Преобразование изображений в редактируемый текст в Microsoft Word

Если вы когда‑либо вручную перепечатывали текст с изображения или пытались преобразовать сканы в редактируемый документ, эта инструкция сэкономит вам время. Ниже — пошаговый гид по преобразованию любой картинки в редактируемый текст прямо в Microsoft Word, без дополнительных надстроек.
Шаг 1: Вставьте изображение в Microsoft Word
Откройте документ Word. Перетащите изображение в окно документа или перейдите на вкладку Вставка и выберите Рисунки → Это устройство. В русской версии Word пункты меню обычно называются «Вставка» и «Рисунки».
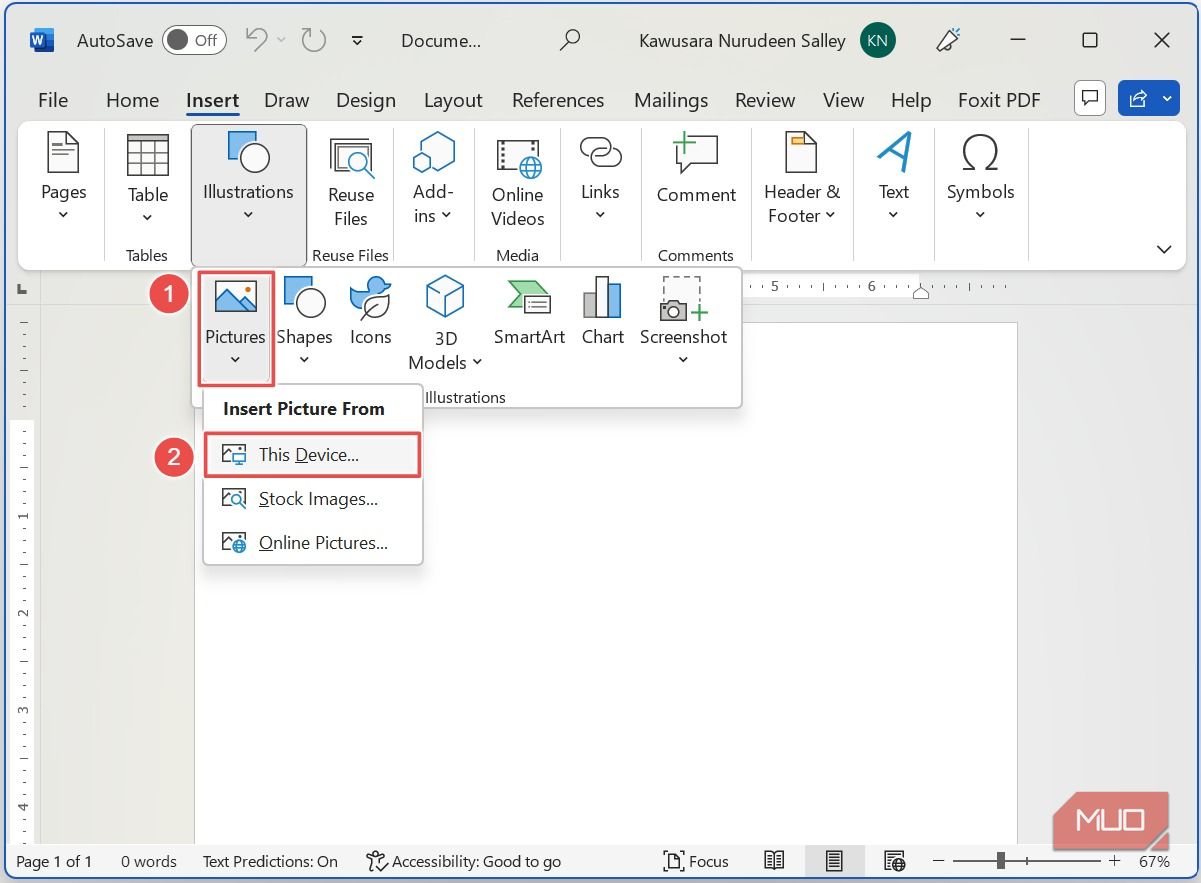
