Конкурентность и параллелизм в Python: когда и как выбирать
Основная цель статьи
Разобрать разницу между конкурентностью и параллелизмом, показать инструменты Python (threading, asyncio, multiprocessing), дать практические критерии выбора, примеры кода и операции для продакшен‑решений: чек‑листы, методологии и дерево решений.
Похожие запросы (варианты пользовательского намерения)
- конкурентность в Python
- параллелизм Python multiprocessing vs threading
- asyncio примеры и когда использовать
- как ускорить I/O‑bound и CPU‑bound задачи в Python
Понятия в одну строку
- Конкурентность — управление несколькими задачами так, чтобы они продвигались одновременно (переключение контекста). Это улучшает отзывчивость.
- Параллелизм — одновременное исполнение нескольких задач на разных ядрах CPU.
- GIL — глобальная блокировка интерпретатора CPython, препятствующая истинному параллелизму потоков внутри одного процесса.
Понимание конкурентности и параллелизма
Конкурентность и параллелизм — это два подхода к выполнению нескольких задач. Они пересекаются, но служат разным целям:
- Конкурентность организует порядок и переключение задач. Она полезна, когда задачи часто ждут ввода/вывода и требуется высокая отзывчивость.
- Параллелизм использует аппаратные ресурсы (несколько ядер) для одновременной работы задач, критичен для тяжелых вычислений.
Важно: конкурентность не гарантирует параллельного выполнения — поток может быть активен только по очереди; параллелизм гарантирует одновременность.
Почему это важно
- Повышает использование ресурсов: вместо простоя программа выполняет полезную работу.
- Улучшает отзывчивость пользовательского интерфейса и серверов.
- Обеспечивает масштабируемость при росте нагрузки.
- Позволяет использовать современные многоядерные CPU для ускорения вычислений.
Конкурентность в Python
В Python основные инструменты для конкурентности: threads (потоки) и asyncio (асинхронные сопрограммы). Оба подхода хороши для I/O‑bound задач, но имеют разный стиль программирования и модель ошибок.
Потоки (threading)
Потоки живут внутри одного процесса и разделяют память и ресурсы процесса. В CPython действует GIL — один поток выполняет байткод в единицу времени, поэтому многопоточность не ускоряет CPU‑bound задачи. Зато потоки полезны при блокирующем I/O: пока один поток ждёт ответа сети, другой может работать.
Плюсы:
- Простота концепции (параллельная логика через потоки).
- Хорошо работает для блокирующего I/O и обёрток библиотек, которые сами снижают блокировку (например, C‑расширения).
Минусы:
- GIL ограничивает параллелизм CPU‑bound задач.
- Сложность в отладке гонок и синхронизации (locks, Event, Condition).
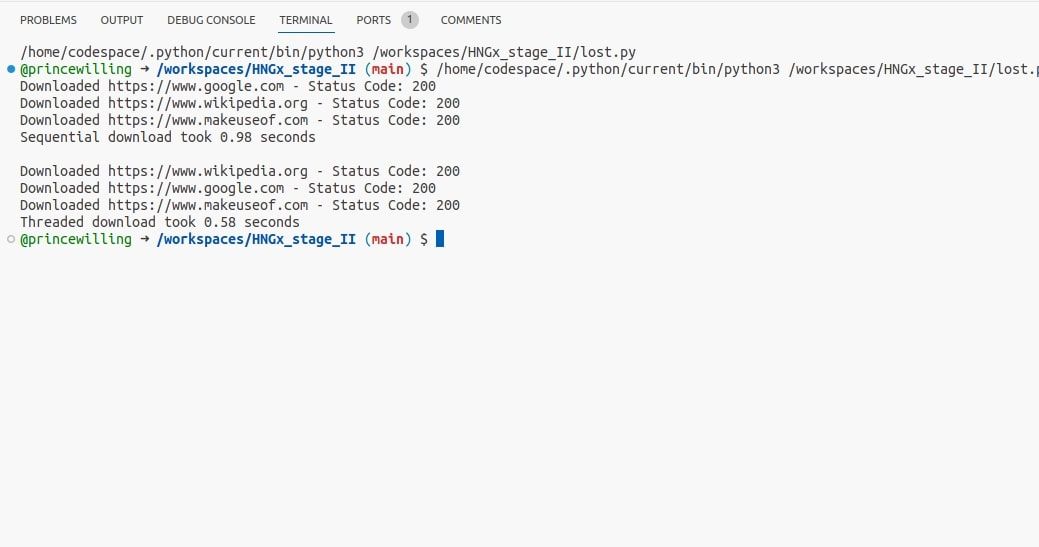
Пример: многопоточная загрузка URL (код сохранён, комментарии переведены):
import requests
import time
import threading
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# функция для запроса URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
# Запуск без потоков и измерение времени
start_time = time.time()
for url in urls:
download_url(url)
end_time = time.time()
print(f"Sequential download took {end_time - start_time:.2f} seconds\n")
# Запуск с потоками, сброс времени для нового измерения
start_time = time.time()
threads = []
for url in urls:
thread = threading.Thread(target=download_url, args=(url,))
thread.start()
threads.append(thread)
# Ожидание завершения всех потоков
for thread in threads:
thread.join()
end_time = time.time()
print(f"Threaded download took {end_time - start_time:.2f} seconds")Важно: в продакшене для сетевых запросов чаще используют либо неперебивающийся пул соединений, либо полностью асинхронный подход на aiohttp.
