Как извлечь текст из PDF на Mac с помощью PDFelement и OCR
Важно: бесплатная пробная версия ограничивает работу с OCR (максимум 3 страницы, водяной знак, без сохранения качества). Для полноценной работы потребуется PDFelement Pro.
О чём эта статья
В этой статье мы подробно разберём, что такое OCR в контексте PDF, почему OCR в PDFelement полезен, как быстро выполнить распознавание текста на Mac и какие есть практические советы, проверки качества и альтернативы. В конце — чек‑листы для разных ролей, мини‑методология и ответы на частые вопросы.
Что такое PDFelement?
PDFelement — кроссплатформенный набор инструментов для работы с PDF от Wondershare. Он позволяет редактировать, конвертировать, подписывать и защищать PDF на настольных компьютерах, мобильных устройствах и через веб. В версии PDFelement9 добавлены обновлённый интерфейс, облачное управление документами, ускоренная загрузка и функция машинного перевода документов.
Что такое OCR и почему это важно?
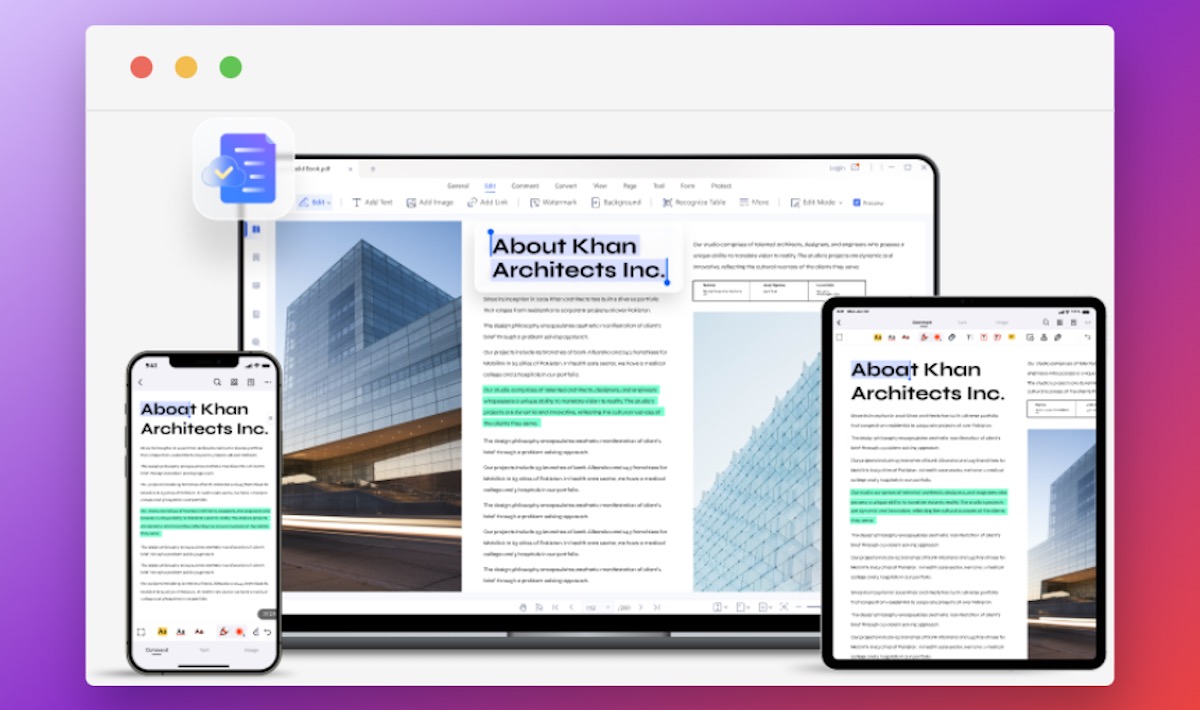
OCR (оптическое распознавание символов) — технология, которая распознаёт текст на изображении и преобразует его в машиночитаемый формат. Коротко: OCR избавляет от ручного набора текста и делает документ редактируемым и поисковым.