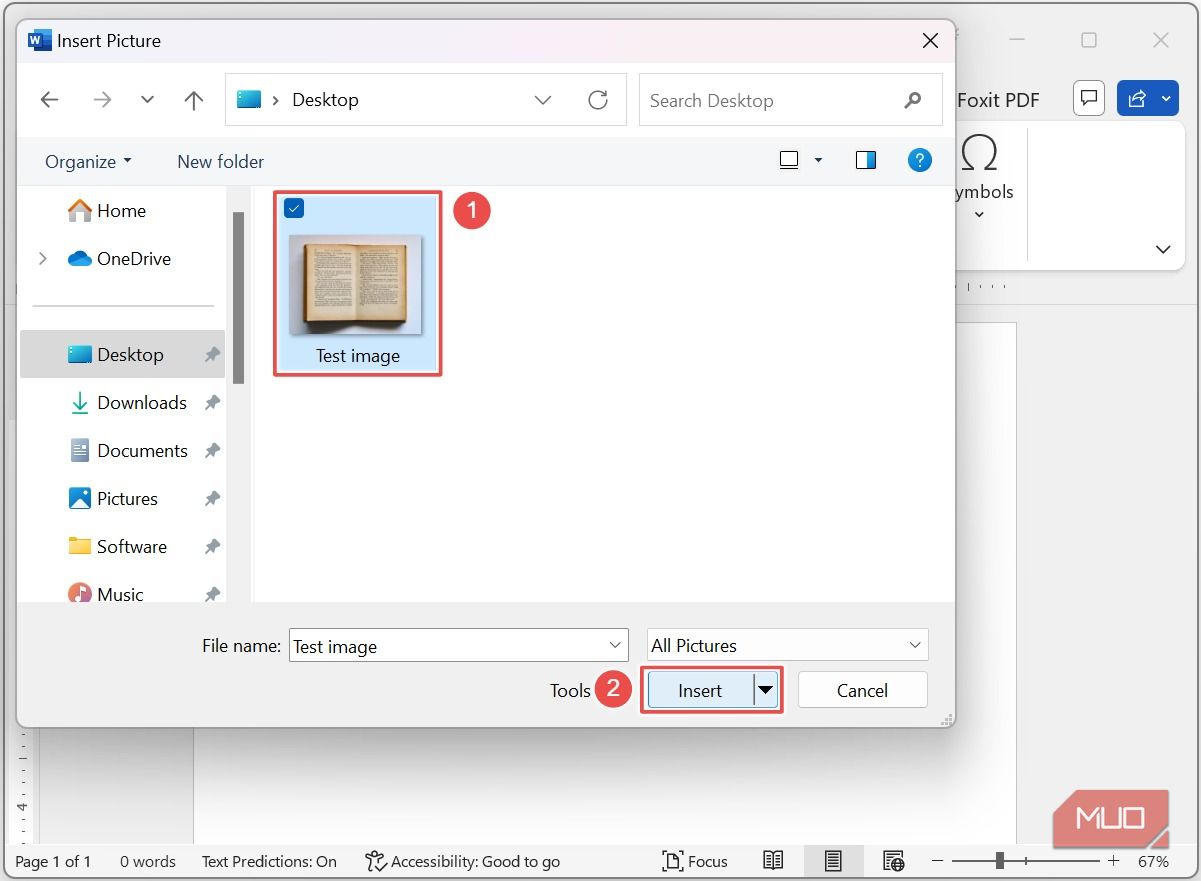
В проводнике выберите файл изображения и нажмите Вставить.
Если у вас ещё нет Microsoft Word, можно воспользоваться бесплатной версией Office в браузере, мобильными приложениями или одноразово установить полноценную настольную версию от Microsoft.
Шаг 2: При необходимости обрежьте и подгоните изображение по ширине страницы
Этот шаг необязателен, но часто улучшает качество распознавания текста.
- Правой кнопкой мыши кликните по изображению и выберите Обрезать.
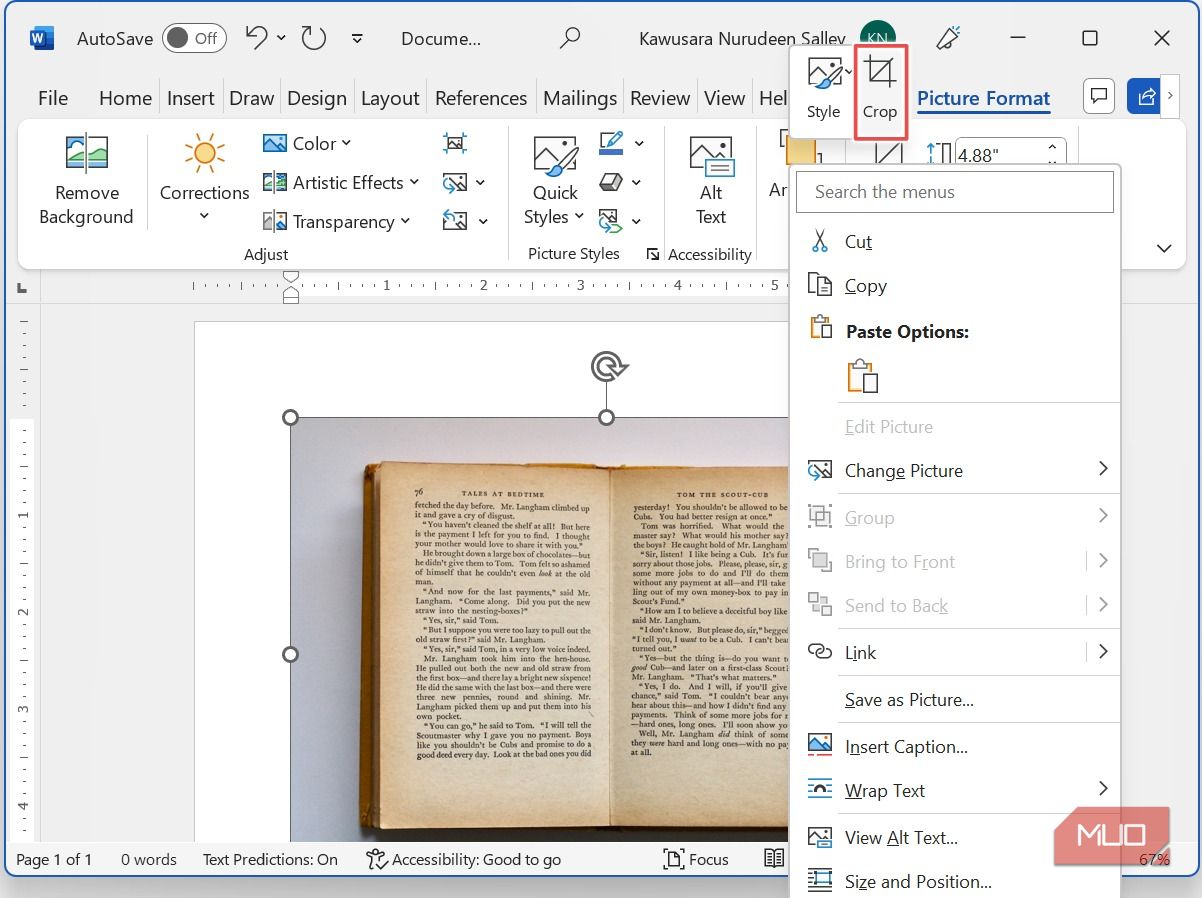
- Настройте рамки обрезки так, чтобы остался только основной блок текста. Кликните мышью вне области обрезки, чтобы зафиксировать изменение.