Асинхронность с asyncio
asyncio предоставляет цикл событий и сопрограммы (coroutine) — функции, которые можно приостанавливать и возобновлять. Асинхронный код не создаёт ОС‑потоки по умолчанию: он эффективно планирует переключения внутри одного потока, поэтому идеально подходит для большого числа одновременных I/O‑операций.
Плюсы:
- Очень экономичен по памяти при тысячах соединений.
- Контролируемая модель планирования и отмены задач.
Минусы:
- Требует асинхронных библиотек (например, aiohttp вместо requests).
- Крутая кривая изучения для начинающих; смешивание sync/async требует осторожности.
Асинхронный пример (оригинальный пример переведён комментариями):
import asyncio
import aiohttp
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# асинхронная функция для запроса URL
async def download_url(url):
async with aiohttp.ClientSession() as session:
async with session.get(url) as response:
content = await response.text()
print(f"Downloaded {url} - Status Code: {response.status}")
# Главная асинхронная функция
async def main():
# Создаём список задач для конкурентной загрузки
tasks = [download_url(url) for url in urls]
# Собираем и выполняем задачи одновременно
await asyncio.gather(*tasks)
start_time = time.time()
# Запускаем главный цикл
asyncio.run(main())
end_time = time.time()
print(f"Asyncio download took {end_time - start_time:.2f} seconds")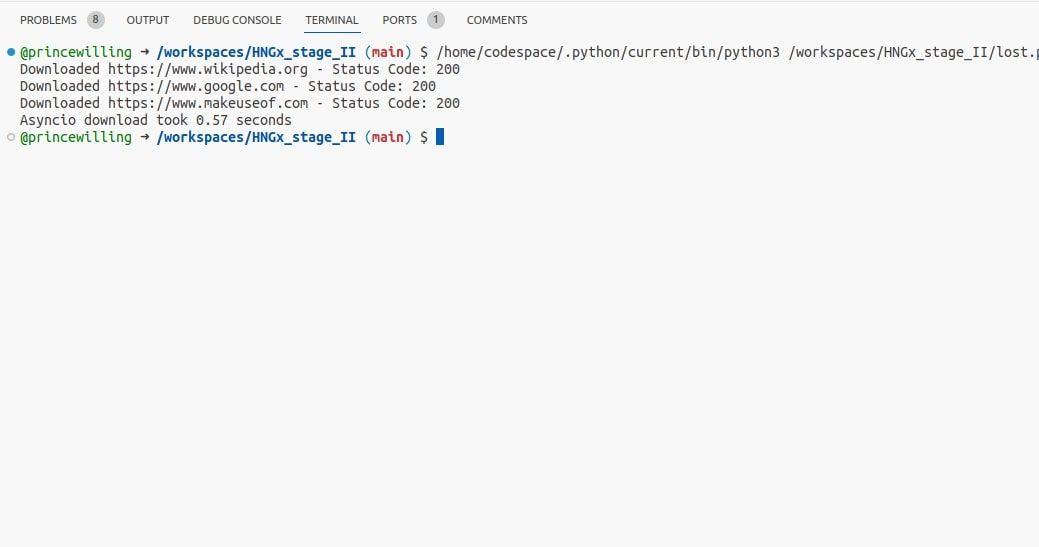
Когда выбирать asyncio:
- Серверы с большим количеством одновременных соединений (веб‑сервисы, прокси, веб‑скрейпинг).
- Клиенты, которые выполняют много сетевых запросов с ожиданием.
Когда использовать потоки вместо asyncio:
- Когда вы вынуждены пользоваться синхронными библиотеками, которые сложно заменить.
- Когда простота реализации важнее максимальной масштабируемости.
