DFD: как создать диаграмму потока данных

Зачем нужна диаграмма потока данных
DFD — это читаемая схема, показывающая источники данных, процессы, хранилища и пути передачи данных между ними. Она помогает:
- выявить узкие места и дублирование данных;
- оценить области для автоматизации и экономии;
- подготовить технические и юридические требования (например, соответствие законам о защите данных);
- наладить коммуникацию между бизнесом и разработкой.
Краткое определение: диаграмма потока данных — графическое представление движения и преобразований данных внутри системы.
Important: DFD показывает логику передачи и преобразования данных, но обычно не отражает реализационные детали (структуру БД, API-эндпоинты, схемы развертывания).
Основные обозначения диаграммы потока данных
Нотация DFD зависит от выбранного стандарта. На практике чаще используются Yourdon&Coad (процессы — круги) и Gane&Sarson (процессы — прямоугольники со скруглёнными углами). Важно выбрать одну нотацию и придерживаться её на протяжении всей документации.
Обязательные компоненты DFD:
- Стрелки: показывают направление движения данных между элементами.
- Процессы: выполняют преобразование данных — логика, вычисления или бизнес-правила. Каждому процессу даётся короткое имя.
- Хранилища данных: места, где данные сохраняются и откуда они могут читаться (файлы, таблицы, очереди). В нотации это обычно прямоугольник с одной или двумя вертикальными линиями.
- Внешние сущности: источники/потребители данных за пределами системы (пользователи, другие сервисы, организации).
Совет по именованию: используйте глагол + объект для процессов («Обработать заказ», «Генерировать отчёт»). Для потоков — существительное или фраза «Заказ клиента», «Инвентарные данные».
Уровни DFD и когда какой использовать
- Контекстная диаграмма (Level 0): глобальная схема системы как один процесс с внешними сущностями и основными потоками. Полезна для обсуждения с руководством и стейкхолдерами.
- Уровень 1: разбиение контекстного процесса на 3–9 основных подпроцессов. Подходит для архитектурного планирования.
- Уровень 2 и далее: детализированное декомпозирование сложных процессов.
Правило: не дробите процессы чрезмерно — если подпроцесс становится слишком сложным, перенесите его в отдельный уровень.
Пошаговое руководство: как построить DFD (на примере приложения доставки еды)
Ниже — расширенная, практичная пошаговая инструкция. В примере использованы приёмы, которые применимы в LucidChart и в других онлайн-редакторах.
1. Подготовка: выясните границы и участников
Перед открытием редактора ответьте на вопросы:
- Что система делает в пределах этой диаграммы? (определите границы)
- Кто внешние сущности (пользователи, поставщики, платёжные шлюзы)?
- Какие ключевые данные проходят через систему (заказы, платежи, инвентарь)?
Запишите эти ответы короткими фразами — они помогут при именовании элементов.
2. Выберите шаблон или начните с нуля
Большинство инструментов предлагают шаблоны DFD и блок-схем. Шаблон экономит время, но если система уникальна, начните с контекстной диаграммы.
Пример действий в LucidChart:
- Зарегистрируйтесь в LucidChart.
- Создайте “Blank document” (Новый документ).
Совет: сохраняйте версии (версии документа или копии шаблона) перед крупными изменениями.
3. Настройка визуала и конвенций
Определите визуальные правила заранее и документируйте их: цвет для внешних сущностей, цвет для хранилищ, стиль стрелок для синхронных и асинхронных потоков.
Практический совет: используйте ограниченную палитру (3–5 цветов) и контрастный шрифт, чтобы диаграмма была читаемой при печати.
4. Добавьте внешние сущности
- Перетащите прямоугольник на холст.
- Подпишите как “Клиент”.
- Цветом отличайте пользователей от автоматических систем (платёжные шлюзы, поставщики).
5. Определите и добавьте процессы
Добавьте ключевые процессы: “Принятие заказа”, “Формирование заказа”, “Обновление инвентаря”, “Генерация отчёта”. Каждому процессу присвойте уникальный идентификатор (например, P1, P2).