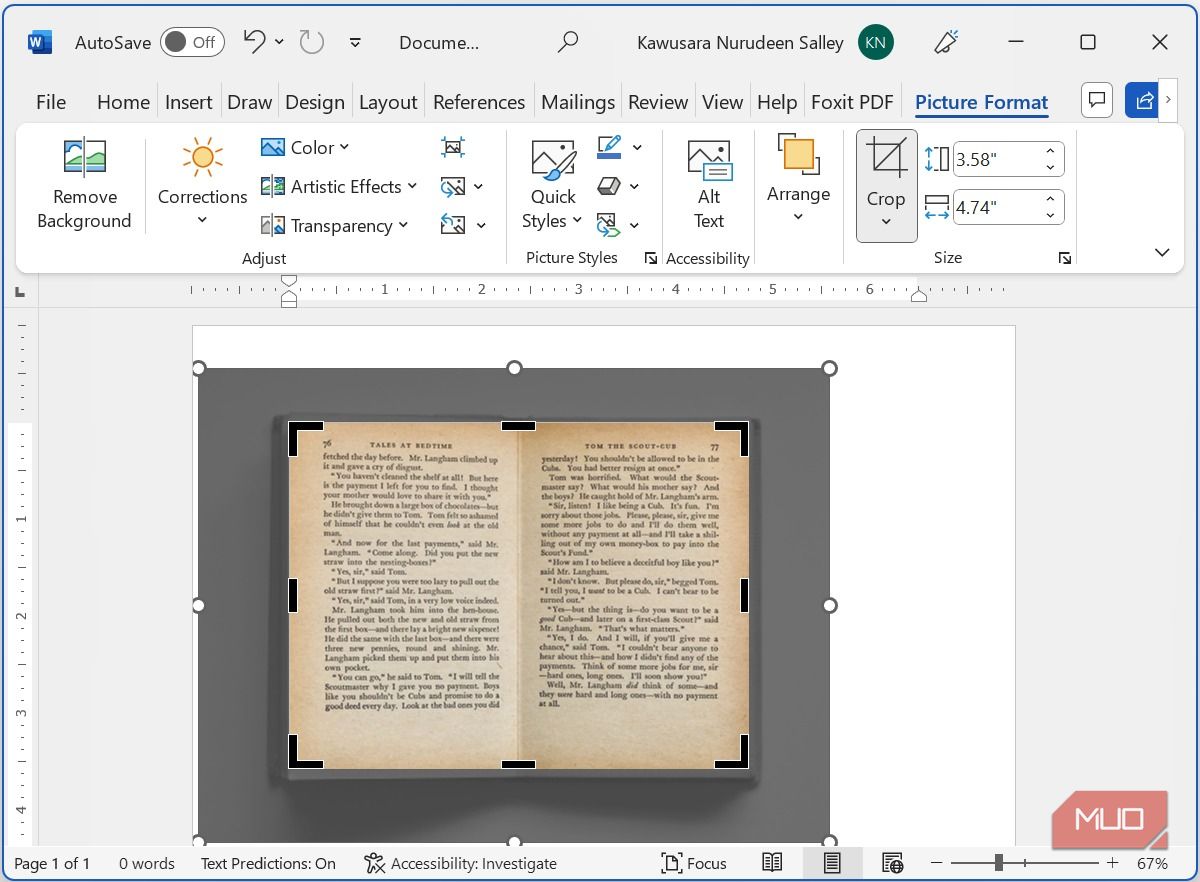
- С выбранным изображением нажмите кнопку Параметры макета и выберите опцию Перед текстом. Это позволит свободно перемещать и масштабировать картинку.