Параллелизм в Python
Параллелизм достигается через создание отдельных процессов: каждый процесс имеет свой интерпретатор Python и память, что обходит GIL и позволяет выполнять CPU‑интенсивные задачи одновременно.
multiprocessing
Модуль multiprocessing создаёт процессы, которые могут работать параллельно. Это полезно для алгоритмов, требующих высокой производительности на числах, больших циклов или сложных вычислений.
Плюсы:
- Полноценный параллелизм для CPU‑bound задач.
- Изоляция памяти между процессами повышает устойчивость системы (ошибка в одном процессе обычно не ломает другие).
Минусы:
- Высокая стоимость создания процессов и обмена данными между ними (serialization/pickling).
- Требует явного проектирования обмена данными (очереди, пайпы, shared memory).
Пример (код адаптирован с переводом комментариев):
import requests
import multiprocessing
import time
urls = [
'https://www.google.com',
'https://www.wikipedia.org',
'https://www.makeuseof.com',
]
# функция для запроса URL
def download_url(url):
response = requests.get(url)
print(f"Downloaded {url} - Status Code: {response.status_code}")
def main():
# Создаём пул процессов с количеством процессов, равным длине списка URL
num_processes = len(urls)
pool = multiprocessing.Pool(processes=num_processes)
start_time = time.time()
pool.map(download_url, urls)
end_time = time.time()
# Закрываем пул и ждём завершения
pool.close()
pool.join()
print(f"Multiprocessing download took {end_time-start_time:.2f} seconds")
if __name__ == '__main__':
main()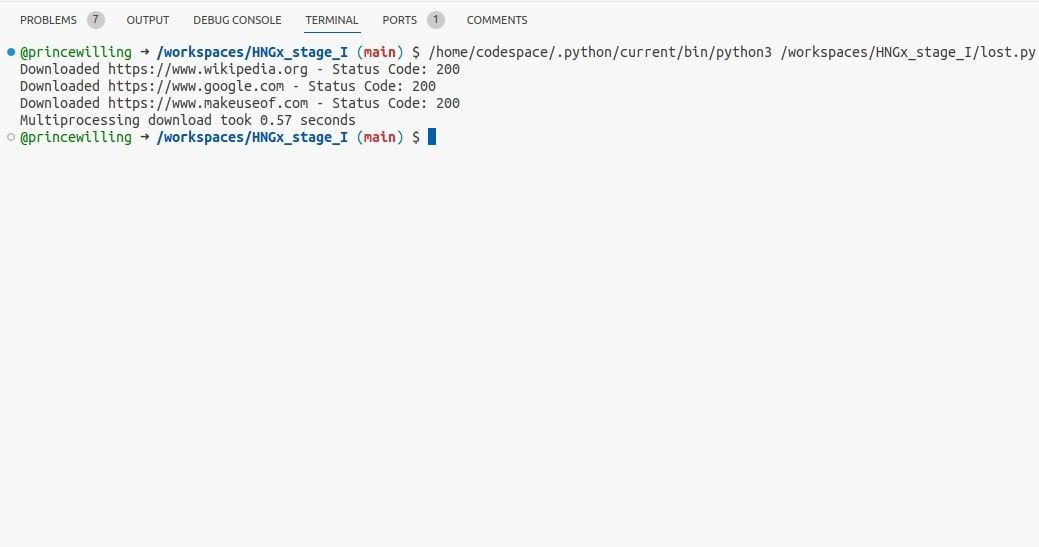
Советы по multiprocessing:
- Для больших наборов данных используйте shared memory (multiprocessing.shared_memory) или batching, чтобы снизить накладные расходы сериализации.
- На Windows защищайте точку входа через if name == ‘main‘.
Когда выбирать конкурентность, а когда параллелизм
Критерии выбора:
- Если задача I/O‑bound (сеть, диск, БД): выбирайте asyncio или потоки.
- Если задача CPU‑bound (наука о данных, обработка изображений): выбирайте multiprocessing или внешние нативные библиотеки (NumPy, Numba, C‑расширения).
- Если нужна лёгкая модель и разделяемая память — потоки, но помните про GIL.
- Если важна изоляция и отказоустойчивость — процессы.
Краткое правило: I/O → async/threads; CPU → processes / нативные библиотеки.
