Как извлечь текст из изображений и PDF с помощью gImageReader
Важно: gImageReader — это фронтенд для Tesseract. Установите Tesseract перед установкой gImageReader.
Что такое gImageReader
gImageReader — это графическое приложение для Linux, которое упрощает работу с Tesseract OCR. В двух словах: Tesseract — это движок оптического распознавания текста (OCR). gImageReader добавляет удобный интерфейс, средства предварительной обработки изображений, пакетную обработку и экспорт результатов.
Определение: OCR (Optical Character Recognition) — автоматическое преобразование изображений с текстом в редактируемый текст.
Основные возможности gImageReader
gImageReader включает следующие функции:
- Импорт PDF и изображений с диска, сканера, из буфера обмена или сделав скриншот
- Пакетная обработка нескольких файлов одновременно
- Экспорт результатов как простой текст или как hOCR (формат с разметкой расположения блоков)
- Встроенная проверка орфографии
- Автоопределение областей с текстом
- Базовые инструменты для корректировки изображений (яркость, контраст, поворот, инверсия)
- Сохранение результата в текстовый файл или PDF
Подготовка: что нужно знать перед установкой
- Tesseract — ядро распознавания. gImageReader без него не работает.
- Языковые пакеты Tesseract устанавливаются отдельно (например, для английского — tesseract-ocr-eng).
- Если у вас много старых/нечётких сканов, планируйте этап предварительной обработки.
Как установить Tesseract и gImageReader
На Debian/Ubuntu выполните в терминале:
sudo add-apt-repository ppa:sandromani/gimagereader
sudo apt-get update
sudo apt install gimagereaderПеред этим установите tesseract и языковые пакеты:
sudo apt install tesseract-ocr tesseract-ocr-engНа Fedora/RHEL/CentOS:
sudo dnf install gimagereader-qtНа Arch Linux/Manjaro:
sudo pacman -S gimagereaderНа openSUSE:
sudo zypper install gimagereaderЕсли дистрибутива нет в списке, собирайте из исходников по инструкции на GitHub проекта.
Примечание: названия пакетов и менеджеры пакетов зависят от версии дистрибутива. Если команда не сработала, проверьте репозитории или документацию вашего дистрибутива.
Пошаговое руководство по использованию gImageReader
- Откройте меню приложений и запустите gImageReader.
- Для удобства увеличьте окно на весь экран (кнопка “Развернуть”).
- Нажмите кнопку “Add images” и выберите файлы или PDF. Можно также выбрать действие “Take Screenshot”, чтобы распознать текст с экрана.
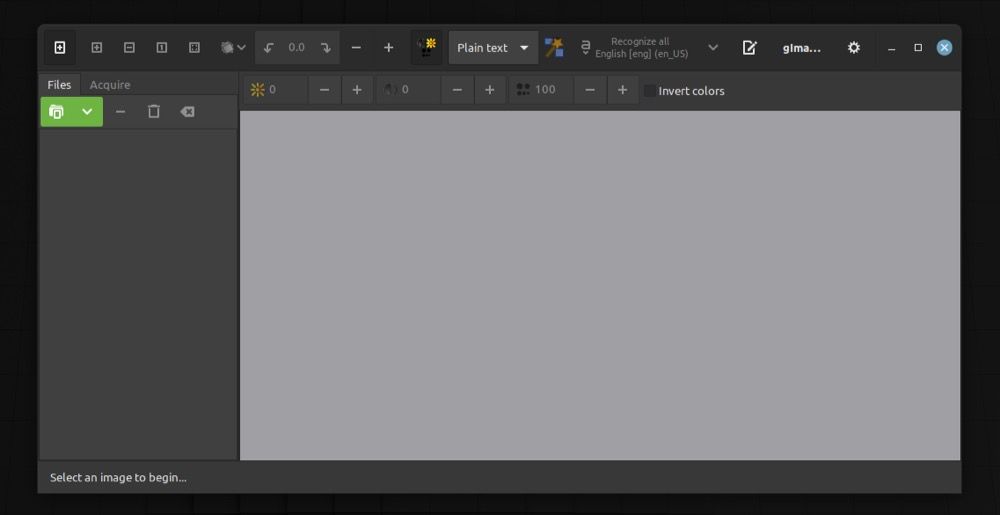
- После импорта откройте панель вывода — кнопка с иконкой блокнота. В ней отображается распознанный текст.
