Llama 2: создание чатбота на Streamlit шаг за шагом

Введение
Llama 2 — это открытая крупная языковая модель (LLM) от Meta. Она доступна в нескольких размерах: 7 миллиардов, 13 миллиардов и 70 миллиардов параметров. В этой инструкции вы научитесь собирать интерактивный чатбот на Streamlit, который обращается к Llama 2 через платформу Replicate.
Коротко о терминах:
- LLM: большая языковая модель — модель, обученная предсказывать текст. Она генерирует ответы по входным подсказкам.
- Replicate: облачная платформа, дающая доступ к моделям как к API.
- Streamlit: фреймворк для быстрой публикации веб-интерфейсов для ML.
Что вы получите в результате
- Рабочий Streamlit-приложение, которое отправляет контекст диалога в Llama 2 и отображает ответы в реальном времени.
- Управление гиперпараметрами процесса генерации (temperature, top_p, max_seq_len).
- Механизм дебаунса для защиты от частых запросов к API.
Важно: инструкции не содержат платёжных данных — для работы нужны учётная запись Replicate и валидный REPLICATE_API_TOKEN.
Ключевые преимущества Llama 2
- Поддержка трёх основных размеров модели: 7B, 13B, 70B.
- Улучшенные диалоговые навыки благодаря обучению с участием человека (RLHF).
- Оптимизации для более быстрого вывода и экономии памяти (в сравнении с предшественником).
- Открытый исходный код и некоммерческая лицензия.
Быстрая схема работы приложения
- Streamlit рендерит интерфейс и боковую панель.
- Пользователь вводит сообщение — оно добавляется в состояние сессии.
- Приложение собирает историю диалога + pre-prompt и отправляет в Replicate.
- Ответ по частям отображается в чате (эффект печати).
- Механизм дебаунса предотвращает частые вызовы API.
Подготовка окружения
Создайте виртуальное окружение и установите зависимости. Рекомендуемый способ в статье — Pipenv:
pipenv shellУстановка библиотек:
pipenv install streamlit replicateStreamlit — фреймворк для интерфейсов. Replicate — облачный доступ к моделям.
Получение токена Replicate
Replicate требует регистрацию через GitHub. После входа в панель найдите модель llama-2–70b-chat через “Explore” и перейдите на страницу модели. Нажмите API → Python, чтобы получить инструкции и пример использования токена.
Скопируйте значение REPLICATE_API_TOKEN и сохраните его в файле .env (см. ниже).
Структура проекта
Рекомендуемая структура файлов:
- llama_chatbot.py — основной Streamlit-скрипт
- utils.py — вспомогательные функции (включая дебаунс)
- .env — секреты и endpointы моделей
Пример .env (замените токен и endpointы на свои):
REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'Важно: храните .env вне системы контроля версий или используйте безопасные хранилища секретов.
Полный код: ключевые фрагменты (сохраняйте кодовые блоки как есть)
Ниже — оригинальные блоки кода из руководства, их нужно вставить в соответствующие файлы проекта.
import streamlit as st
import os
import replicate# Global variables
REPLICATE_API_TOKEN = os.environ.get('REPLICATE_API_TOKEN', default='')
# Define model endpoints as independent variables
LLaMA2_7B_ENDPOINT = os.environ.get('MODEL_ENDPOINT7B', default='')
LLaMA2_13B_ENDPOINT = os.environ.get('MODEL_ENDPOINT13B', default='')
LLaMA2_70B_ENDPOINT = os.environ.get('MODEL_ENDPOINT70B', default='')REPLICATE_API_TOKEN='Paste_Your_Replicate_Token'
MODEL_ENDPOINT7B='a16z-infra/llama7b-v2-chat:4f0a4744c7295c024a1de15e1a63c880d3da035fa1f49bfd344fe076074c8eea'
MODEL_ENDPOINT13B='a16z-infra/llama13b-v2-chat:df7690f1994d94e96ad9d568eac121aecf50684a0b0963b25a41cc40061269e5'
MODEL_ENDPOINT70B='replicate/llama70b-v2-chat:e951f18578850b652510200860fc4ea62b3b16fac280f83ff32282f87bbd2e48'Pre-prompt и конфигурация страницы
Pre-prompt — фиксированный начальный контекст, который подсказывает модели роль ассистента. Его можно менять из боковой панели.