Хорошая практика: ограничьте текст в названии процесса до 2–4 слов.
6. Добавьте хранилища данных
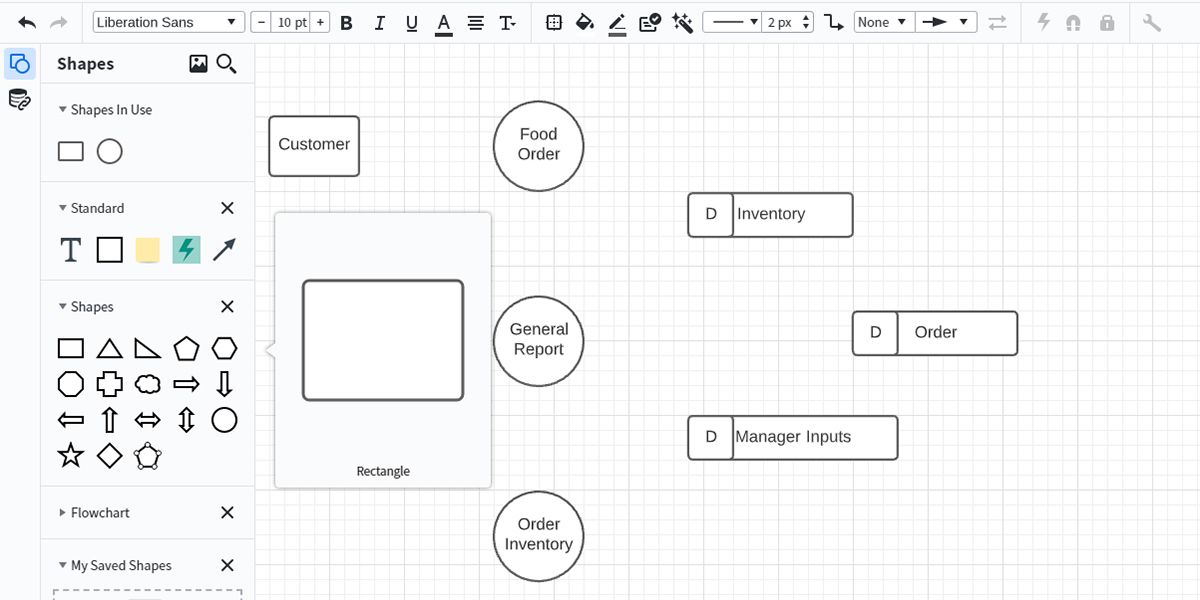
Хранилища часто обозначают как базы заказов, каталоги товаров, журналы аудита. Подписывайте тип хранилища и ключевые поля, например: OrderDB (order_id, customer_id, status).
Mini-методология для хранилищ:
- укажите формат хранения (таблица/файл/очередь);
- определите владельца данных;
- опишите правила жизни данных (retention, архивирование).