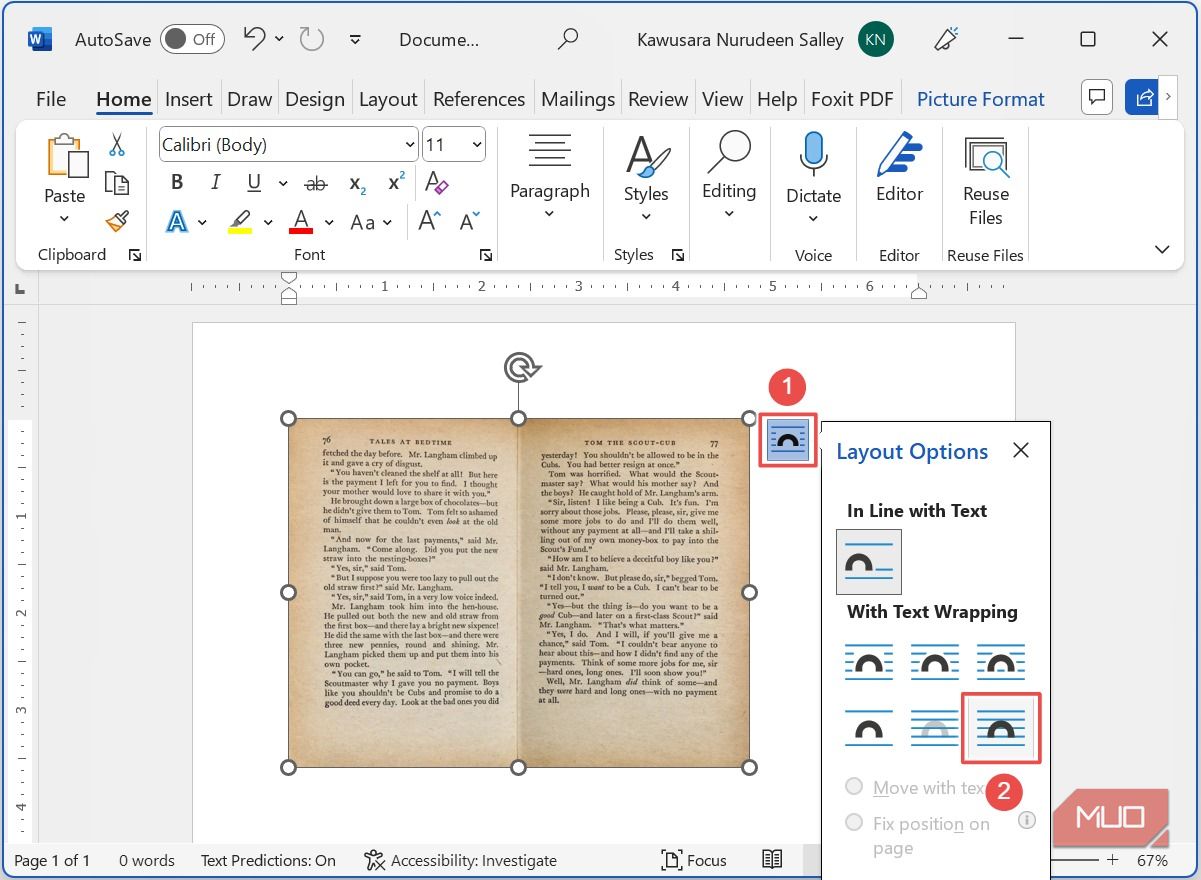
- Растяните изображение по ширине страницы, чтобы текст на картинке максимально занимал рабочую ширину. Чем крупнее и ровнее буквы, тем лучше результат распознавания.
Важно: избегайте сильного растягивания, которое искажает пропорции букв. Обрезка и аккуратное масштабирование повышают точность распознавания.
Шаг 3: Сохраните документ как PDF
В Word перейдите во вкладку Файл → Сохранить как → Обзор (или «Сохранить как» и укажите место). В диалоге укажите тип файла PDF и нажмите Сохранить.
