Как просмотреть старые версии сайта с помощью Wayback Machine

О чём этот материал
В этой статье подробно описано, как пользоваться Wayback Machine для просмотра старых версий сайтов, что означают цвета и метки на временной шкале и календаре, в каких случаях архив может не содержать нужной страницы, а также альтернативы и практические чек‑листы для разных ролей.
Что такое Wayback Machine (коротко)
Wayback Machine — это сервис Internet Archive, который периодически сканирует и сохраняет копии веб‑страниц. Он фиксирует содержимое сайта в конкретный момент времени — снимок (snapshot). Снимок не обязательно отражает все пользовательские данные или защищённый контент.
Важно: это не зеркало сайта в реальном времени — это архив снимков по конкретным датам.
Быстрая пошаговая инструкция
- Откройте https://archive.org/web в браузере.
- Введите адрес сайта (URL) в строку Wayback Machine и нажмите «Browse History».
- На следующей странице посмотрите временную шкалу и выберите год.
- В календаре выберите дату. Цвет и размер кружка подскажут детали снимков.
- Наведите курсор на дату и выберите конкретное время снимка в всплывающем меню.
- Просмотрите архивную версию страницы — навигация внутри архива работает как в обычном браузере, но ссылки могут вести к другим сохранённым снимкам или к отсутствующим ресурсам.

Как читать временную шкалу и календарь

- Нет цвета: в этот день сайт не был сохранён.
- Синий: снимок успешно сделан и доступен.
- Зелёный: перенаправление (код 3xx) было зафиксировано.
Размер круга показывает, что для этой даты существует несколько снимков. Большой круг означает, что снимков больше одного; это не обязательно означает больше изменений на сайте — это просто частые сохранения в течение дня.
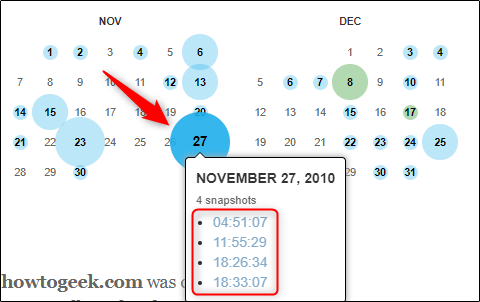
Наведите курсор на дату, откройте список доступных времён и выберите нужный снимок для просмотра.
Как только снимок загружен, вы можете просматривать страницу так, как она выглядела в тот момент.
Когда Wayback Machine может не помочь
- Сайт был защищён паролем или требовал аутентификации — такие страницы обычно не архивируются.
- Владелец сайта запретил сканирование через файл robots.txt; если сайт позже открылся, старые запреты могли предотвратить архивирование.
- Динамический контент, генерируемый на стороне клиента (например, многие SPA, API‑запросы), может быть неполностью сохранён.
- Контент был удалён до того, как сайт был проиндексирован.
Важно: автоматическое отсутствие снимка не означает, что данные были навсегда утеряны — возможны другие источники.
Альтернативные ресурсы и подходы
- oldweb.today — эмуляция старых браузеров и просмотр записей.
- Библиотека Конгресса — национальные архивы и специализированные коллекции.
- Локальные кэши поисковых систем (Google Cache, Bing Cache) — могут иметь копии отдельных страниц.
- Архивы новостных порталов и профильные репозитории (например, GitHub для кода).
Каждый инструмент полезен в разных сценариях: Wayback хорошо подходит для массовых снимков, oldweb.today помогает восстановить поведение старых браузеров, а кеш поисковиков — быстрый вариант для недавних удалений.
Мини‑методика для расследований и восстановления
- Зафиксируйте исходный URL и дату/время, когда вы обнаружили проблему.
- Проверьте Wayback Machine на предмет последних доступных снимков.
- Если нет нужного снимка, попробуйте альтернативы (oldweb.today, поисковые кеши).
- Скачайте или сделайте скриншоты важных страниц для доказательной базы.
- Сравните версии и составьте хронологию изменений.
- При необходимости свяжитесь с владельцем сайта или провайдером хостинга.
Роль‑ориентированные чек‑листы
Журналист:
- Найти все релевантные снимки для хронологии.
- Сохранить скриншоты и метаданные (URL, время снимка).
- Проверить источники и альтернативные репозитории.
Разработчик / Сисадмин:
- Проверить robots.txt в архиве и текущий robots.txt.
- Оценить, какие ресурсы (скрипты, CSS) не сохранились.
- Восстановить статические файлы из кэшей или резервных копий.
Исследователь / историк:
- Построить хронологию изменений по доступным снимкам.
- Сопоставить содержимое страниц с внешними источниками (новости, форумы).
Обычный пользователь:
- Ввести URL и найти ближайший по дате снимок.
- Сохранить страницу в PDF или сделать скриншот для своих нужд.
Когда архив недостоверен или требует осторожности
- Данные в архиве — это копии; они могут не включать пользовательские данные, комментарии или личные кабинеты.
- Ссылки внутри архива могут вести к другим версиям страниц, а не к оригинальным внешним ресурсам.
- Юридические и этические аспекты: использование материалов может регулироваться авторским правом или политикой конфиденциальности.
Короткий глоссарий
- Снимок (snapshot): сохранённая копия веб‑страницы в момент времени.
- robots.txt: файл, в котором сайт указывает правила для роботов‑сканеров.
- 3xx перенаправление: HTTP‑код, указывающий, что ресурс переехал.
Краткое резюме
Wayback Machine — мощный и простой инструмент для просмотра старых версий сайтов. Он особенно полезен для восстановления контента, расследований и проверки истории страниц. Однако он не гарантирует полного сохранения всех элементов страницы, поэтому всегда проверяйте альтернативные источники и сохраняйте важные материалы самостоятельно.
Важно: если вы используете архив в профессиональных целях, фиксируйте метаданные и сохраняйте доказательства (скриншоты, PDF) — архивы со временем могут меняться.
Короткое объявление для соцсетей (100–200 слов):
Wayback Machine на archive.org — быстрый способ увидеть, как выглядел сайт в прошлом. Введите URL, выберите год и дату на временной шкале, и вы получите архивную копию страницы. Это удобно для восстановления удалённого контента, проверки изменений или исторических исследований. Помните, что не все страницы сохраняются (пароль, robots.txt, динамические сайты) — поэтому при работе с важными материалами делайте локальные копии.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