7. Соедините элементы потоками данных
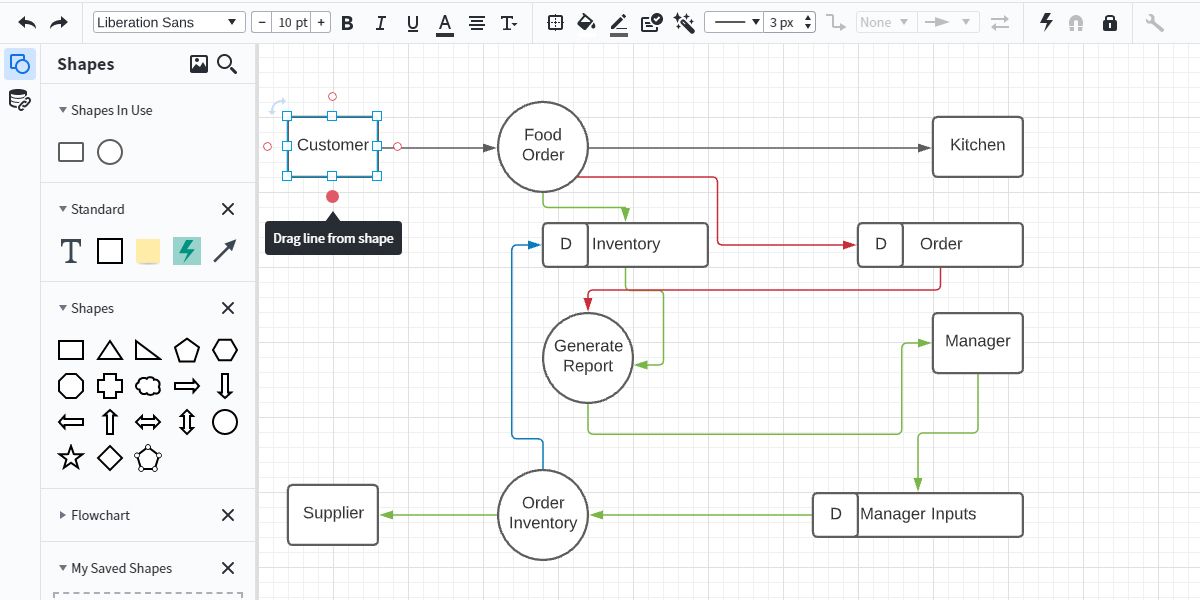
Используйте стрелки для связи сущностей, процессов и хранилищ. Подписывайте потоки понятными именами: “Детали заказа”, “Запрос проверки наличия”, “Результат отчёта”.
Совет: различайте типы потоков цветом или стилем линии (пунктир — асинхронные события, сплошная — запрос-ответ).
8. Подпишите потоки и добавьте атрибуты
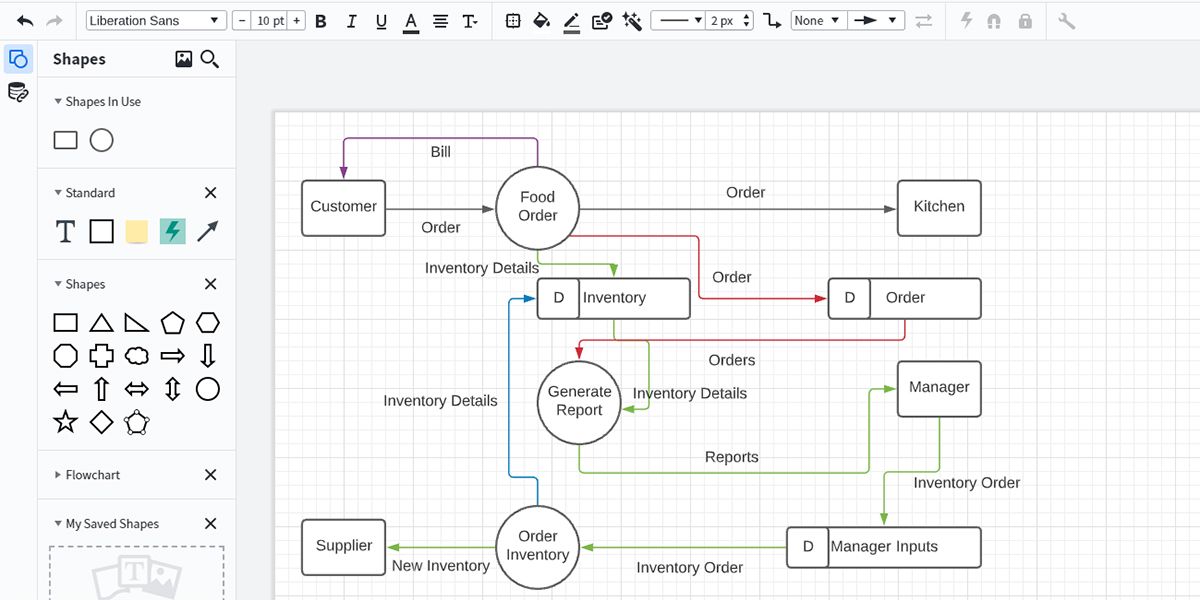
Каждый поток должен иметь краткое имя и, по возможности, структуру данных (например, order_id, items[], total_amount). Для сложных систем ведите отдельный data dictionary.