# Set Pre-propmt
PRE_PROMPT = "You are a helpful assistant. You do not respond as " \
"'User' or pretend to be 'User'." \
" You only respond once as Assistant."# Set initial page configuration
st.set_page_config(
page_title="LLaMA2Chat",
page_icon=":volleyball:",
layout="wide"
)Инициализация состояния сессии
# Constants
LLaMA2_MODELS = {
'LLaMA2-7B': LLaMA2_7B_ENDPOINT,
'LLaMA2-13B': LLaMA2_13B_ENDPOINT,
'LLaMA2-70B': LLaMA2_70B_ENDPOINT,
}
# Session State Variables
DEFAULT_TEMPERATURE = 0.1
DEFAULT_TOP_P = 0.9
DEFAULT_MAX_SEQ_LEN = 512
DEFAULT_PRE_PROMPT = PRE_PROMPT
def setup_session_state():
st.session_state.setdefault('chat_dialogue', [])
selected_model = st.sidebar.selectbox(
'Choose a LLaMA2 model:', list(LLaMA2_MODELS.keys()), key='model')
st.session_state.setdefault(
'llm', LLaMA2_MODELS.get(selected_model, LLaMA2_70B_ENDPOINT))
st.session_state.setdefault('temperature', DEFAULT_TEMPERATURE)
st.session_state.setdefault('top_p', DEFAULT_TOP_P)
st.session_state.setdefault('max_seq_len', DEFAULT_MAX_SEQ_LEN)
st.session_state.setdefault('pre_prompt', DEFAULT_PRE_PROMPT)Боковая панель и настройки
def render_sidebar():
st.sidebar.header("LLaMA2 Chatbot")
st.session_state['temperature'] = st.sidebar.slider('Temperature:',
min_value=0.01, max_value=5.0, value=DEFAULT_TEMPERATURE, step=0.01)
st.session_state['top_p'] = st.sidebar.slider('Top P:', min_value=0.01,
max_value=1.0, value=DEFAULT_TOP_P, step=0.01)
st.session_state['max_seq_len'] = st.sidebar.slider('Max Sequence Length:',
min_value=64, max_value=4096, value=DEFAULT_MAX_SEQ_LEN, step=8)
new_prompt = st.sidebar.text_area(
'Prompt before the chat starts. Edit here if desired:',
DEFAULT_PRE_PROMPT,height=60)
if new_prompt != DEFAULT_PRE_PROMPT and new_prompt != "" and
new_prompt is not None:
st.session_state['pre_prompt'] = new_prompt + "\n"
else:
st.session_state['pre_prompt'] = DEFAULT_PRE_PROMPTОтображение истории чата
def render_chat_history():
response_container = st.container()
for message in st.session_state.chat_dialogue:
with st.chat_message(message["role"]):
st.markdown(message["content"])Обработка ввода пользователя
def handle_user_input():
user_input = st.chat_input(
"Type your question here to talk to LLaMA2"
)
if user_input:
st.session_state.chat_dialogue.append(
{"role": "user", "content": user_input}
)
with st.chat_message("user"):
st.markdown(user_input)Генерация ответа ассистента
def generate_assistant_response():
message_placeholder = st.empty()
full_response = ""
string_dialogue = st.session_state['pre_prompt']
for dict_message in st.session_state.chat_dialogue:
speaker = "User" if dict_message["role"] == "user" else "Assistant"
string_dialogue += f"{speaker}: {dict_message['content']}\n"
output = debounce_replicate_run(
st.session_state['llm'],
string_dialogue + "Assistant: ",
st.session_state['max_seq_len'],
st.session_state['temperature'],
st.session_state['top_p'],
REPLICATE_API_TOKEN
)
for item in output:
full_response += item
message_placeholder.markdown(full_response + "▌")
message_placeholder.markdown(full_response)
st.session_state.chat_dialogue.append({"role": "assistant",
"content": full_response})Главная функция
def render_app():
setup_session_state()
render_sidebar()
render_chat_history()
handle_user_input()
generate_assistant_response()
def main():
render_app()
if __name__ == "__main__":
main()Обработка запросов к API и debounce
Создайте файл utils.py и вставьте следующий код — он реализует простую логику дебаунса.
import replicate
import time
# Initialize debounce variables
last_call_time = 0
debounce_interval = 2# Set the debounce interval (in seconds)
def debounce_replicate_run(llm, prompt, max_len, temperature, top_p,
API_TOKEN):
global last_call_time
print("last call time: ", last_call_time)
current_time = time.time()
elapsed_time = current_time - last_call_time
if elapsed_time < debounce_interval:
print("Debouncing")
return "Hello! Your requests are too fast. Please wait a few" \
" seconds before sending another request."
