Как преобразовать изображение в текст в Google Docs

Зачем это нужно
Иногда текст находится только на картинке — скан, фотография страницы или снимок экрана. Google Docs сам по себе не содержит явной кнопки OCR, но есть приемы, которые позволяют получить редактируемый текст без ручного ввода.
Кому полезно: контент-редакторам, исследователям, студентам, офисным сотрудникам и тем, кто оцифровывает бумажные документы.
Ключевые ограничения перед началом
- Максимальный рекомендуемый размер файла: 2 МБ.
- Минимальная высота букв для надёжного распознавания: ~10 пикселей.
- Изображение должно быть ориентировано правильно (не перевёрнуто).
- Сложные шрифты, рукопись и многоязычные макеты снижают точность.
Важно: встроенный OCR Google Диска не всегда сохраняет форматирование и не распознаёт точные шрифты — это нормально для коротких текстов и заметок, но плохо подходит для сложных многостраничных документов.
Метод 1 — через Google Диск (без сторонних приложений)
Google Диск умеет создавать документ Google Docs из изображения и автоматически извлекать текст.
- Откройте Google Диск в браузере и войдите в аккаунт.
- Нажмите Создать в левом верхнем углу и выберите Загрузить файл.
- Выберите изображение и нажмите Открыть.
- Кликните правой кнопкой по загруженному файлу, наведите на Открыть с помощью и выберите Google Документы.
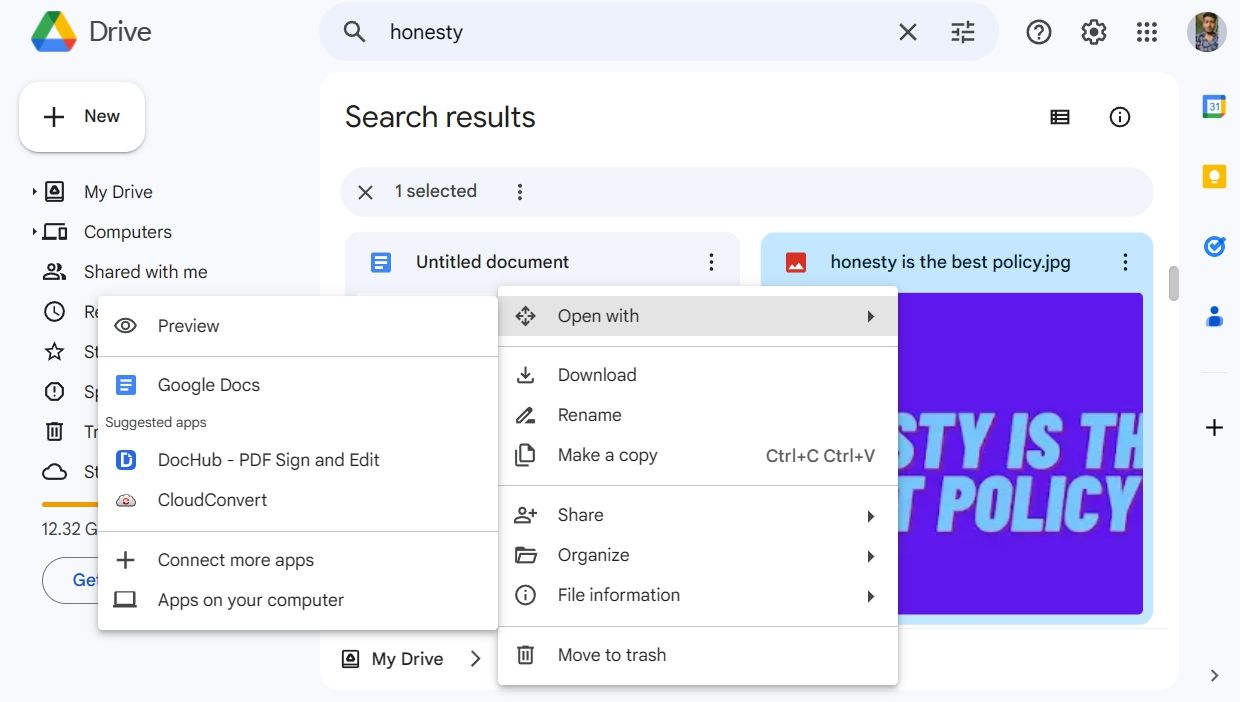
- Откроется новый документ Google Docs: сверху будет вставлена картинка, а ниже — распознанный текст.
