Как копировать текст из изображений на Linux с помощью TextSnatcher
Введение
Умение копировать текст из изображения экономит время и уменьшает ручной ввод. На Linux нет универсальной встроенной утилиты OCR, поэтому приходится использовать сторонние решения. Большинство таких инструментов работают в терминале и не всегда удобны для пользователей, привыкших к графическому интерфейсу.
TextSnatcher решает эту проблему: это лёгкая и интуитивная программа, которая упрощает процесс извлечения текста с экрана или изображения. Ниже рассмотрим, что это за приложение, как его установить и как эффективно использовать, а также разберём альтернативы и рекомендации по отладке.
Что такое TextSnatcher
TextSnatcher — это графический интерфейс поверх движка распознавания текста Tesseract. Tesseract — проверенный OCR-движок с открытым кодом, поэтому TextSnatcher наследует его точность и скорость распознавания.
Ключевые функции:
- поддержка нескольких языков: английский, китайский, японский, испанский, французский, немецкий и арабский
- интеграция со скриншот-утилитой для быстрого захвата области экрана
- вставка изображений из файла и из буфера обмена
- простота интерфейса и быстрый доступ к результату через буфер обмена
Краткое определение терминов
- OCR: Optical Character Recognition, оптическое распознавание символов
- Tesseract: открытый OCR-движок, используемый как «мотор» для распознавания
Установка TextSnatcher на Linux
TextSnatcher совместим с основными дистрибутивами Linux. Ниже перечислены распространённые способы установки.
Установка через Flathub (рекомендуется для большинства пользователей)
- Проверьте наличие Flatpak на системе, открыв терминал и выполнив:
flatpak --versionЕсли команда возвращает версию, Flatpak уже установлен. Если нет, установите Flatpak согласно документации вашего дистрибутива.
- Установите TextSnatcher из Flathub:
flatpak install flathub com.github.rajsolai.textsnatcherЭтот способ удобен тем, что пакет изолирован и не требует ручной установки зависимостей.
Установка из AppCenter (для пользователей elementary OS)
Пользователи elementary OS могут установить TextSnatcher через встроенный магазин приложения AppCenter. Найдите приложение по имени и установите обычным способом через графический интерфейс.
Загрузка: TextSnatcher
Сборка из исходников (для опытных пользователей)
Если требуется конкретная версия или вы хотите внести изменения, программу можно собрать из исходников. Перед сборкой потребуется установить зависимости:
- granite
- gtk+-3.0
- gobject-2.0
- gdk-pixbuf-2.0
- libhandy-1
- libportal-0.5
После установки зависимостей выполните в терминале следующие команды:
git clone https://github.com/RajSolai/TextSnatcher.git TextSnatchercd TextSnatchermeson build --prefix=/usrcd buildsudo ninja install && com.github.rajsolai.textsnatcherСборка подходит для тех, кто знаком с Meson и Ninja и хочет гибкий контроль над версией.
Как пользоваться TextSnatcher
После установки запустите TextSnatcher через меню приложений. Окно приложения компактное; при желании измените его размер, чтобы было удобнее работать.
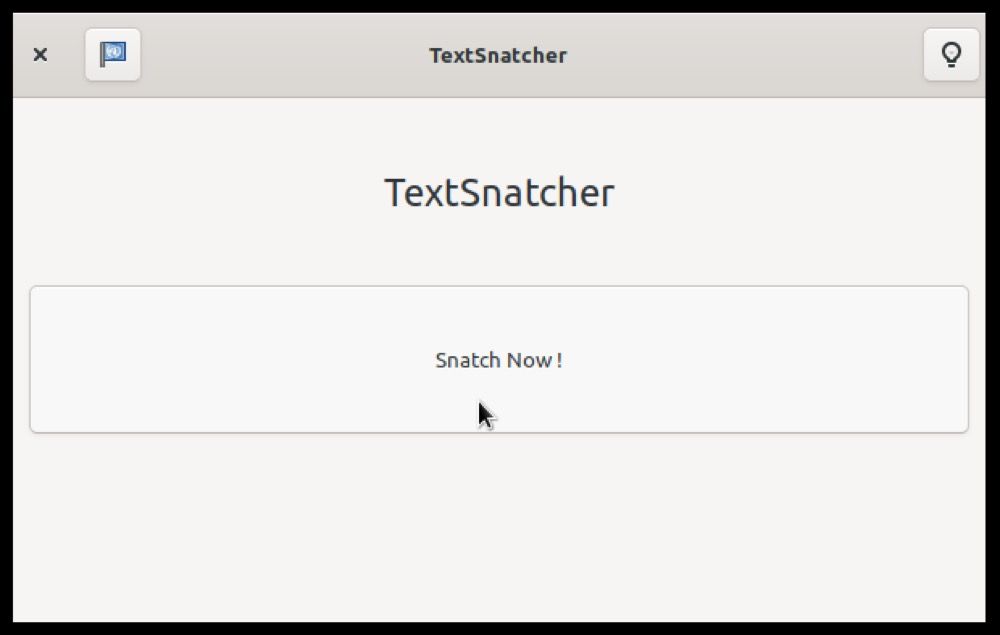
Выбор языка распознавания
Нажмите на значок флага в левом углу окна и выберите язык, с которого нужно распознать текст. Это важно: точность распознавания напрямую зависит от выбранного языка.