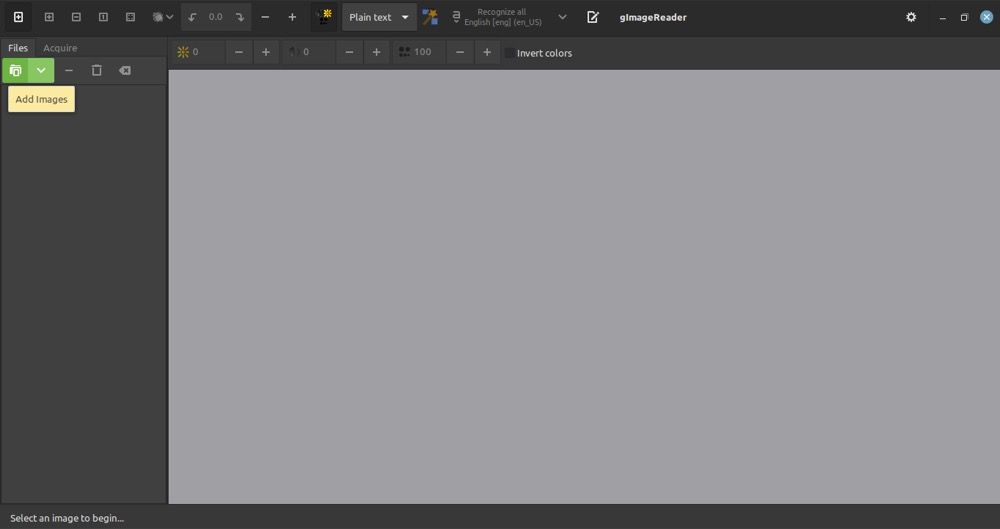
- Есть два режима выделения текста:
- Автоматический: нажмите “Autodetect layout” — программа выделит текстовые блоки.
- Ручной: нарисуйте рамку вокруг нужной области с помощью прицела.
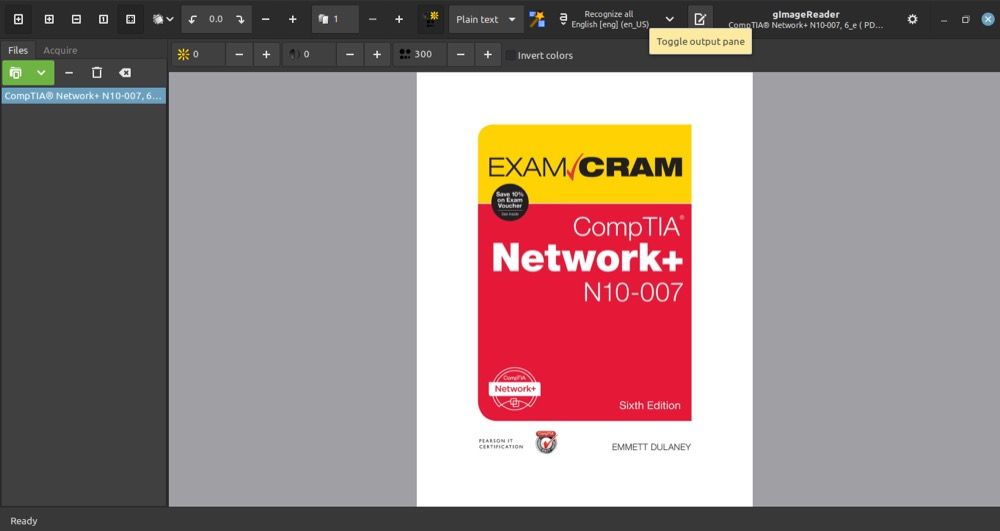
- Нажмите “Recognize selection” > “Current Page” для начала распознавания выбранной области.
- Для мультистраничных PDF используйте кнопки “+” и “-“ для переключения страниц.
Если распознанный текст на другом языке — выберите нужный язык через выпадающее меню рядом с кнопкой распознавания.
Сохраните результат через “Save output” — задайте имя и формат.

Советы по улучшению качества распознавания
Качество OCR сильно зависит от качества исходного изображения. Вот проверенные приёмы:
- Обрежьте лишние поля и полосы вокруг текста.
- Увеличьте контраст и уберите шумы (кнопки в Image Controls).
- Поверните страницы так, чтобы текст был ровно горизонтально.
- Используйте однотонный фон и избегайте цветных помех.
- Для старых сканов попробуйте предварительную двоичную (binarize) фильтрацию: это иногда улучшает читаемость.
- Если есть смешение шрифтов или особые символы, попробуйте установить соответствующие языковые/шрифтовые пакеты для Tesseract.
Важно: автоматическое выделение макета не всегда правильно распознаёт многоколонные макеты и таблицы. В таких случаях используйте ручное выделение блоков.
Устранение неполадок: когда gImageReader ошибается
Типичные проблемы и решения:
- Низкое качество текста: примените фильтры (контраст, яркость, инверсия).
- Неправильный язык распознавания: установите и выберите нужный языковой пакет Tesseract.
- Разбитый вывод в hOCR: попробуйте распознавать по блокам, а не по всей странице.
- Ошибки в пакетной обработке: проверяйте первые несколько файлов вручную, прежде чем обрабатывать сотни.
Когда gImageReader не подходит
- Если нужен облачный OCR с автоматической коррекцией макетов и сложных документов (например, банковские выписки с таблицами), лучше использовать коммерческие сервисы.
- Для мобильной съёмки документов удобнее специализированные мобильные приложения со встроенной коррекцией перспективы.
