 и соответствуют ли настройки демона Docker.
- Если метрики необычны и неинформативны — соберите трассировки и журнал контейнера (
docker logs) и выполните heap/profile дамп приложения.
Диаграмма принятия решения
flowchart TD
A[Высокая загрузка хоста] --> B{Какие метрики аномальны?}
B -->|CPU| C[Посмотреть docker stats -> найти контейнер]
B -->|Память| D[Проверить cgroups memory.stat и docker stats]
B -->|IO/Сеть| E[Посмотреть сетевые/блочные метрики через /sys/fs/cgroup и API]
C --> F{Процесс один или много?}
F -->|Один| G[Подключиться в контейнер и использовать top/htop]
F -->|Много| H[Рассмотреть лимиты, автоскейлинг или перераспределение]
G --> I[Если виноват процесс — рестарт/откат]
H --> IГлоссарий (в одну строку)
- cgroup: механизм ядра Linux для лимитирования и учёта ресурсов группы процессов.
- docker stats: команда Docker для просмотра текущих метрик контейнеров.
- Docker API: HTTP API демона Docker, доступный по Unix‑сокету.
- PIDs: количество процессов (PID) внутри контейнера.
Практические подсказки и пресеты (cheat sheet)
- Таблица с полями для быстрого
docker stats:
docker stats --format "table {{.Container}}\t{{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.NetIO}}\t{{.BlockIO}}\t{{.PIDs}}"- Снимок через API (непотоковый):
curl --silent --unix-socket /var/run/docker.sock "http://localhost/v1.41/containers/{id}/stats?stream=false" | jq .- Просмотр полного ID контейнера:
docker ps --no-trunc- Поиск cgroup пути (пример для систем с systemd):
ls /sys/fs/cgroup/*/docker | grep Риски и рекомендации по безопасности
- Не давайте доступ к
/var/run/docker.sockненадёжным процессам — это даёт привилегированный доступ к демону Docker. - Чтение cgroups безопасно, но изменение настроек без понимания может нарушить работу сервисов.
- При установке утилит внутри контейнеров учитывайте слои образа: долговременные изменения лучше вносить в образ, а не в рантайме.
Краткое резюме
Docker предоставляет несколько способов проверки использования ресурсов: docker stats для быстрого мониторинга, чтение cgroups для детальной диагностики и Docker API для автоматизации и интеграции с системами мониторинга. docker top помогает увидеть процессы, но не даёт per‑process метрик — для этого подключайтесь внутрь контейнера и используйте стандартные Linux‑утилиты. Комбинация этих инструментов с системой мониторинга и ролевыми SOP обеспечивает надёжную диагностику и реакцию на инциденты.
Ключевые рекомендации:
- Используйте
docker statsдля быстрого обследования и API/cgroups для глубокого анализа. - Интегрируйте сбор метрик в систему мониторинга для алертов и долгосрочного анализа.
- Всегда проверяйте полный ID контейнера при работе с cgroups.
Похожие материалы

Как сохранить Google Maps офлайн

Как эффективно исследовать сабреддит

Поделиться интернетом и паролем Wi‑Fi с Mac

YAML в Go: чтение, запись и лучшие практики
Как удалить аккаунт Temu — полное руководство