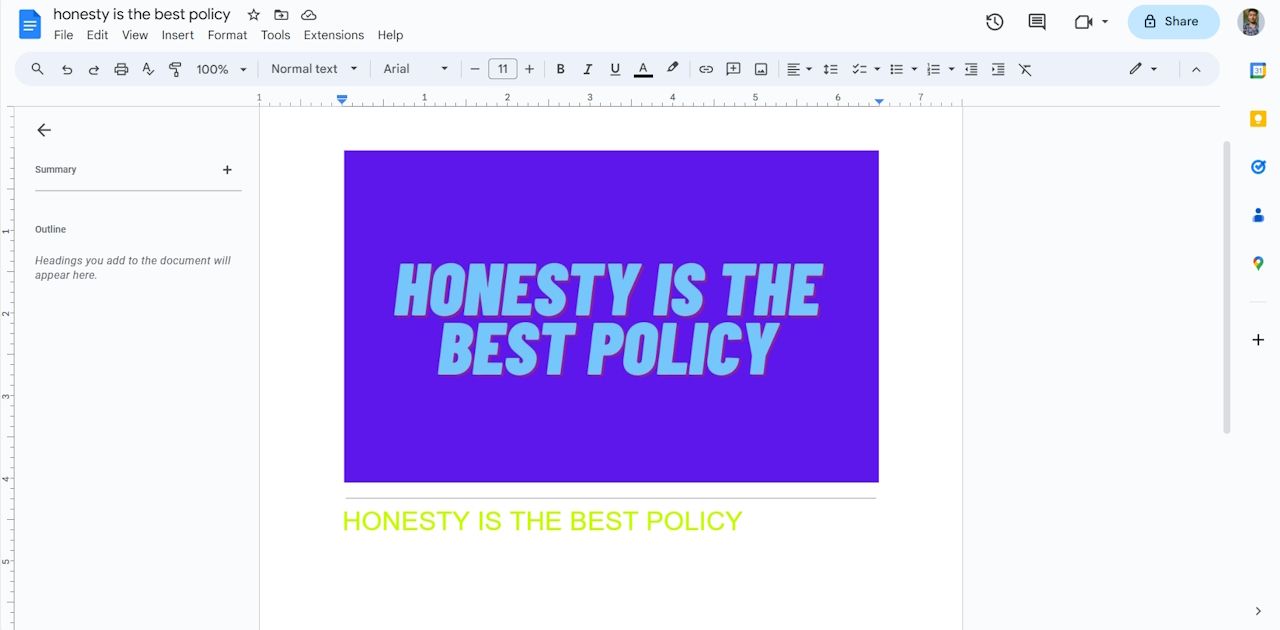
Советы по улучшению результата:
- Перед загрузкой обрежьте лишнее вокруг текста и выровняйте изображение.
- Увеличьте контраст и яркость, если текст светлый.
- Для многостраничных сканов разбивайте на отдельные файлы.
Когда использовать этот метод: когда вы не хотите устанавливать сторонние дополнения и у вас небольшие, простые по оформлению изображения.
Метод 2 — дополнение Img to Docs (более точное распознавание)
Если вам нужно лучшее качество распознавания и удобный интерфейс прямо в документе, установите дополнение Img to Docs.
- Откройте новый документ в Google Docs.
- Нажмите Расширения, наведите на Дополнения и выберите Установить дополнения.
- В строке поиска введите “Img to Docs - Image OCR” и нажмите Enter.