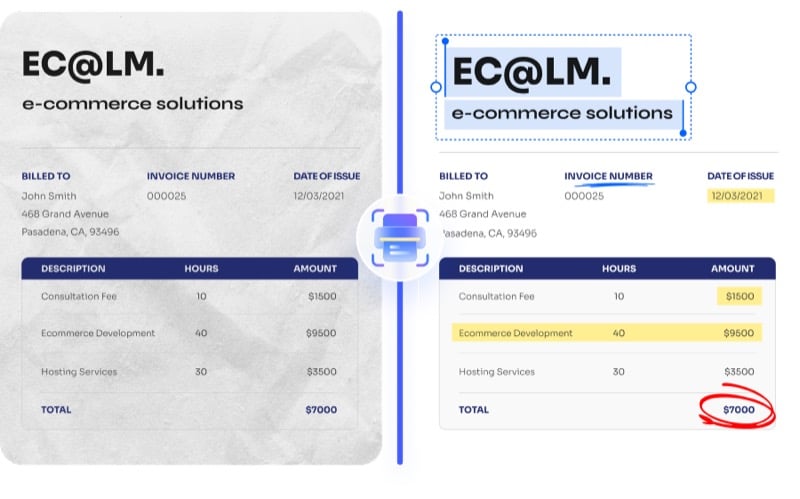
Преимущества корректной реализации OCR в PDF‑редакторе:
- сохранение исходной верстки (заголовки, сноски, графика);
- пакетная обработка нескольких файлов;
- поддержка множества языков (в PDFelement заявлено более 20 языков);
- экономия времени и снижение числа опечаток, присущих ручному вводу.
Когда OCR особенно полезен
- у вас бумажные документы, отсканированные в PDF;
- нужно извлечь текст из скриншотов или фотографий;
- требуется сделать длинные архивы документов поисковыми.
Что PDFelement делает иначе
PDFelement подчёркивает сохранение макета при распознавании: текст получает форматирование и размещается в тех же блоках, что и в оригинале, что сокращает ручную правку после конверсии.
Практическое руководство: как выполнить OCR на Mac (пошагово)
Подготовка
- Скачайте и установите PDFelement9 для Mac с официального сайта Wondershare. Откройте DMG и следуйте подсказкам установщика.
- После установки запустите PDFelement и установите необходимые плагины (PDF Converter и OCR). Без них распознавание не будет работать.