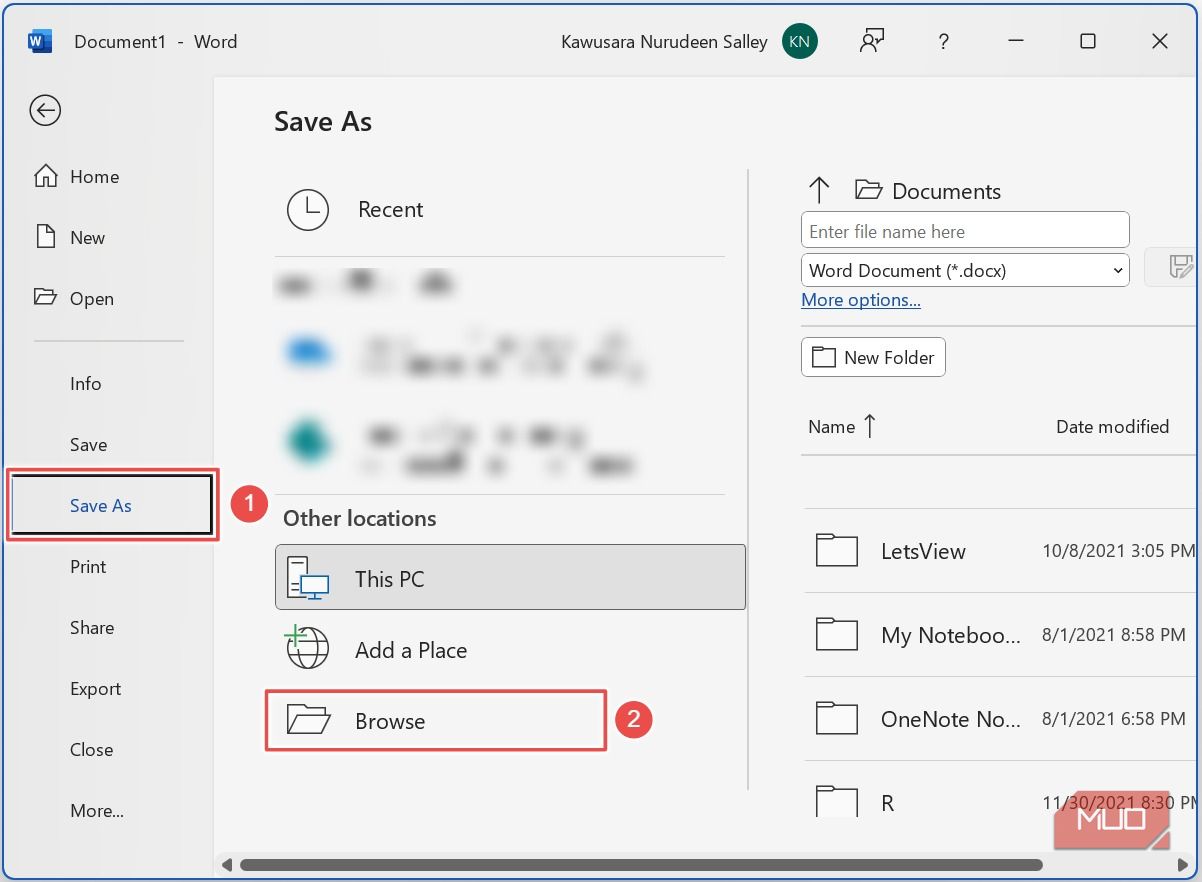
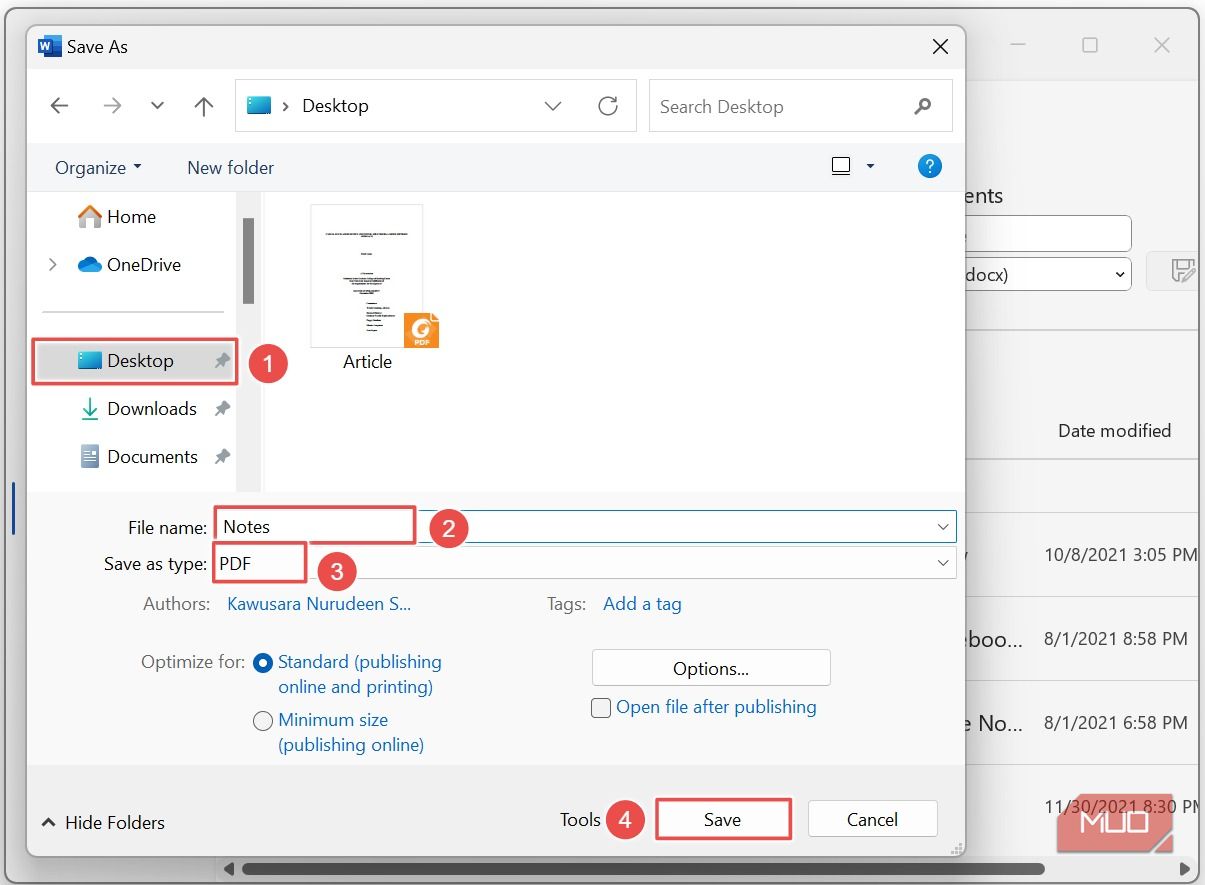
Причина: Word умеет открывать PDF и автоматически извлекать из него текст. Мы используем PDF как промежуточный формат, который запускает встроенную OCR‑логику при открытии файла.