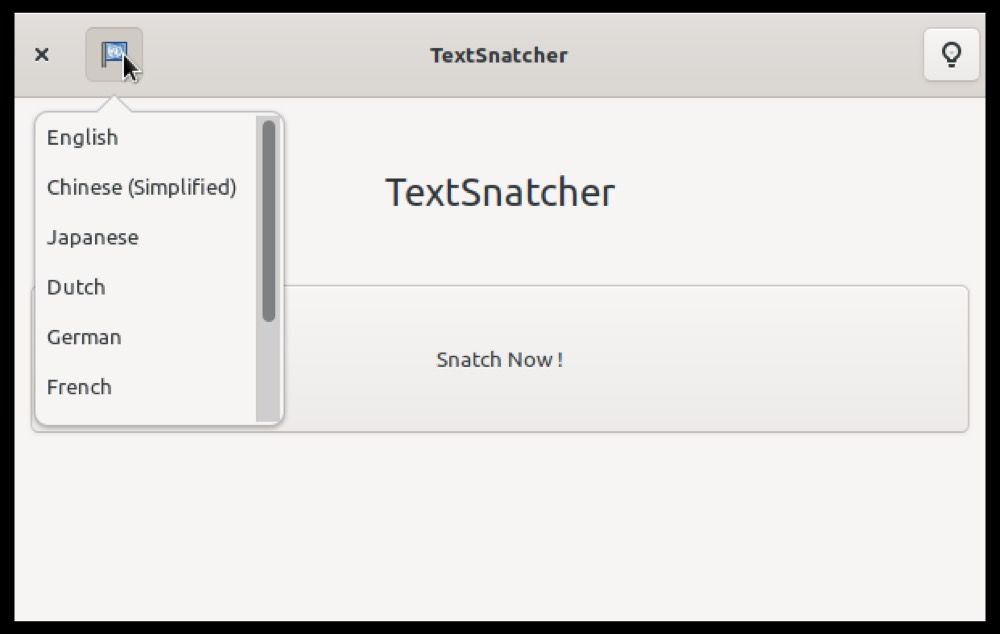
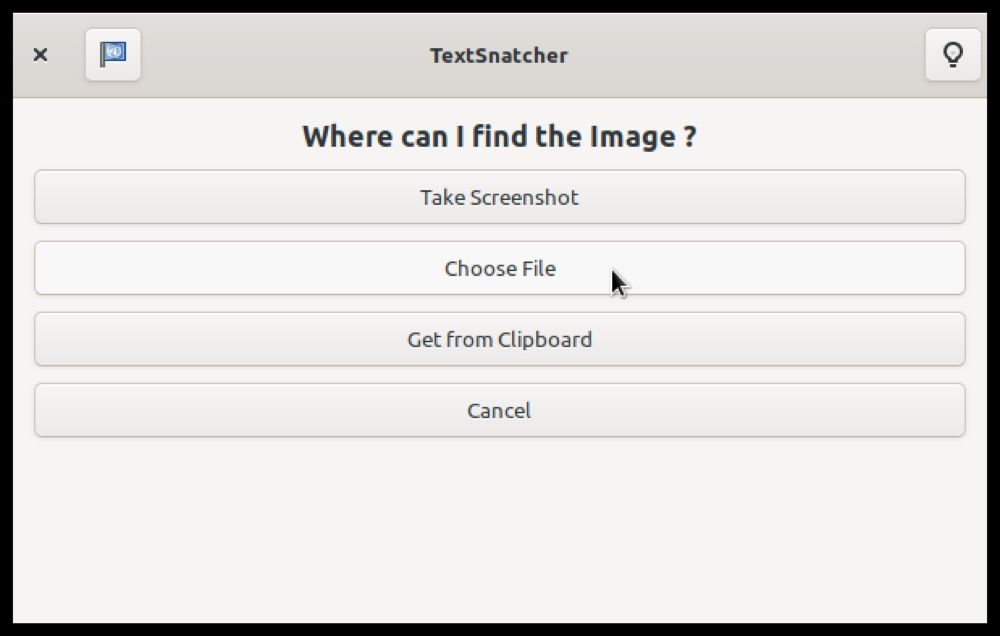
Три способа подать изображение в TextSnatcher
Нажмите кнопку Snatch Now, чтобы открыть три варианта ввода изображения:
- Take Screenshot — сделать скриншот области экрана
- Choose File — выбрать файл изображения с диска
- Get from Clipboard — получить изображение из буфера обмена
Вариант 1: Сделать скриншот
Нажмите Take Screenshot. TextSnatcher запустит утилиту scrot и покажет перекрестие-курсор. Выделите область с текстом. Через несколько секунд текст будет распознан и скопирован в системный буфер обмена. Вставьте его в любое приложение сочетанием Ctrl+V.