last_call_time = time.time()
output = replicate.run(llm, input={"prompt": prompt + "Assistant: ",
"max_length": max_len, "temperature":
temperature, "top_p": top_p,
"repetition_penalty": 1}, api_token=API_TOKEN)
return outputЗатем импортируйте debounce-функцию в llama_chatbot.py:
from utils import debounce_replicate_runЗапустите приложение:
streamlit run llama_chatbot.pyОжидаемый вывод:
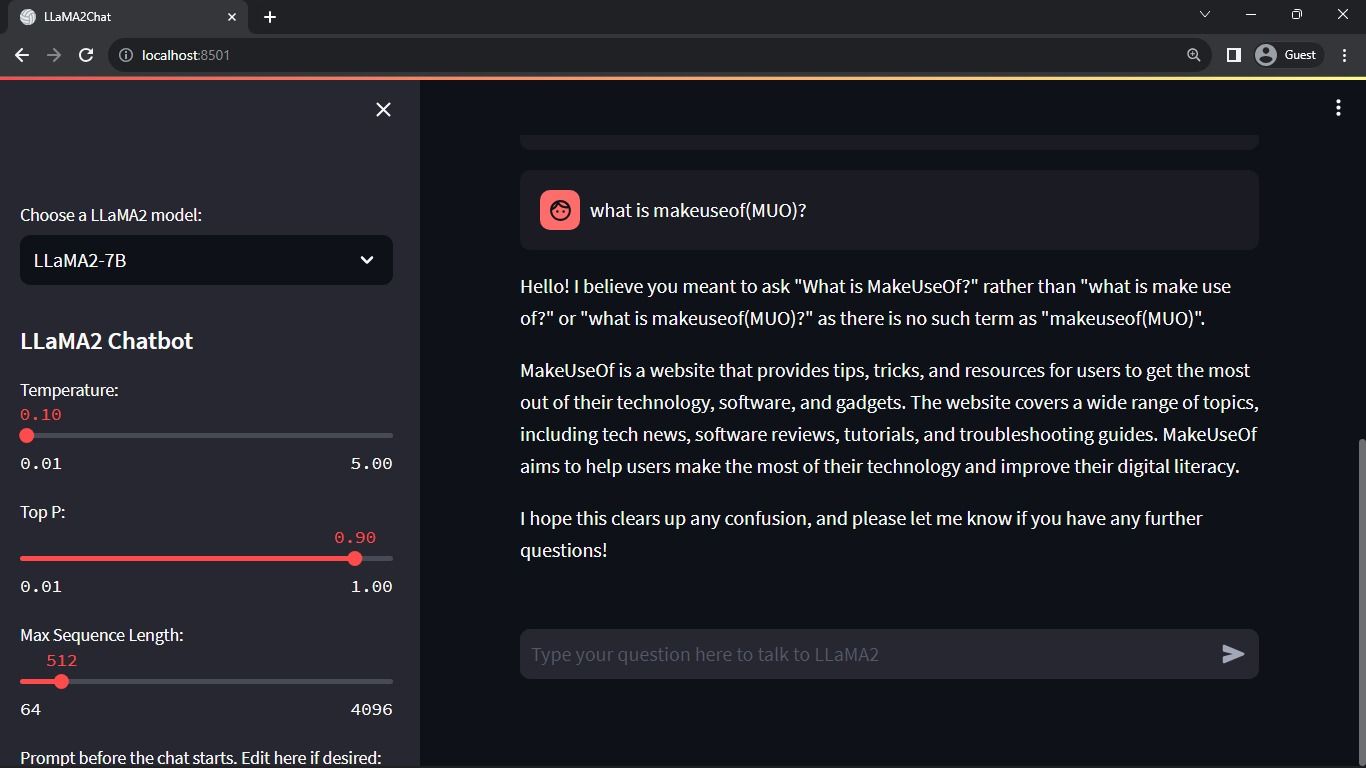
Отладка и типичные проблемы
- Неправильный REPLICATE_API_TOKEN: проверьте .env и переменные окружения.
- Ошибки endpoint: убедитесь, что MODEL_ENDPOINT* совпадают с теми, что в Replicate.
- Тайм-ауты и квоты: при частых запросах API может возвращать ошибки; используйте дебаунс и ретраи.
- Память и скорость: модели 70B требуют больше ресурсов и обычно работают медленнее, чем 7B.
Важно: для локального тестирования используйте меньшую модель (7B/13B), чтобы снизить задержки и стоимость.