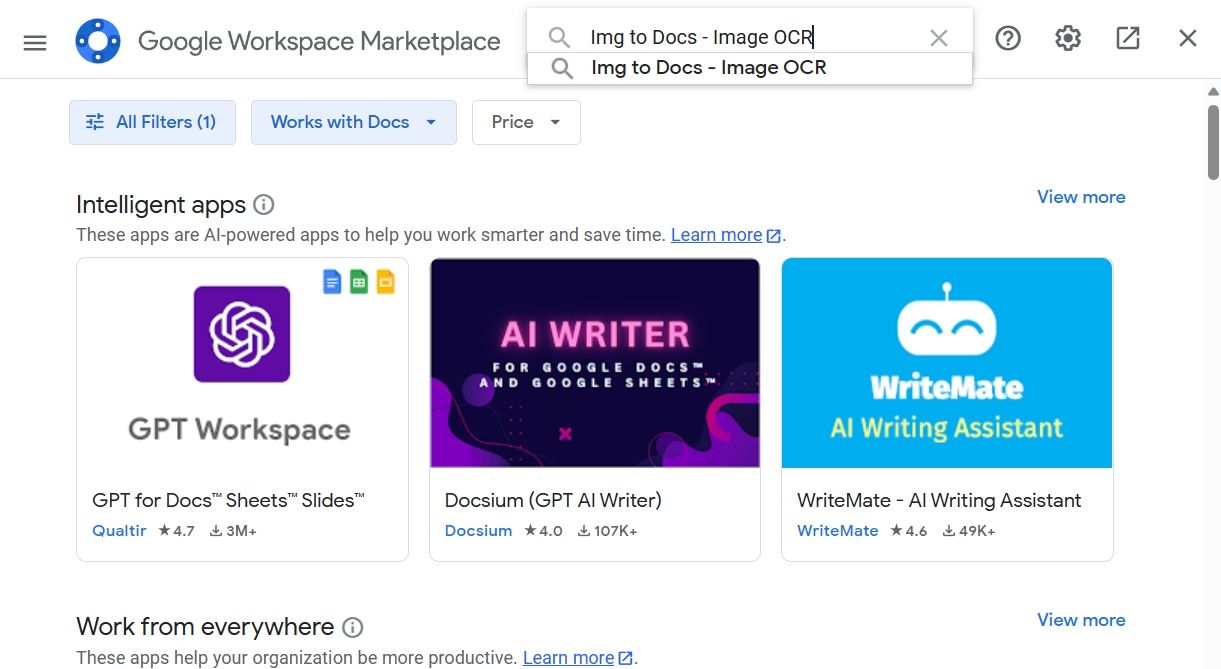
- Нажмите Установить и подтвердите разрешения, нажав Продолжить.
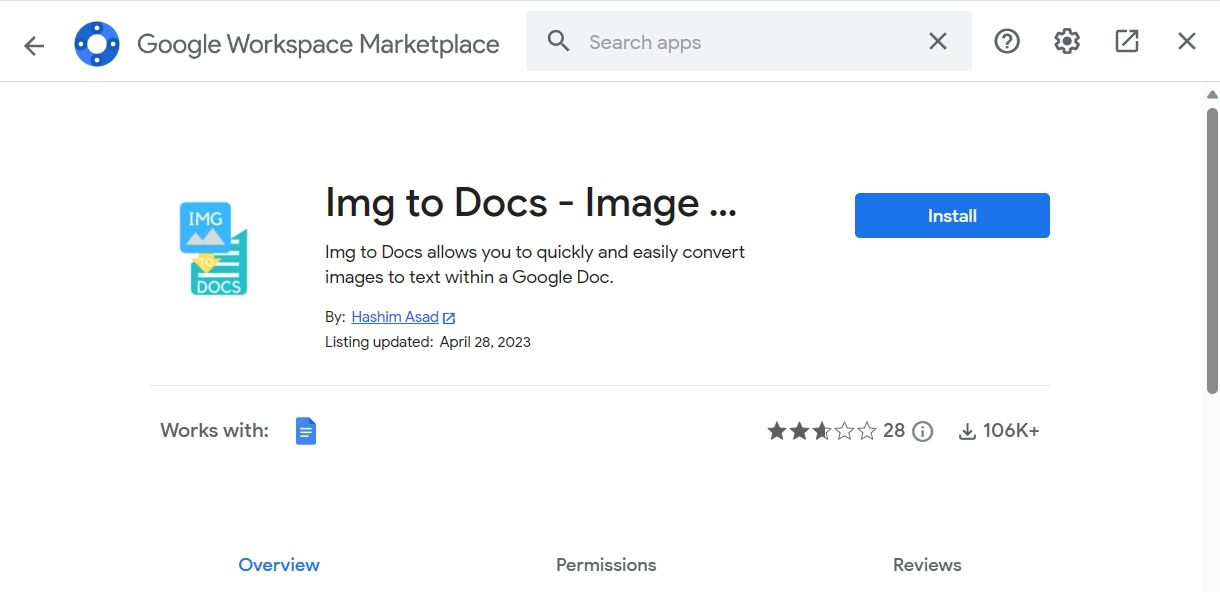
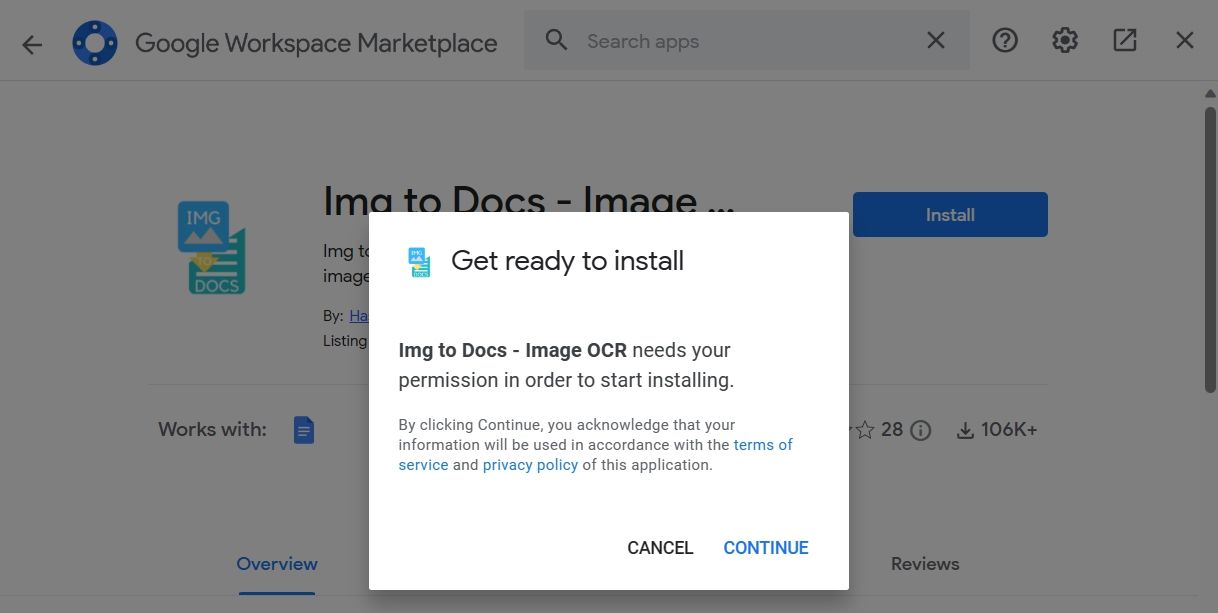
- После установки закройте окно дополнений.
Чтобы распознать текст:
- Нажмите Расширения, наведите на Img to Docs - Image OCR и выберите Запустить.
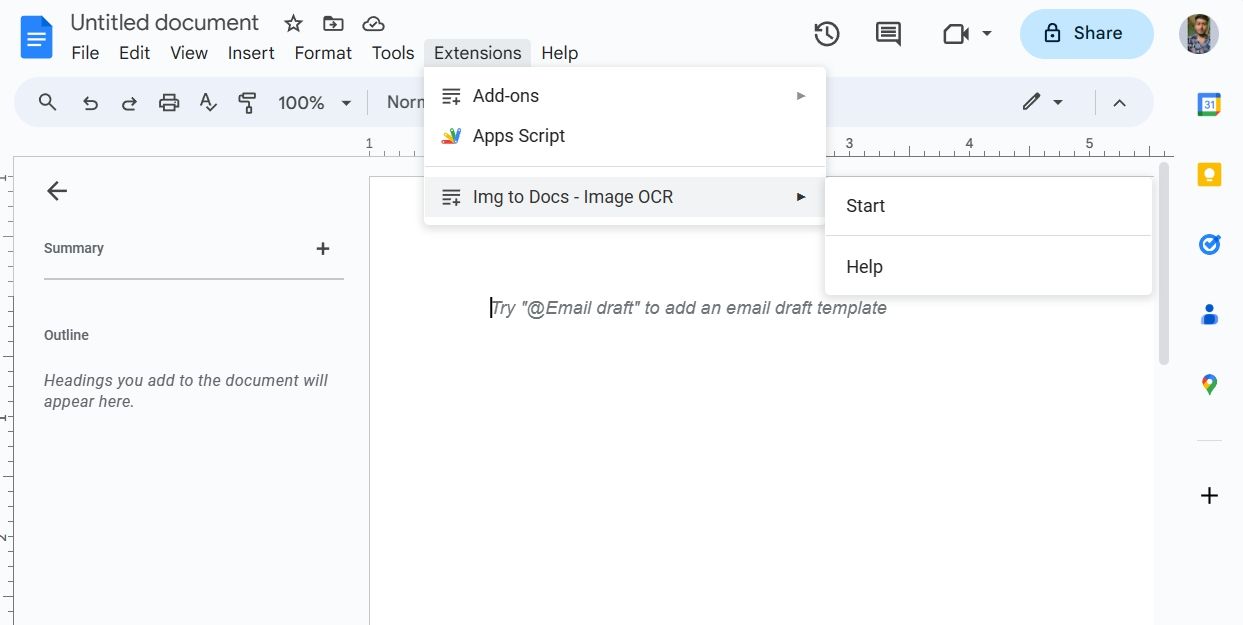
- В правой панели перетащите изображение в область дополнения.
- Дождитесь обработки и нажмите Вставить — распознанный текст появится в документе.