Вариант 2: Выбрать файл
Нажмите Choose File, укажите файл в файловом менеджере и подтвердите. TextSnatcher прочитает изображение и сохранит текст в буфере обмена.
Вариант 3: Вставить из буфера обмена
Скопируйте изображение в буфер обмена и выберите Get from Clipboard. На некоторых системах, особенно с менеджером окон X11, этот способ может работать нестабильно. Если возникает ошибка, попробуйте временно сохранить изображение в файл и использовать Choose File.
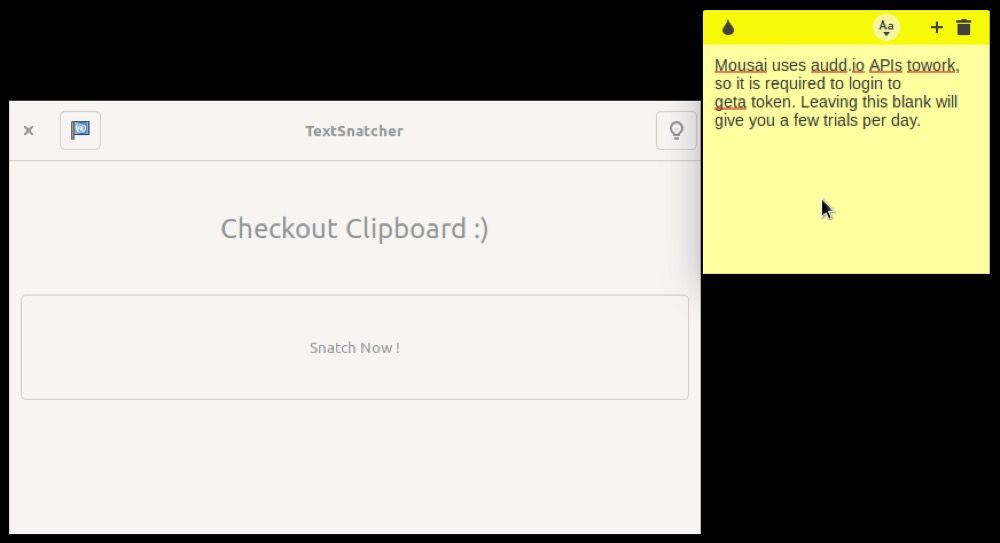
Important: поведение буфера обмена зависит от среды рабочего стола и версии X11 или Wayland. На Wayland доступ к буферу обмена может быть более ограничен из соображений безопасности.
Практические советы и полезные приёмы
- Всегда выбирайте язык распознавания, соответствующий содержимому изображения.
- Для повышения точности предварительно обрежьте лишние области и увеличьте контраст изображения.
- Если текст мелкий, сделайте скриншот с увеличением (zoom) или используйте скриншот в высоком разрешении.
- Проверяйте результат распознавания на орфографические ошибки и неправильное разбиение слов.
Отладка и устранение проблем
Когда TextSnatcher не распознаёт текст или возвращает пустой буфер, проверьте:
- Установлен ли Tesseract и поддерживаются ли нужные языковые пакеты.
- Работает ли утилита scrot для скриншотов.
- Наличие ограничений буфера обмена в вашей сессии (особенно на Wayland).
- Качество изображения: сильные шумы, низкая контрастность или искажённые символы снижают точность.