Установка плагинов
- Запустите PDFelement на Mac.
- В строке меню выберите PDFelement → “Настройки”.
- Перейдите в раздел “Плагины”.
- Нажмите кнопку “Загрузить” рядом с PDF Converter и OCR.
Выполнение OCR
- В основном окне PDFelement нажмите “Открыть” и выберите отсканированный PDF или изображение. Также можно перетащить файл в окно приложения.
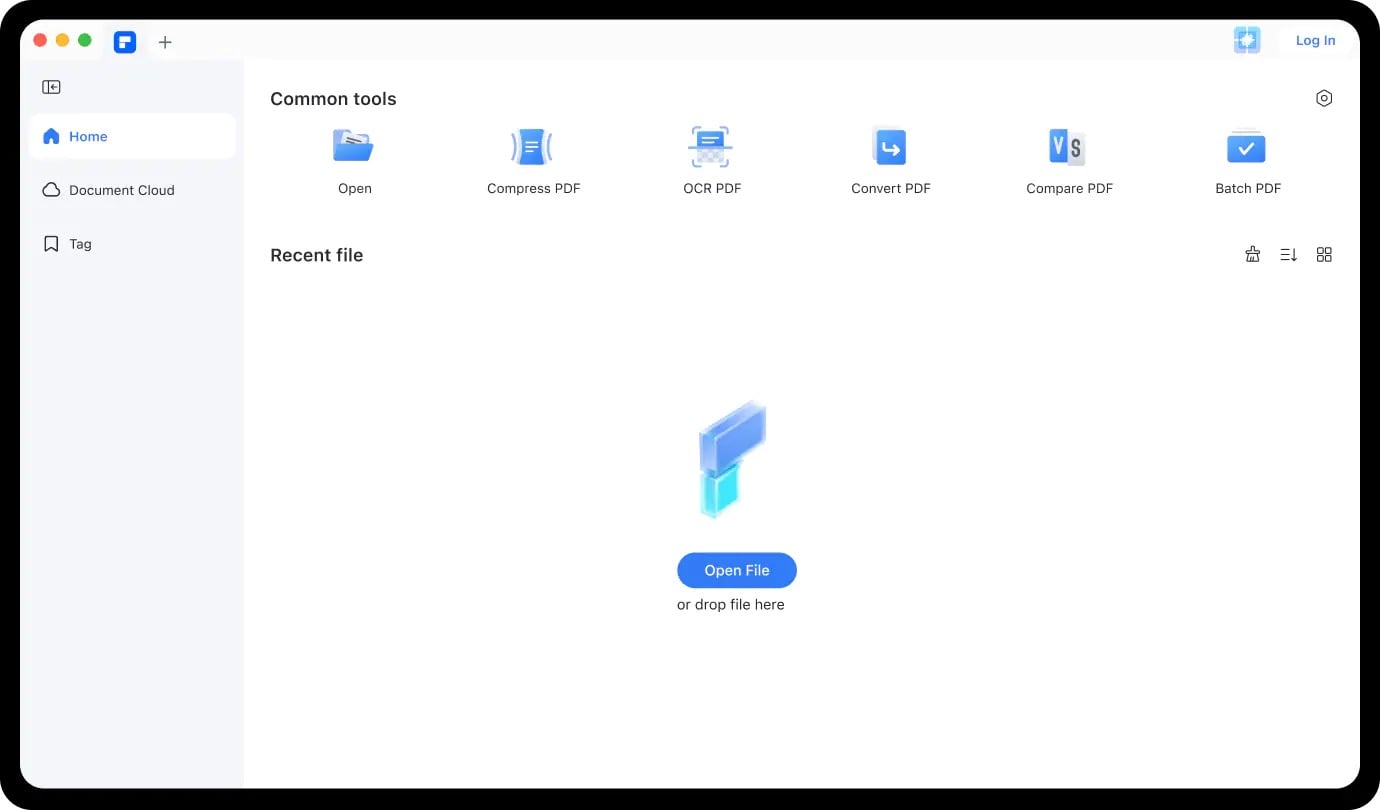
- В верхнем меню выберите “Инструменты” и затем “Распознавание текста (OCR)”.
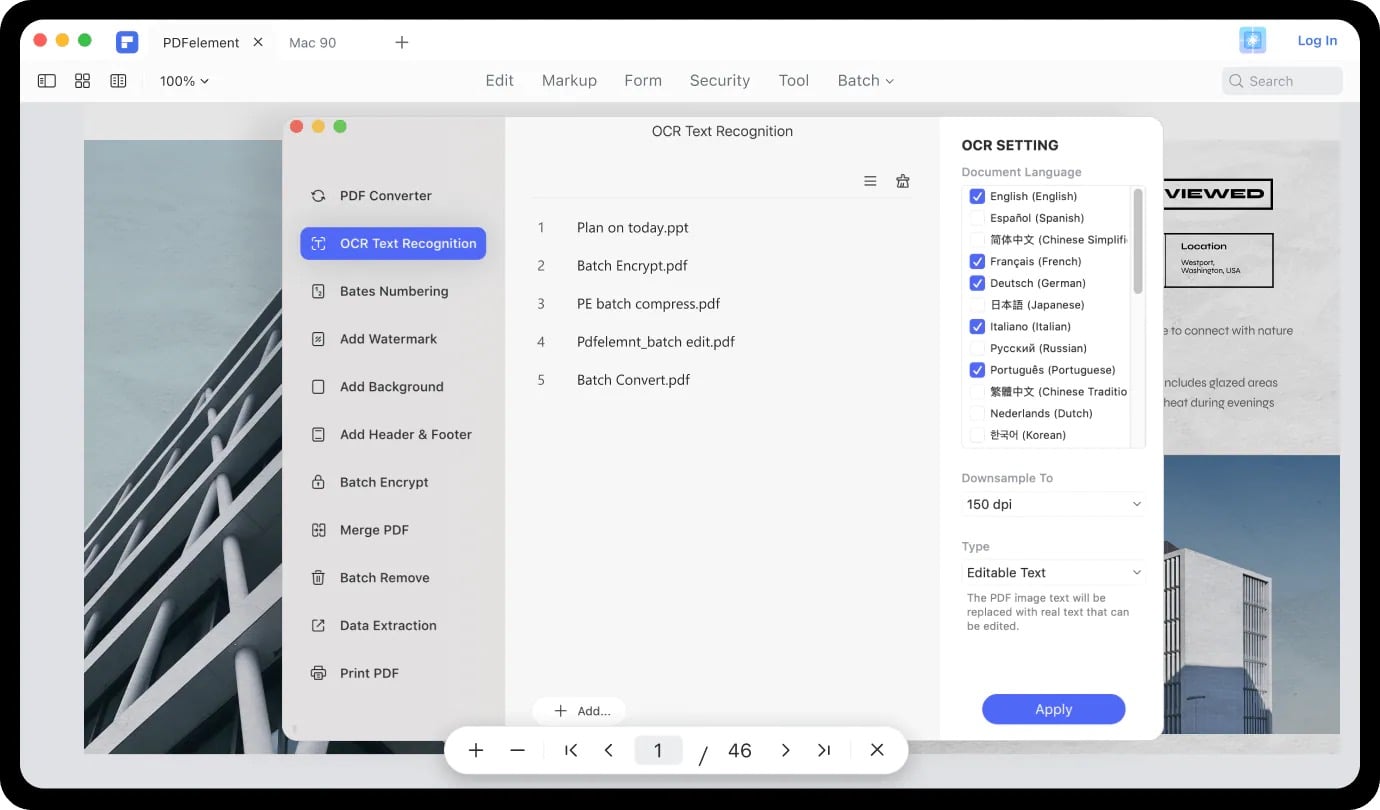
- В окне распознавания текста укажите язык документа, диапазон страниц, тип документа (например, “Редактируемый текст” или “Поисковый и редактируемый”), а также настройки сжатия/понижения разрешения при необходимости.
- Нажмите “Выполнить OCR” и дождитесь завершения. Время обработки зависит от размера и сложности PDF.
- После завершения перейдите на вкладку “Правка” и внесите нужные изменения в распознанный текст.
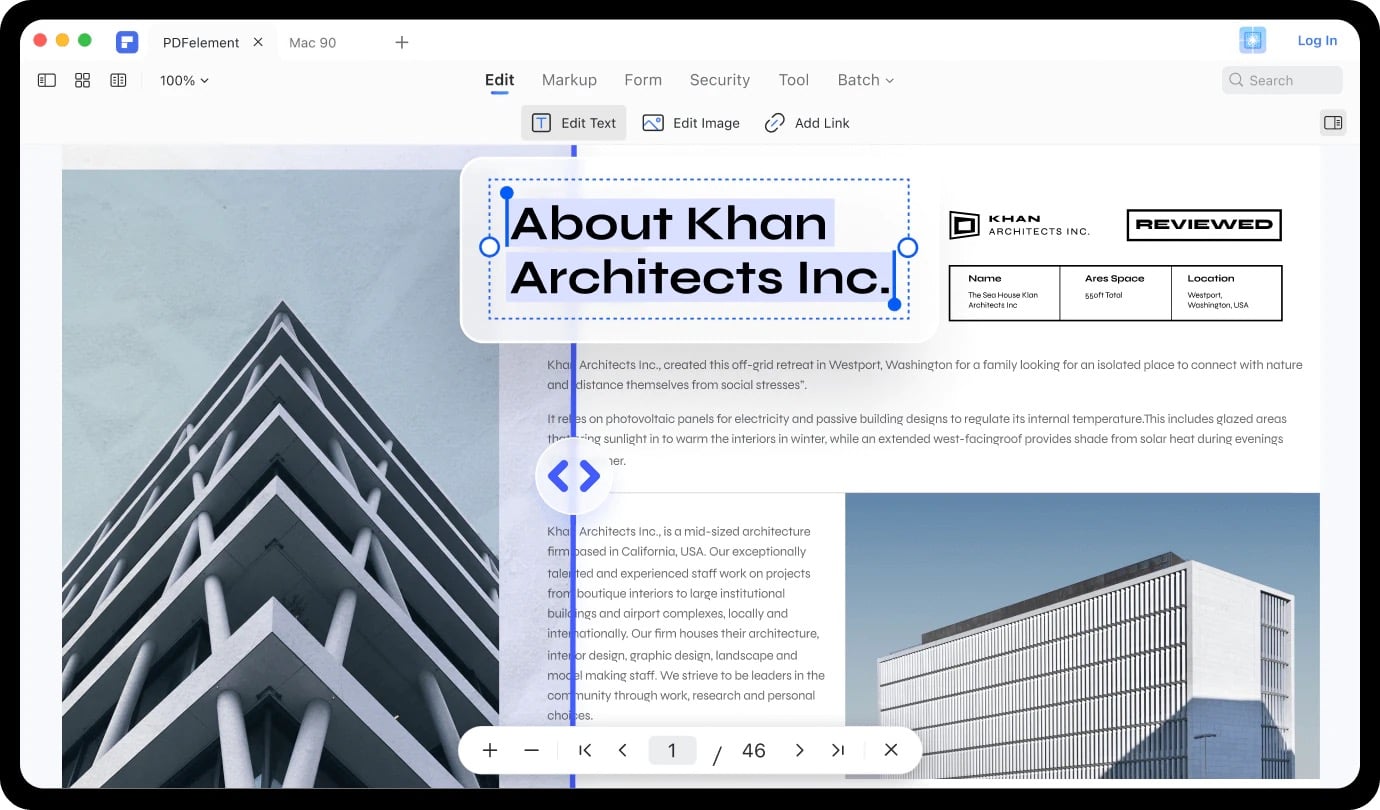
- Сохраните документ: Файл → Сохранить. Обратите внимание: бесплатная версия не даёт полного сохранения без водяных знаков и других ограничений.