Шаг 4: Откройте PDF в Microsoft Word
Перейдите во вкладку Файл → Открыть → Обзор, выберите только что сохранённый PDF и откройте его.
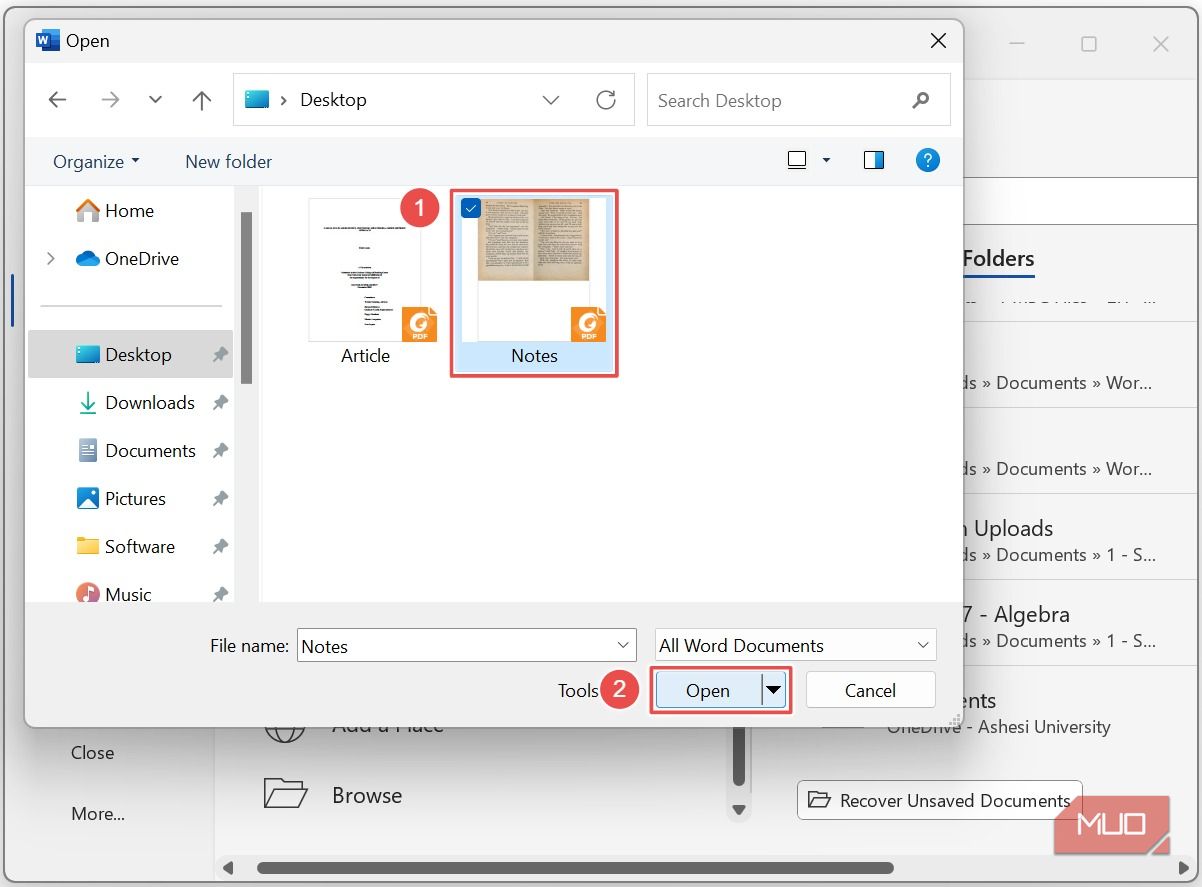
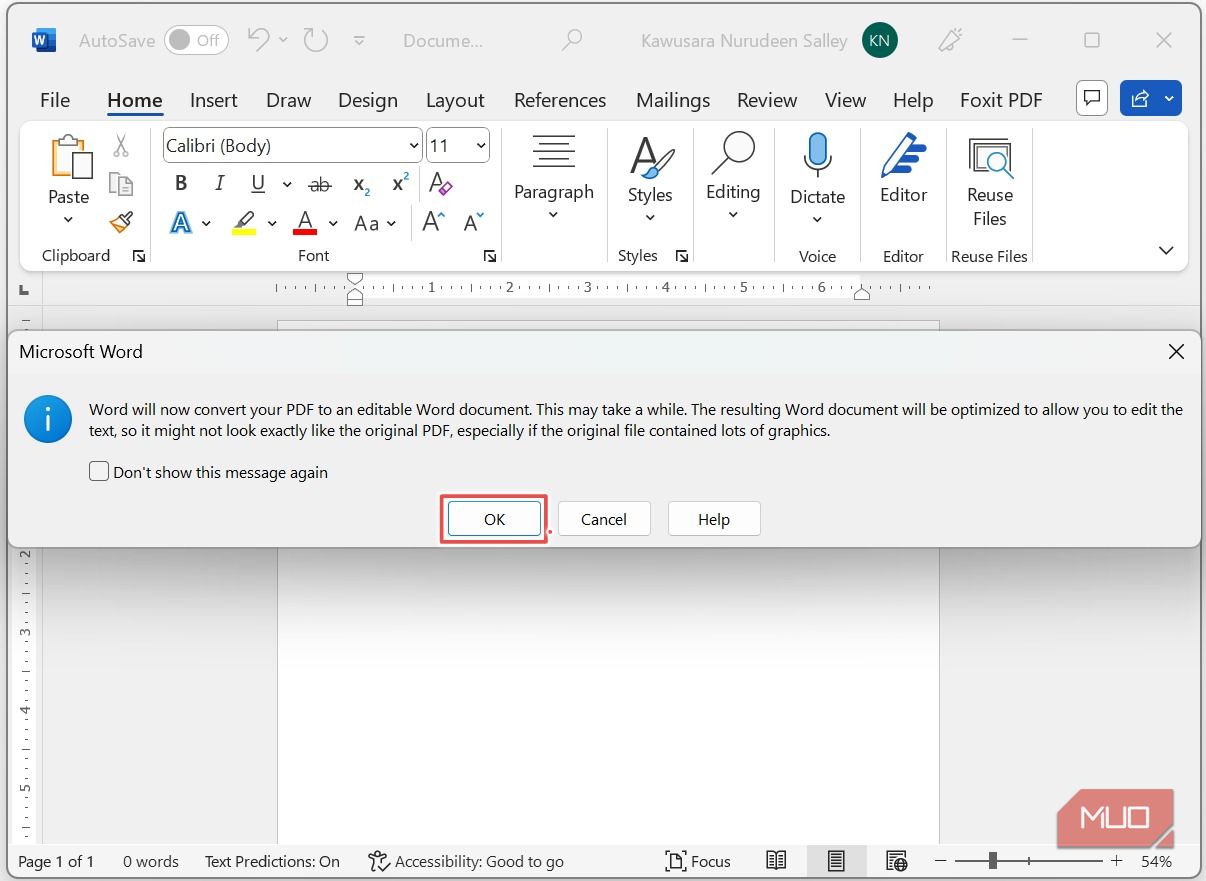
При открытии появится диалог с уведомлением о конвертации PDF в редактируемый документ — нажмите ОК.
Через пару мгновений Word покажет текст, распознанный из изображения. Проверьте документ и отредактируйте мелкие ошибки.
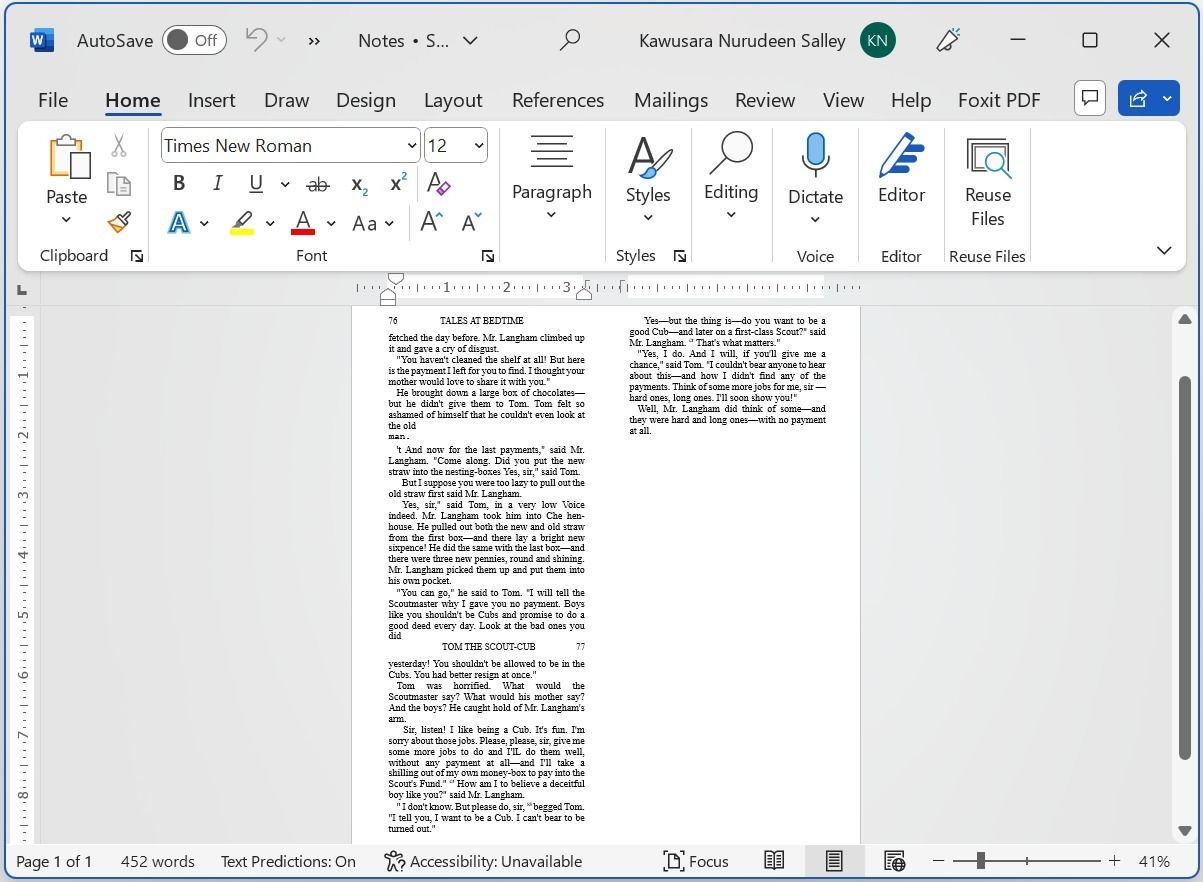
Microsoft Word обычно даёт высокую точность распознавания, особенно для чётких печатных шрифтов и аккуратно отсканированных страниц. Часто требуется только небольшая корректировка и форматирование.
Советы по повышению качества распознавания
- Используйте изображения высокого разрешения и ровно освещённые снимки.
- Обрежьте поля и лишние объекты, чтобы оставить только текст.
- Для многостраничных сканов объединяйте страницы в один PDF (при необходимости).
- Если текст имеет нестандартный шрифт или сложную вёрстку, проведите ручную вычитку после распознавания.
- Для рукописного текста качество распознавания сильно снижается; в таких случаях используйте специализированные OCR‑инструменты для рукописи.
Когда метод может не сработать
- Рукопись или неразборчивый почерк. Word затрудняется с рукописным вводом.