Дерево решений (Mermaid)
flowchart TD
A[Начало: у вас есть задача] --> B{Задача I/O или CPU?}
B -->|I/O-bound| C{Нужно ли поддерживать тысячи соединений?}
C -->|Да| D[Используйте asyncio и aiohttp]
C -->|Нет| E[Рассмотрите потоки 'threading' или asyncio]
B -->|CPU-bound| F{Можно ли использовать нативные библиотеки?}
F -->|Да| G[Используйте NumPy/С‑расширения/BLAS]
F -->|Нет| H[Используйте multiprocessing или внешние процессы]
D --> I[Добавьте мониторинг, таймауты и ограничение консьюмеров]
H --> J[Оптимизируйте обмен данными 'shared memory, batching']Чек‑листы по ролям
Разработчик бекенда:
- Оцените, I/O‑bound или CPU‑bound задача.
- Выберите asyncio для большого числа соединений; threading для простых сценариев; multiprocessing для вычислений.
- Добавьте таймауты и ограничения консьюмеров.
- Логируйте и обрабатывайте исключения процессов/потоков.
Инженер по производительности:
- Измерьте SLI/SLO: время отклика, пропускную способность.
- Профилируйте CPU и I/O (perf, py-spy, iostat).
- Тестируйте с realistic нагрузкой (locust, wrk).
- Оцените overhead сериализации при multiprocessing.
Операционная команда:
- Настройте мониторинг процессов и очередей.
- Ограничьте ресурсы через cgroups или systemd.
- Планируйте ауто‑скейлинг для сервисов с асинхронной нагрузкой.
Мини‑методология для внедрения
- Начните с измерения текущей реализации (профилирование).
- Определите тип нагрузки: I/O vs CPU.
- Выберите стратегию: async, threads, processes или гибрид.
- Реализуйте прототип и протестируйте на похожей нагрузке.
- Проанализируйте результаты: latency, throughput, memory.
- Итерируйте и внедряйте с мониторингом и тревогами.
Примеры, когда подходы не работают (контрпримеры)
- Потоки не ускорят вычисления, интенсивно использующие CPU, из‑за GIL.
- Asyncio не даст прироста, если используемые библиотеки являются блокирующими и не имеют асинхронных альтернатив.
- Multiprocessing может оказаться медленнее, если обмен данными между процессами происходит слишком часто и объёмно.
Советы по безопасности и приватности
- В сетевых клиентах/серверах обязательно лимитируйте максимальное количество одновременных соединений и вводите таймауты, чтобы избежать исчерпания ресурсов.
- При разделении работы между процессами будьте осторожны с секретами в памяти: процессы копируют память, поэтому менеджмент секретов должен быть централизованным.
- Для обработки персональных данных соблюдайте принципы минимизации: не держите лишние копии данных в нескольких процессах одновременно.
Совместимость и миграция
- При миграции с синхронного requests на aiohttp планируйте рефакторинг контроллера и обработку ошибок: API разные.
- При переходе на multiprocessing учтите поведение на Windows (if name == ‘main‘) и overhead сериализации.
- Рассмотрите сторонние решения: Celery для фоновых задач (использует процессы/воркеры), Dask для параллельных вычислений на кластерах.
Факто‑бокс: ключевые понятия
- GIL — глобальная блокировка интерпретатора CPython, которая ограничивает одновременное выполнение байткода потоками.
- Coroutine — управляемая функция, которую можно приостанавливать и возобновлять (async/await).
- Process — отдельный интерпретатор и адресное пространство, дающий настоящий параллелизм.
- I/O‑bound — операции, ограниченные вводом/выводом (сеть, диск).
- CPU‑bound — операции, нагружающие процессор (численные расчёты, шифрование).
Критерии приёмки
- Для I/O‑bound сервиса: среднее время отклика уменьшилось или пропускная способность увеличилась при нагрузочном тесте.
- Для CPU‑bound задачи: время выполнения в production‑кейсе уменьшилось при параллелизации с приемлемым ростом потребления памяти.
- Система устойчива к отказам: падение одного worker/process не приводит к отказу всего сервиса.
Заключение
Конкурентность и параллелизм — не взаимоисключающие подходы, а инструменты для разных проблем. Понимание характера задачи (I/O vs CPU), накладных расходов (создание процессов, сериализация) и требований к отказоустойчивости позволит выбрать правильную архитектуру. В большинстве случаев стоит начать с измерения и простого прототипа и затем масштабировать подход по мере необходимости.
Важно:
- Всегда профилируйте и измеряйте до оптимизации.
- Не смешивайте подходы без явной необходимости — это усложняет поддержку.
- Документируйте выбранную модель и ограничения для команды.
Короткая сводка:
- Конкурентность = одновременное управление задачами (async/threads).
- Параллелизм = одновременное выполнение на ядрах (multiprocessing).
- Выбор зависит от типа задачи и эксплуатационных требований.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