Полезные советы и проверки качества (QA)
Чек‑лист перед запуском OCR
- качество скана: 300 dpi или выше — оптимально для печатного текста;
- отсутствие сильных теней и перекосов страницы;
- для многоязычных документов укажите все используемые языки при распознавании.
Критерии приёмки (минимум)
- текст можно выделять и копировать;
- структура документа (заголовки, подписи, таблицы) сохранена без значительных искажений;
- поиск по ключевым словам возвращает релевантные результаты;
- водяные знаки и метки видны только там, где это ожидаемо (пробная версия).
Тесты/кейсы для проверки результата OCR
- Открыть PDF и выполнить поиск по трём уникальным словам из разных частей документа;
- Скопировать часть таблицы и вставить в текстовый редактор — проверить соответствие;
- Сравнить количество страниц и визуально сравнить важные блоки оформления.
Мини‑методология: процесс OCR для команд
- Подготовка сканов (сканирование → коррекция яркости/контраста → выравнивание страниц).
- Импорт в PDFelement → пакетная обработка OCR.
- Быстрая верификация ключевых страниц (вручную).
- Финальная правка и экспорт.
Эта простая методология помогает стандартизировать работу с большими архивами.
Ролевые чек‑листы
Для обычного пользователя (редактор/автор)
- проверить только несколько первых страниц после OCR;
- исправить явные опечатки и форматирование;
- сохранить в нужном формате (PDF/Word).
Для администратора IT
- убедиться, что установлены плагины и они обновлены;
- проверить политику конфиденциальности и где выполняется обработка (локально/облако);
- настроить лицензирование и централизованное обновление.
Для менеджера по документам
- задать стандарты сканирования (dpi, формат);
- определить правило, какие документы подлежат OCR;
- план контроля качества результатов.
Ограничения и случаи, когда OCR не подойдёт
- рукописный текст: большинство стандартных OCR‑движков с рукописью справляются плохо;
- сильно повреждённые или размазанные сканы — распознавание будет неточным;
- сложные диаграммы и специальное форматирование (например, музыкальные нотации) не всегда воспроизводятся корректно.