- Сильные искажения, поворот текста более чем на 15–20°. Предварительно выровняйте изображение.
- Низкое разрешение или размытость. Чем хуже картинка, тем хуже OCR.
- Сложные многоколоночные макеты и таблицы с неравномерными границами — структура может быть нарушена.
Альтернативные подходы
- Google Drive / Google Docs: загрузите PDF в Google Drive и откройте через Google Docs — там тоже есть встроенный OCR.
- Microsoft OneNote: вставьте изображение, правый клик → «Копировать текст с рисунка». Подходит для фрагментов текста.
- Приложения для телефона: Microsoft Lens, Adobe Scan, CamScanner — быстро сканируют с телефона и экспортируют в Word/PDF.
- Специализированные OCR‑решения: ABBYY FineReader и другие платные продукты дают больше контроля и обычно лучше справляются со сложными макетами.
Практическая методика (короткий SOP)
- Откройте новый документ в Word.
- Вставьте изображение и обрежьте лишнее.
- Установите «Перед текстом» и выровняйте ширину по странице.
- Сохраните как PDF.
- Откройте PDF в Word и подтвердите конвертацию.
- Проверяйте и исправляйте ошибки, сохраняйте финальную версию.
Контроль качества: тесты и критерии приёмки
Критерии приёмки:
- Все заголовки распознаны корректно (нет пропусков слов).
- Нумерованные и маркированные списки восстановлены логично.
- Таблицы не потеряли основную структуру (столбцы соответствуют исходным).