Плюсы дополнения: обычно лучше распознаёт макеты и сохраняет структуру. Минусы: требует разрешений на доступ к документам и сети, следите за политикой конфиденциальности.
Альтернативные подходы и инструменты
- Google Keep: приложите изображение к заметке и выберите «Извлечь текст изображения» — удобно на мобильных устройствах.
- Мобильные приложения OCR (Microsoft Office Lens, Adobe Scan): хорошо для съёмки документов камерой.
- Онлайн-сервисы OCR: работают быстро, но не загружайте туда конфиденциальные файлы.
- OneNote: умеет распознавать текст в вставленных изображениях.
Когда методы дают плохой результат — примеры и обходные пути
- Плохое освещение, шум и блики: уменьшите шум, отсканируйте заново или улучшите фото.
- Рукописный текст: большинство автоматических OCR плохо распознают рукопись — используйте специализированные сервисы или ручной ввод.
- Многоязычные документы: укажите язык, если это возможно, или разбивайте документ по языкам.
- Сложные колонки и таблицы: иногда проще вручную поправить формат после распознавания или использовать инструменты, которые ориентированы на таблицы.
Быстрый чек-лист перед распознаванием
- Изображение выровнено по горизонтали.
- Текст читаем, не размыт.
- Размер файла меньше 2 МБ (по возможности).
- Нет скрученных страниц и сильных бликов.
- Доступ к документу и плагинам безопасен для содержимого.
SOP для пакетной обработки серии изображений (короткая инструкция)
- Подготовьте все изображения: обрезка, выравнивание, компрессия без значительной потери качества.
- Загрузите в отдельную папку Google Диска.
- Открывайте файлы по очереди через Google Документы (или используйте скрипт/API для автоматизации).
- Проверьте и скорректируйте форматирование.
- Экспортируйте итог в нужный формат (DOCX, PDF, TXT) и сделайте резервную копию.
Для автоматизации крупных объёмов рассмотрите использование Google Drive API и облачных OCR-решений.
Модель принятия решения (Mermaid)
flowchart TD
A[У вас одно изображение?] -->|Да| B{Нужна точность?}
A -->|Нет, много файлов| E[Рассмотрите пакетную обработку через API или локальные инструменты]
B -->|Низкая| C[Использовать Google Диск]
B -->|Высокая| D[Установить Img to Docs или мобильный OCR]
C --> F[Проверить и исправить в Docs]
D --> FСравнение подходов — краткая матрица
| Подход | Точность | Приватность | Удобство | Подходит для |
|---|
| Google Диск | Средняя | Высокая (собственные сервисы) | Высокое | Быстрый разовый импорт | Img to Docs | Выше средней | Средняя (сторонний плагин) | Очень удобен | Текст с форматом и много изображений | Мобильные OCR | Высокая для снимков | Низкая/зависит от приложения | Очень удобно | Съёмка документов камерой | Онлайн-сервисы | Варьируется | Низкая для конфиденц. данных | Быстро | Нечувствительные документы
Правовые и конфиденциальные соображения
- Никогда не загружайте личные или конфиденциальные документы в незнакомые онлайн-сервисы.
- Проверьте разрешения у дополнений: какие данные они читают и к чему получают доступ.
- Для работы с персональными данными следуйте требованиям локального законодательства и корпоративным политикам (например, GDPR для персональных данных граждан ЕС).
Критерии приёмки
Документ считается успешно распознанным, если:
- Текст читаем и не требует более 10–15% ручных исправлений по смыслу.
- Структура (заголовки, параграфы, таблицы) восстановлена без критических ошибок.
- Конфиденциальность исходных файлов сохранена в соответствии с политикой организации.
Частые ошибки и как их исправить
- Сдвиг строк и потеря переносов: применяйте «Найти и заменить» для исправления символов переноса.
- Лишные пробелы в словах: используйте автоматические инструменты очистки текста.
- Неправильные языковые символы: убедитесь, что выбран правильный язык в настройках OCR.
Быстрые советы по качеству исходного изображения
- Используйте сканер или камеру с автофокусом.
- Освещение равномерное, избегайте бликов.
- Контраст фона и текста должен быть высоким.
- Для книг и журналов используйте прижим или специальный держатель для ровной плоскости.
Заключение
Извлечение текста из изображений в Google Docs доступно и выполняется двумя основными способами: через Google Диск для простых задач и через дополнение Img to Docs для более точного результата. Выбор зависит от требований к точности, объёма работы и конфиденциальности данных. Перед массовой обработкой протестируйте оба метода и внедрите чек-лист качества.
Короткая памятка: подготовьте изображение, выберите метод, проверьте результаты и сохраните резервную копию.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