Альтернативные подходы
- если OCR даёт плохие результаты, рассмотрите ручной набор для критичных фрагментов;
- для больших массивов документов без доверия к облачным сервисам — выбирайте решения с гарантией локальной обработки;
- если форматирование критично, экспорт в Word + ручная верстка может быть быстрее.
Безопасность и конфиденциальность
Важно оценить, где выполняется OCR: локально на вашем Mac или в облаке у поставщика. Для конфиденциальных документов предпочтительна локальная обработка или проверка политики конфиденциальности и соглашения о защите данных. Если ваши документы подпадают под требования GDPR/локальных регламентов, согласуйте использование внешних сервисов с юридическим отделом.
Цена и ограничения пробной версии
PDFelement предлагает несколько планов для частных пользователей:
- Perpetual: $159
- Quarterly: $49
- Yearly: $129
Пробная версия доступна, но с ограничениями: OCR‑функциональность включена частично — максимум 3 страницы, сохранение с водяным знаком и без контроля качества страницы. Для полноценной работы рекомендуется подписка PDFelement Pro.
Сравнительная матрица (качественная)
| Параметр | Встроенный OCR в PDF‑редакторе | Внешний OCR‑сервис | Ручной ввод |
|---|---|---|---|
| Скорость обработки | высокая (если локально) | зависит от интернета | очень медленно |
| Сохранение верстки | обычно хорошее | может варьироваться | идеальная (если верстка делалась вручную) |
| Конфиденциальность | выше (при локальной обработке) | ниже (облачная обработка) | высокая |
| Стоимость | лицензия/подписка | подписка/плата за объём | высокая трудозатратность |
Ментальная модель: когда запускать OCR
- если текст нужно копировать или искать — OCR обязательна;
- если это единичная страница с рукописным текстом — сначала протестируйте на отрывке;
- если важна верстка — используйте инструменты, которые сохраняют макет.
Decision flowchart (краткое руководство выборa)
flowchart TD
A[Есть PDF или изображение?] --> B{Файл имеет печатный текст или рукопись?}
B -->|Печатный| C[Запустить OCR в PDFelement]
B -->|Рукопись| D[Оценить качество рукописи]
D -->|Хорошее| C
D -->|Плохое| E[Рассмотреть ручной ввод или доп. инструменты]
C --> F{Результат приемлем?}
F -->|Да| G[Сохранить и использовать]
F -->|Нет| E
E --> H[Корректировка → повторная обработка]Частые вопросы
Нужно ли платить за OCR в PDFelement?
Пробная версия включает ограниченный OCR (максимум 3 страницы, водяной знак, ограничения на сохранение). Для полноценного сохранения и управления качеством потребуется обновление до PDFelement Pro.
Поддерживает ли PDFelement несколько языков при распознавании?
Да — PDFelement поддерживает более 20 языков. При работе с многоязычными документами указывайте языки вручную для улучшения качества распознавания.
Можно ли автоматизировать пакетную обработку?
PDFelement поддерживает пакетную обработку OCR для нескольких файлов; удобнее выполнять пакетную конвертацию с подготовленными входными файлами.
Что делать, если текст после OCR содержит ошибки?
Проверьте исходное качество сканов (dpi, контраст), попробуйте другие языковые настройки, при необходимости вручную исправьте ключевые участки.
Заключение
OCR делает PDF документацию пригодной для поиска, редактирования и повторного использования. PDFelement предлагает встроенный OCR с удобным интерфейсом и сохранением верстки — это удобно для пользователей Mac. Для регулярной работы с большими объёмами документов обратите внимание на лицензию Pro и на политику конфиденциальности при обработке чувствительных данных.
Ключевые шаги: установить PDFelement → добавить плагины → запуск OCR → проверка и правка → сохранение под лицензией Pro.
Краткое резюме: PDFelement — практичное решение для большинства задач OCR на Mac; подходит для пользователей, которым важно сохранить верстку и ускорить обработку документов.
Похожие материалы
Как включить и отключить блокировщик всплывающих окон IE11

Применение патчей при перемещённых файлах в Git

Отключить загрузку запросов в Power BI

Как воспроизводить медиа на Smart TV

Как изменить размер изображения в Paint 3D
