Как копировать текст из PDF — простые способы на ПК
Быстрые ссылки
- Использовать Adobe Acrobat Reader DC для копирования текста из PDF
- Использовать Chrome, Firefox или Edge для копирования текста из PDF
Краткое описание
- Копирование текста из PDF выполняется в совместимом приложении: Acrobat Reader, Chrome, Edge, Firefox.
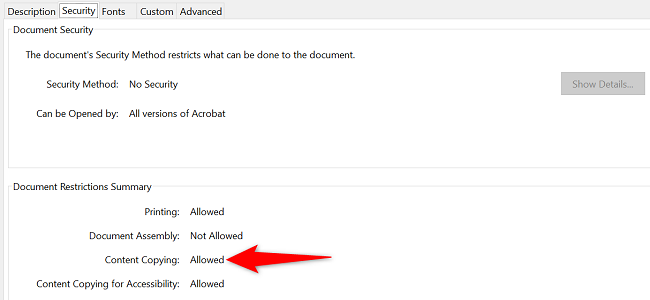
- Сначала проверьте разрешения документа: Файл > Свойства > Безопасность и посмотрите значение «Копирование содержимого». Если указано «Не разрешено», прямое копирование невозможно.
- Если копирование разрешено, выберите инструмент выделения и используйте контекстное меню или сочетание клавиш для копирования.
Копировать текст из PDF просто: откройте документ в соответствующем приложении, выделите нужный фрагмент и выполните команду копирования. Ниже приведены пошаговые инструкции для Adobe Acrobat Reader DC и популярных браузеров, а также альтернативы и сценарии, когда прямое копирование не работает.
Используйте Adobe Acrobat Reader DC для копирования текста из PDF
Чтобы воспользоваться этим способом, скачайте и установите бесплатный Adobe Acrobat Reader DC на компьютер. Затем проверьте, разрешено ли копирование в самом PDF, и если разрешено — скопируйте текст.
Проверка, разрешено ли копирование содержимого PDF
- Откройте PDF в приложении Acrobat Reader DC.
- Не все PDF позволяют копировать текст. Если файл защищён, придётся прибегнуть к другим методам: сделать скриншот и применить OCR или открыть в браузере и попробовать «соскрести» текст.
- В строке меню Acrobat Reader выберите Файл > Свойства.