- Для массовой автоматизированной обработки с REST API и масштабируемостью используйте отдельные OCR-сервисы.
Альтернативы и сравнение (кратко)
- Tesseract CLI — если вы предпочитаете скрипты и автоматизацию.
- OCRmyPDF — для пакетной интеграции OCR в PDF с командной строки (подходит для архивации).
- TextSnatcher — простой инструмент для захвата текста с экрана.
- Коммерческие сервисы (Google Vision, Azure OCR, ABBYY) — лучше распознают сложные макеты и рукопись, но платные.
Сравнительная матрица (ключевые критерии):
- Удобство: gImageReader — высокое (GUI).
- Автоматизация: Tesseract CLI / OCRmyPDF — лучше.
- Качество на сложной верстке: коммерческие сервисы — лучше.
- Цена: gImageReader/Tesseract/OCRmyPDF — бесплатно.
Модель принятия решения (простая эвристика)
- Требуется GUI и ручная корректировка — выбирайте gImageReader.
- Требуется обработать тысячи PDF без вмешательства — OCRmyPDF + Tesseract / коммерческий API.
- Нужен мобильный захват — мобильные приложения.
Мини-методология: оптимальный рабочий поток
- Импортируйте изображения/PDF в gImageReader.
- Примените предварительную обработку (яркость, контраст, инверсия).
- Автоопределите макет и проверьте области вручную.
- Распознайте по страницам или пакетно.
- Проверьте и исправьте ошибки в выводе.
- Экспортируйте в текст/HOCR/PDF.
Чеклист по ролям
Для студента:
- Быстро захватить скриншот -> распознать -> вставить текст в заметки.
- Проверить форматирование и цитаты.
Для администратора/архивариуса:
- Пакетная обработка сканов архивов.
- Создание поисковых PDF через OCRmyPDF (если нужен индексируемый PDF).
Для офисного пользователя:
- Проверка качества распознавания по первому документу.
- Установка шаблонов сохранения и именования.
Примеры тестовых случаев и критерии приёмки
Тест 1: простая фото-страница с печатным текстом
- Ожидаемый результат: >95% точности распознавания базовых символов, минимальные проблемы со знаками пунктуации.
Тест 2: страница с двухколоночным макетом
- Критерии приёмки: разделение колонок без перемешивания строк, корректная очередность текста.
Тест 3: плохой скан с низким контрастом
- Критерии приёмки: при предварительной обработке читаемый текст, допустимый уровень ошибок для ручной правки.
Практический Cheat Sheet (сокращённо)
- Быстро: Add images → Autodetect layout → Recognize selection → Save output
- Язык: убедитесь, что в выпадающем списке выбран нужный языковой пакет
- Пакетно: поместите все файлы в одну папку и импортируйте пакетно
- Экспорт: выбирайте текст для дальнейшей правки или hOCR для сохранения структуры
Решающее дерево: стоит ли использовать gImageReader?
flowchart TD
A[Нужно распознать текст?] --> B{Нужна GUI-правка?}
B -- Да --> C[gImageReader]
B -- Нет --> D{Пакетная автоматизация?}
D -- Да --> E[OCRmyPDF + Tesseract]
D -- Нет --> F[Tesseract CLI]
C --> G{Сложная разметка/таблицы?}
G -- Да --> H[Коммерческий OCR]
G -- Нет --> I[gImageReader подходит]Факты и ожидания
- Tesseract — один из самых популярных открытых движков OCR.
- gImageReader добавляет GUI и простые инструменты предварительной обработки.
- Результат распознавания зависит от качества исходного изображения, языка и шрифта.
Краткий глоссарий
- OCR — оптическое распознавание текста.
- hOCR — формат вывода, содержащий HTML-разметку расположения текста.
- Binarize — преобразование изображения в чёрно-белое для улучшения распознавания.
Короткое объявление (для рассылки, 100–200 слов)
gImageReader — бесплатное приложение для Linux, которое упрощает извлечение текста из изображений и PDF. Работая как графический интерфейс для движка Tesseract, оно даёт быстрый доступ к автоопределению текстовых областей, ручному выделению, базовой корректировке изображений и пакетной обработке. Пользователи могут сохранять результаты в текстовый файл или hOCR, а также комбинировать gImageReader с инструментами командной строки, такими как OCRmyPDF, для создания полнотекстовых PDF. Подходит студентам, офисным сотрудникам и архивариусам, которые ценят простоту и автономность без облачных сервисов.
Итог и рекомендации
gImageReader — удобный и бесплатный инструмент для большинства задач OCR на рабочей станции Linux. Если вы работаете с небольшими наборами документов или предпочитаете ручную корректировку перед распознаванием, gImageReader ускорит процесс и упростит работу. Для массовой автоматизации или обработки сложных макетов рассмотрите OCRmyPDF или коммерческие API.
Примечание: всегда храните оригинальные сканы и проверяйте первые результаты распознавания вручную при работе с важными документами.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