9. Оформите и отформатируйте диаграмму
Измените цвета, шрифты и толщину линий. Проверьте читаемость при масштабе 100% и при печати на листе A4.
Совет: используйте сетку и выравнивание, чтобы элементы выглядели упорядоченно.
10. Передайте и обсудите диаграмму с командой
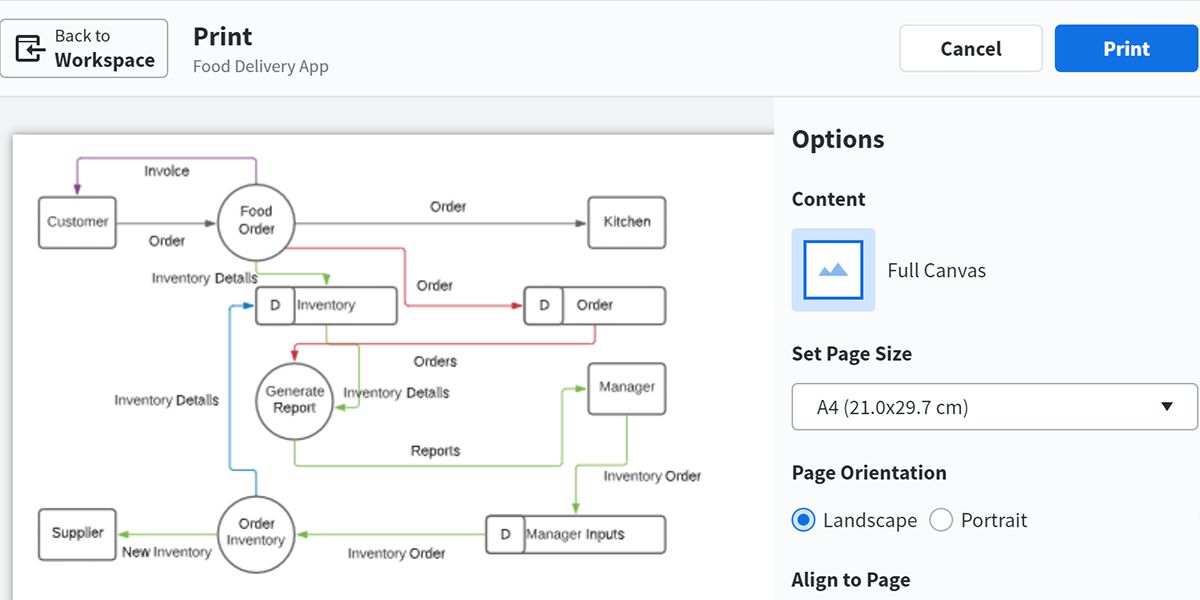
Чтобы распечатать: нажмите Ctrl+P или используйте команду “Print”.