- Отсутствует значительное искажение символов (S, 5, O, 0 и т.п.).
Тестовые случаи:
- Тест A: Чёткий печатный текст, 1 страница — ожидаемая приёмка: минимальные правки.
- Тест B: Скан с двумя колонками — ожидаемая приёмка: возможные нарушения порядка колонок.
- Тест C: Рукопись — ожидаемая приёмка: скорее ручной ввод, OCR ненадёжен.
Роль‑ориентированные чек‑листы
Для редактора:
- Проверить абзацы, заголовки, форматирование шрифтов.
- Исправить опечатки, проверить переносы.
Для администратора / пользователя:
- Убедиться, что используются оригинальные файлы высокого качества.
- При необходимости объединить несколько страниц в один PDF.
Краткий словарь (1‑строка)
OCR — технология оптического распознавания символов, преобразующая изображение с текстом в редактируемые данные.
Итог
Метод «вставка → PDF → открыть в Word» прост и не требует дополнительных инструментов. Он подходит для большинства задач по конвертации печатного текста и снимков экрана. Для рукописей и очень сложных макетов используйте специализированные OCR‑решения.
Важно: всегда проверяйте распознанный текст — автоматические системы редко дают 100% точность в реальных документах.
Примените этот процесс к следующему изображению, которое вы планировали перепечатать, и оцените, сколько времени вы сэкономите.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