Когда такой чатбот не подойдёт (контрпримеры)
- Высоконагруженные реальное время системы: если требуется миллисекундная обработка, облачные вызовы моделей будут узким местом.
- Строго регулируемые данные: если ваша система обрабатывает персональные данные с жёсткими требованиями соответствия (GDPR, HIPAA), потребуется дополнительная архитектура и юридические проверки.
- Очень специфичные экспертные домены: модель может давать правдоподобные, но неверные ответы; в таких задачах нужна встраиваемая валидация или постобработка.
Альтернативные подходы
- Хостинг модели локально на собственном сервере (если есть ресурсы и лицензия позволяет).
- Использование других провайдеров API: OpenAI, Anthropic, Mistral (учтите лицензии и стоимость).
- Комбинация Retrieval-Augmented Generation (RAG) — поиск по базе знаний + генерация, чтобы улучшить точность ответов.
Ментальные модели и эвристики
- Разделяйте «генерацию» и «валидацию»: генерация — задача модели; проверка — задача приложения.
- Начните с малого: прототип на 7B, затем масштабируйте до 13B/70B при необходимости.
- Управляйте температурой: низкая температура — более детерминированные ответы; высокая — творческие.
Факто-бокс: ключевые числа
- Размеры моделей: 7B, 13B, 70B параметров.
- Рекомендуемая максимальная длина последовательности в примере: 64–4096 токенов.
- По умолчанию в примере: temperature = 0.1, top_p = 0.9, max_seq_len = 512.
Мини-методология развёртывания
- Зарегистрируйтесь в Replicate и получите токен.
- Настройте виртуальное окружение и .env.
- Реализуйте Streamlit UI и utils.py с дебаунсом.
- Тестируйте локально с 7B, проверяйте ответы на адекватность.
- Масштабируйте модель и оптимизируйте параметры при необходимости.
Роль-based чеклист перед запуском (быстро)
- Для разработчика:
- Проверен REPLICATE_API_TOKEN
- .env исключён из репозитория
- Обработаны ошибки API и исключения
- Для исследователя:
- Оценена адекватность ответов на тестовой выборке
- Есть план валидации фактов
- Для продакшен-инженера:
- Настроен мониторинг и логирование запросов
- Реализованы лимиты и ретраи
Безопасность и конфиденциальность
- Не отправляйте в модель чувствительные персональные данные без юридической проверки и шифрования.
- Храните токены в защищённом хранилище.
- Логируйте минимально необходимую информацию и применяйте маскирование для PII.
Советы по оптимизации и стоимость
- Используйте меньшие модели для тестов и прототипов.
- Настройте debounce и rate limit, чтобы избежать лишних затрат.
- Кешируйте повторяющиеся подсказки и ответы (особенно для часто задаваемых вопросов).
Совместимость и миграция
- Если вы планируете сменить провайдера, изолируйте слой интеграции с API (абстрагируйте вызовы replicate.run), чтобы переиспользовать UI и логику сессий.
Примеры тест-кейсов и критерии приёмки
- Корректность: для набора тестовых вопросов ответы должны попадать в ожидаемый семантический диапазон.
- Стабильность: приложение выдерживает параллельные сессии (в пределах квот провайдера).
- Безопасность: токены не утекли и не попадают в логи.
Примеры ошибок и способы их решения
- Ошибка авторизации 401: проверьте токен и формат .env.
- Ошибка превышения лимита: добавьте экспоненциальные ретраи и уведомления.
- Некорректный вывод модели: уменьшите temperature или добавьте в pre-prompt строгие инструкции.
Рекомендации по локализации для русскоязычной аудитории
- При работе с русским языком протестируйте модель на наборе локализованных запросов: сокращения, падежи, идиомы.
- Если вы собираете пользовательский контент, уточните в политике конфиденциальности хранение данных и юрисдикцию обработки.
Дальнейшие шаги и развитие проекта
- Добавить RAG (поиск по базе документов) для повышения точности.
- Внедрить систему модерации ответов (в т.ч. фильтрацию токсичных сообщений).
- Построить CI/CD для автоматического развёртывания Streamlit в контейнере.
Краткое резюме
- Llama 2 даёт мощную открытую платформу для создания диалоговых приложений.
- Streamlit упрощает создание интерфейса — при этом важно правильно управлять сессиями и безопасностью.
- Дебаунс и кеширование помогают снизить расходы и нагрузку на API.
Заметки:
- Всегда проверяйте лицензионные ограничения для выбранной модели и используйте её в соответствии с политикой платформы.
Счастливого прототипирования!
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