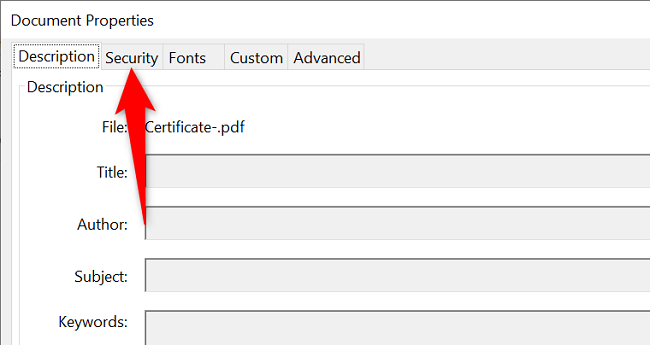
- В окне «Свойства документа» перейдите на вкладку Безопасность.
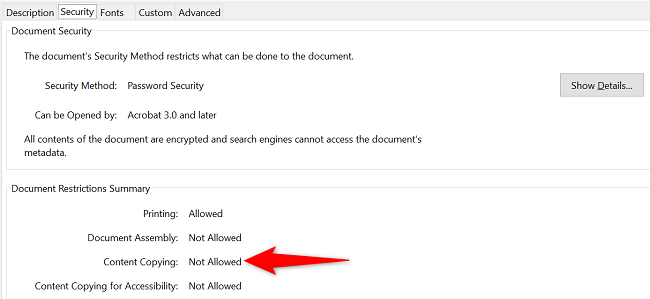
- Найдите значение рядом с «Копирование содержимого». Если написано «Не разрешено», вы не сможете напрямую копировать текст из этого PDF.
- Если указано «Разрешено», переходите к разделу ниже, чтобы выполнить копирование.
Как скопировать текст в Acrobat Reader
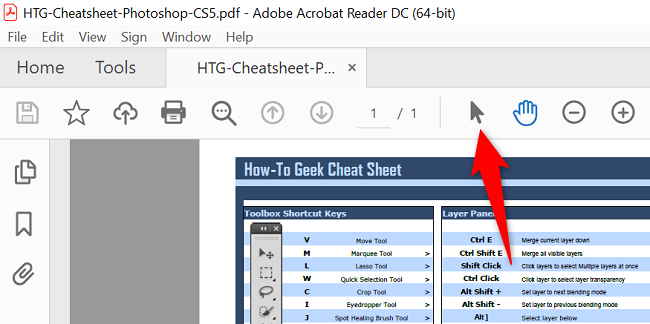
- Убедитесь, что документ открыт в Acrobat Reader.
- На верхней панели инструментов выберите Инструмент выделения (иконка стандартного курсора).
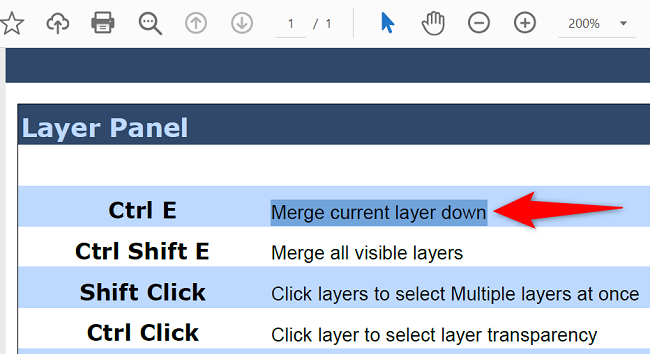
- Найдите фрагмент текста, который нужно скопировать. Выделите его курсором.
- Щёлкните по выделенному фрагменту правой кнопкой мыши и выберите Копировать.
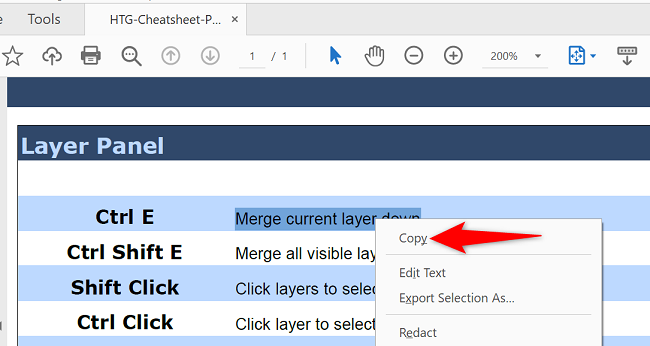
- Текст попадёт в буфер обмена. Вставьте его в текстовый редактор сочетанием Ctrl+V или через контекстное меню Вставить.
Важно: при копировании форматирование может не полностью соответствовать внешнему виду PDF — список, колонки и таблицы часто требуют дополнительной ручной правки.
Используйте Chrome, Firefox или Edge для копирования текста из PDF
Большинство браузеров поддерживают просмотр и копирование содержимого PDF. Ниже показан пример на Chrome, но шаги похожи в Edge и Firefox.
- Найдите PDF в проводнике, щёлкните правой кнопкой мыши и выберите Открыть с помощью > Google Chrome.
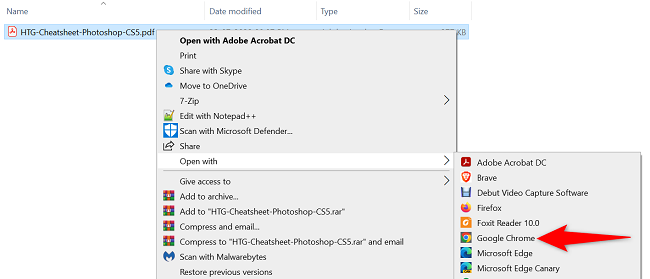
- Когда PDF откроется в браузере, выделите нужный фрагмент курсором.