Чтобы поделиться для совместной работы:
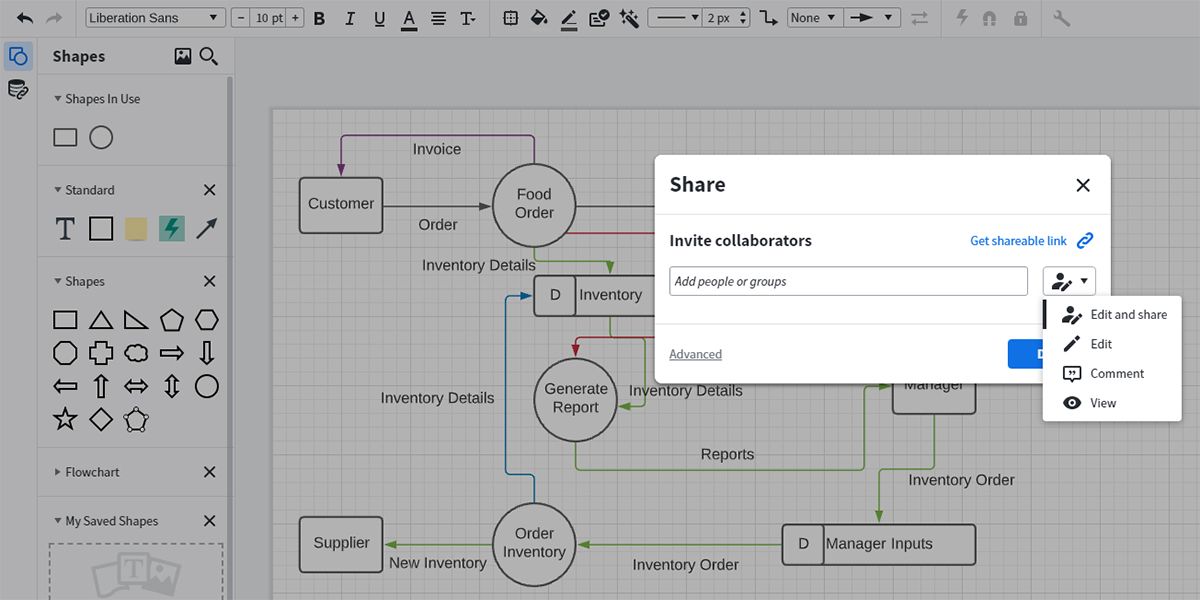
- Нажмите “Share”.
- Добавьте электронную почту коллеги.
- Выберите уровень доступа и отправьте приглашение.
Important: при совместной работе назначьте ревьюера, который будет утверждать изменения диаграммы.
Практические рекомендации по улучшению DFD
- Версионируйте диаграммы и храните историю изменений.
- Связывайте процессы с user stories или требованиями.
- Для сложных систем используйте нотацию уровней и отдельно документируйте data dictionary.
- Используйте идентификаторы процессов (P1, P2) и ссылочные теги для быстрой навигации.
Когда DFD не подходит и альтернативы
DFD полезен для представления потоков данных, но он не подходит, если нужно:
- показать поведение системы во времени (используйте диаграммы последовательностей UML);
- детализировать бизнес-процессы с ролями и задачами (используйте BPMN);
- отобразить структуру классов или БД (используйте ER-диаграммы или диаграммы классов).
Альтернативы:
- BPMN — для сложных бизнес-процессов и таскоров;
- UML Activity/Sequence — для сценариев и временных зависимостей;
- Flowchart — для простых алгоритмических последовательностей.
Ментальные модели и эвристики
- «Разделяй и властвуй»: начинайте с контекста, затем итерируйте на уровне 1 и далее.
- «Минимальный набор данных»: спрашивайте, какие минимальные поля нужны для процесса.
- «Владелец данных»: у каждого хранилища должен быть ответственный.
- «Паттерн трёх слоёв»: внешние сущности — процессы — хранилища.
Чек-листы и роли
Рекомендованные роли и их задачи при создании DFD:
- Продукт-менеджер: определяет границы, ключевые пользовательские сценарии.
- Системный архитектор: верифицирует целостность потоков, схема уровней.
- Разработчик: проверяет реализуемость, маппинг к API и БД.
- Специалист по безопасности/ДПО: проверяет приватность, шифрование и минимизацию данных.
- Тестировщик: составляет тест-кейсы по потокам данных.
Роль-based чек-лист (сокращённый):
- Продукт-менеджер: указаны все сценарии использования.
- Архитектор: нет циклических зависимостей между хранилищами.
- Разработчик: все потоки имеют формат и примеры.
- ДПО: отмечены персональные данные и меры защиты.
Критерии приёмки
- Контекстная диаграмма есть и утверждена стейкхолдерами.
- Уровень 1 покрывает ≥90% критичных сценариев (по согласованию).
- Все потоки имеют имена и краткое описание структуры.
- Для каждого хранилища указан владелец и требование по хранению данных.
- Отмечены потоки, содержащие персональные данные, и меры защиты.
Тестовые сценарии и приёмочные тесты
Примеры тест-кейсов, которые можно выстроить по DFD:
- Путь «Клиент → Принятие заказа → OrderDB»: проверьте, что при создании заказа появляются все обязательные поля.