Примеры команд для проверки:
- Проверка наличия tesseract:
tesseract --version- Если нужен дополнительный языковой пакет, его можно установить через менеджер пакетов дистрибутива или через Flatpak runtime, в зависимости от способа установки.
Альтернативные подходы и инструменты
Если TextSnatcher по каким-то причинам вам не подходит, обратите внимание на следующие варианты:
- Прямое использование Tesseract в терминале для пакетной обработки изображений
- Онлайн-сервисы OCR, если вы готовы загружать изображения в сеть
- Сторонние графические приложения с OCR, например gImageReader, которые также используют Tesseract
- Инструменты для извлечения текста из PDF, если исходный файл в формате PDF
Каждый вариант имеет свои плюсы: локальные инструменты лучше для приватности, онлайн-сервисы иногда проще и не требуют установки.
Модель принятия решения: когда использовать TextSnatcher
flowchart TD
A[Есть изображение с текстом] --> B{Нужно локальное решение?}
B -- Да --> C[Используйте TextSnatcher]
B -- Нет --> D[Онлайн OCR]
C --> E{Требуется массовая обработка?}
E -- Да --> F[Используйте Tesseract в терминале]
E -- Нет --> G[TextSnatcher достаточно]
D --> H[Проверить политику приватности]Минимальная методология для извлечения текста
- Выберите язык распознавания.
- Захватите изображение (скриншот, файл или буфер обмена).
- Если возможно, предварительно улучшите изображение: обрезка, контраст, поворот.
- Запустите распознавание в TextSnatcher.
- Вставьте результат из буфера обмена в текстовый редактор и проверьте ошибки.
Ролевые чек-листы
Для повседневного пользователя:
- Установить TextSnatcher из Flathub
- При необходимости установить Flatpak
- Выбрать язык и сделать скриншот
- Вставить текст в заметки и проверить
Для системного администратора:
- Проверить наличие tesseract и языковых пакетов
- Автоматизировать сбор статистики ошибок OCR (по необходимости)
- Контролировать разрешения на доступ к буферу обмена в защищённых окружениях
Критерии приёмки
- Распознаётся выбранный язык при корректном входном изображении
- Текст появляется в системном буфере обмена в читаемом виде
- Приложение запускается без ошибок на целевом дистрибутиве
Примеры когда TextSnatcher не подойдёт
- Необходимо распознавать большой объём файлов пакетно — лучше использовать Tesseract напрямую
- Требуется повышенная приватность и запрет на GUI-программы с доступом к буферу обмена в серверной среде
- Работа с нестандартными шрифтами или рукописным текстом, где нужна специализированная модель OCR
Сравнение в общих чертах
- TextSnatcher: графический интерфейс, удобно для интерактивной работы, локальное исполнение
- Tesseract CLI: гибкость и масштабируемость, лучше для пакетной обработки
- Онлайн-сервисы: простота, но возможны вопросы приватности
Часто задаваемые вопросы
Работает ли TextSnatcher с рукописным текстом
TextSnatcher использует Tesseract, который хуже распознаёт рукописный текст по сравнению с печатным. Для рукописного текста лучше искать специализированные модели OCR.
Нужны ли дополнительные языковые пакеты
Для некоторых языков может потребоваться установка языковых пакетов Tesseract. Если распознавание некорректно, проверьте наличие соответствующего пакета.
Заключение
TextSnatcher — удобный и быстрый способ извлечь текст из изображений на Linux, особенно когда нужен простой графический инструмент. Он сочетает удобство с локальным исполнением и поддержкой нескольких языков. Для крупномасштабных задач и точной настройки остаётся вариант с Tesseract напрямую или специализированные инструменты.
Summary:
- TextSnatcher подходит для интерактивного извлечения текста
- Выбор языка и качество изображения критичны для точности
- Для пакетной обработки предпочтителен Tesseract в терминале
Дополнительные ресурсы и советы по безопасности: при использовании онлайн-сервисов проверьте их политику конфиденциальности. На рабочих станциях с Wayland возможны ограничения доступа к буферу обмена, что влияет на функциональность Get from Clipboard.
FAQ
- Как проверить версию Flatpak
Выполните в терминале:
flatpak --version- Как проверить установку Tesseract
Выполните:
tesseract --version- Что делать если Get from Clipboard не работает
Сохраните изображение во временный файл и выберите Choose File, либо проверьте настройки окружения рабочего стола и права доступа к буферу обмена.
- Какие альтернативы использовать
gImageReader, прямой Tesseract, онлайн OCR-сервисы.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