- Нажмите правой кнопкой мыши по выделению и выберите Копировать.
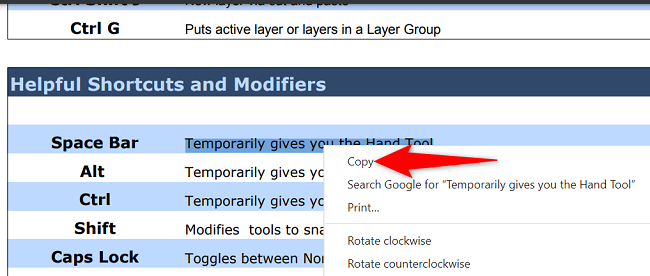
- Текст теперь в буфере обмена. Вставьте его туда, где нужно.
Примечание: встроенные просмотрщики браузеров иногда корректно обрабатывают только векторный/текстовый слой PDF. Если текст в документе — изображение (скан), браузер не выдаст текст при простом выделении.
Когда прямое копирование не работает
- Документ защищён паролем или имеет ограничения на копирование (в свойствах указано «Не разрешено»).
- PDF создан как изображение (скан или экспорт из графического редактора) без слоя текста.
- Текст зашифрован или использованы нестандартные шрифты, мешающие извлечению текста.
Важно: обходить защиту документов в обход авторских прав запрещено и может нарушать законодательство. Если вам нужен текст из защищённого файла, свяжитесь с автором или владельцем документа.
Альтернативные способы извлечения текста
- OCR из снимка экрана. Сделайте скриншот нужной страницы и пропустите изображение через программу с оптическим распознаванием текста (например, бесплатные онлайн-OCR, мобильные приложения или встроенные функции в просмотрщиках).
- Использовать специализированные утилиты для извлечения текста из PDF (PDFTextExtractors, командные утилиты, скрипты на Python с библиотеками pdfminer, PyPDF2 — для продвинутых пользователей).
- Экспорт в Word/текст из платных редакторов PDF (Adobe Acrobat Pro, другие коммерческие редакторы) — иногда экспорт точнее сохраняет структуру.
- Если PDF на веб‑странице, открыть страницу в режиме разработчика и посмотреть источник или сетевой трафик — иногда текст отдаётся в HTML.
Контрпример: OCR плохо работает с сильно искажёнными сканами или документами со сложной версткой (колонки, формулы). В таких случаях потребуется ручная корректировка.
Быстрый чек‑лист (для пользователя и администратора)
Пользователь:
- Откройте PDF в Acrobat Reader или браузере.
- Проверьте Свойства > Безопасность > Копирование содержимого.
- Если разрешено — выделите и скопируйте.
- Если нет — сделайте скриншот и примените OCR или запросите исходный файл.
Администратор/ИТ:
- Проверьте права доступа к файлу на сетевом диске.
- Если копирование требуется по рабочему процессу, запросите у автора версию без защиты.
- При массовой обработке используйте скрипты и OCR‑пул с очередью задач.
Малая методология для рабочих задач
- Оцените формат документа: текстовый слой или изображение.
- Если текстовый — попытайтесь копировать в Acrobat/браузере.
- Если защищён — запросите доступ или исходник.
- Если изображение — используйте OCR (выберите качественный движок, проверьте язык распознавания).
- Проверьте результат и поправьте форматирование.
Типичные ошибки и как их исправлять
- Проблема: при вставке теряется перенос строк и таблицы выглядят слитно. Решение: вставьте в текстовый редактор с поддержкой форматирования, затем вручную восстановите строки и столбцы.
- Проблема: вместо кириллицы вставляются кракозябры. Решение: проверьте кодировку и шрифты; при копировании из сканированного PDF используйте OCR с поддержкой русского языка.
- Проблема: документ защищён. Решение: свяжитесь с владельцем или используйте разрешённые пути — не пытайтесь взломать защиту.
Краткий словарь терминов
- PDF: переносимый формат документа.
- OCR: оптическое распознавание текста — превращает изображение в текст.
- Текстовый слой: слой в PDF, где символы представлены как текст, а не как изображение.
Краткое резюме
- Начните с проверки свойства «Копирование содержимого». Если разрешено, используйте инструмент выделения в Acrobat Reader или браузере.
- Если документ — изображение или защищён — примените OCR или попросите исходник.
- Для массовой автоматизации используйте скрипты и OCR‑пайплайн.
Важно: уважайте авторские права и правила безопасности. При сомнениях запросите разрешение у владельца документа.
Хотите редактировать PDF, чтобы внести изменения в текст или верстку? Существуют разные решения для ПК: от бесплатных конвертеров до платных редакторов, которые сохраняют форматирование и позволяют править исходный текст.
Похожие материалы

Discord не обновляется в Windows 10 — быстрые исправления

Экспорт контактов iPhone в Windows 10

Тыловые 5.1 колонки не работают после Windows 10

Как недорого работать в дороге — гаджеты и планы

Где находятся файлы конфигурации Apache