- Путь «Принятие заказа → Генерация отчёта»: убедитесь, что отчёт включает только агрегированные данные, если требуется анонимизация.
- Отказ внешней сущности: симулируйте недоступность поставщика и проверьте обработку ошибок.
Критерии приёмки для тест-кейса: ожидаемые поля, формат ответа, поведение при ошибке.
Безопасность, конфиденциальность и соответствие
- Маркируйте потоки, содержащие персональные данные (PII) и финансовую информацию.
- Для таких потоков укажите метод защиты: TLS, шифрование на уровне поля, токенизация.
- Определите retention-политику для каждого хранилища: как долго данные хранятся и кто имеет доступ.
- При работе с пользователями из ЕС проверьте требования GDPR: правовые основания обработки, права субъекта данных и механизмы удаления.
Privacy note: диаграмма сама по себе может содержать чувствительную информацию. Ограничьте доступ к документам DFD и храните их в защищённом репозитории.
Примеры типичных ошибок и как их избежать
- Слишком мелкая детализация в одном уровне — дробите на уровни.
- Отсутствие владельцев данных — назначьте ответственных.
- Неименованные потоки — подписывайте каждый поток, чтобы не было двусмысленностей.
- Запутанные пересечения линий — применяйте маршрутизацию и выравнивание.
Шаблон Data Dictionary (упрощённый)
| Имя поля | Тип | Описание | Примечания |
|---|---|---|---|
| order_id | string | Уникальный идентификатор заказа | генерируется системой |
| customer_id | string | Идентификатор клиента | ссылка на профиль клиента |
| items | array | Список товаров в заказе | массив объектов {id, qty, price} |
| total_amount | decimal | Итоговая сумма | валюта хранится отдельно |
Совет: храните Data Dictionary рядом с диаграммой и обновляйте его вместе с изменениями схемы.
Принятие решения: какой уровень DFD нужен
flowchart TD
A[Нужна ли общая картина для стейкхолдеров?] -->|Да| B[Контекстная диаграмма]
A -->|Нет| C[Нужна реализация/детали?]
C -->|Да| D[Уровень 1 и далее]
C -->|Нет| E[BPMN или последовательности]Миграция и совместимость
При переносе DFD между инструментами:
- экспортируйте в PDF/PNG для сохранения визуала;
- экспорт в XML/VDX/CSV полезен для автоматической миграции метаданных;
- проверяйте, что ссылки на внешние документы (data dictionary) остаются рабочими.
Краткое руководство по внедрению DFD в проект (SOP)
- Инициировать сессии discovery с продуктом и стейкхолдерами.
- Создать контекстную диаграмму и согласовать границы.
- Декомпозировать на уровень 1, описать ключевые потоки и хранилища.
- Провести review с архитектором и DPO.
- Версионировать и связать диаграмму с требованиями и тест-кейсами.
Короткий словарь
- Процесс — действие, преобразующее входные данные в выходные.
- Поток данных — передача данных между элементами.
- Хранилище — место, где данные сохраняются и откуда их берут.
- Внешняя сущность — внешний источник или потребитель данных.
Резюме
DFD — незаменимый инструмент для понимания того, как данные перемещаются в вашей системе. Он полезен для архитектурного планирования, оценки рисков, согласования с бизнесом и обеспечения соответствия требованиям приватности. Начните с контекстной диаграммы, постепенно декомпозируйте процессы, документируйте data dictionary и привязывайте диаграмму к тестам и требованиям.
Краткое действие: выберите шаблон в вашем редакторе, нарисуйте контекстную диаграмму за 15–30 минут и договоритесь о ревью со стейкхолдерами.
Summary:
- Определите границы и участников;
- Используйте удобную нотацию и придерживайтесь её;
- Подписывайте потоки и хранилища;
- Документируйте владельцев и политику хранения данных.
Short announcement: Создайте DFD для вашего проекта уже сегодня — это ускорит принятие архитектурных решений и уменьшит риски по безопасности данных.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
