Ошибка 1460 (Cluster Shared Volume) — как найти и устранить

Что такое эта ошибка
Коротко: Error 1460 (иногда сопровождается Event ID 5142 или кодом c00000b5) указывает, что Cluster Shared Volume перешёл в состояние паузы из‑за проблем с доступом к хранилищу или сетевыми путями. CSV — это общий диск в кластере, используемый несколькими узлами одновременно.
Краткое определение терминов:
- CSV — Cluster Shared Volume, общий том кластера.
- MPIO — многоканальный ввод/вывод (мультипатинговая технология).
- VSS — Volume Shadow Copy Service, служба теневого копирования.
Быстрое исправление: установка недостающих протоколов
- Нажмите клавишу Windows + R и введите
ncpa.cpl. Нажмите ОК.

- Найдите нужное сетевое подключение, щёлкните правой кнопкой и выберите Свойства.
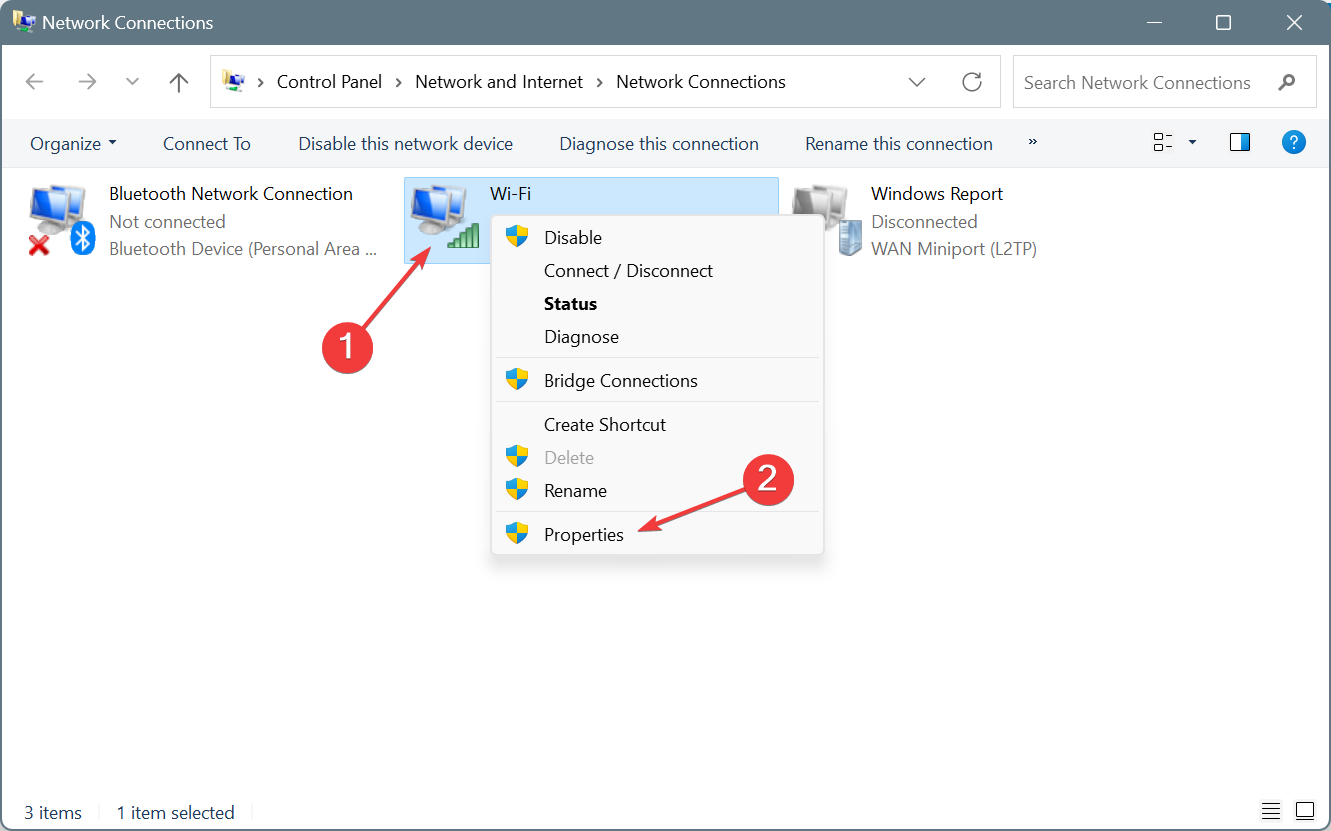
- Убедитесь, что в списке присутствуют и включены: Клиент для сетей Microsoft и Общий доступ к файлам и принтерам для сетей Microsoft.

- Если их нет — нажмите Установить и добавьте соответствующие элементы.
После этого перезапустите сетевой адаптер или хост. Во многих случаях событие Event ID 5142 / Error 1460 исчезает.
Подробная проверка — пошаговая методика (mini-methodology)
- Выполните валидацию кластера через Cluster Validation Wizard. Это выявит конфигурационные несоответствия.
- Проверьте конфигурацию MPIO и наличие специфичных инструментов поставщика хранилища (например, NetApp DSM/PowerShell-модули) на всех узлах.
- Убедитесь, что все узлы видят все пути к хранилищу (multipath status). На серверах проверьте список путей и их состояние.
- Проверьте, не перемещалась ли собственность CSV на другой узел вручную; убедитесь, что собственность находится на ожидаемом узле.
- Если используется аппаратный VSS-провайдер — временно переключитесь на Microsoft VSS и проверьте, исчезнет ли проблема.
- Проверьте, отформатирован ли CSV в ReFS; в редких сценариях ReFS может вести себя иначе с определёнными резервными решениями.
- Просмотрите логи коммутаторов и контроллеров хранения на предмет ошибок на уровне сети/задержек.
Важно: после каждого изменения — воспроизведите проверку: отмониторьте состояние CSV и логи событий на каждом узле.
Когда эти шаги не помогут — контрпримеры и дополнительные подходы
- Контрпример 1: Если проблема вызвана аппаратной ошибкой контроллера хранения или кабеля, переустановка протоколов не поможет. Проверьте SMART на дисках и аппаратные логи хранилища.
- Контрпример 2: Если проблема вызвана задержками в сети (high latency) или флопами порта коммутатора — программные правки не исправят физический дефект.
Альтернативные подходы:
- Временно переместите роли и ресурсы на другие узлы, чтобы изолировать проблемный хост.
- Запустите временное переключение на другой путь хранения (failover) и проверьте, повторяется ли ошибка.
- Если используется стороннее ПО резервного копирования, обратитесь к документации поставщика на предмет известных проблем с ReFS/CSV/MPIO.
Ролевые чеклисты — кто что делает
Администратор кластера:
- Запустить Cluster Validation.
- Проверить состояние CSV и ownership.
- Просмотреть журналы System и FailoverClustering.
Сетевой инженер:
- Проверить состояние NIC на каждом узле.
- Убедиться в включённых протоколах (Client for Microsoft Networks, File and Printer Sharing).
- Просмотреть логи коммутатора и маршрутизации.
Инженер хранилища:
- Проверить MPIO и их статус на хостах.
- Просмотреть логи контроллера хранилища (NetApp/EMC/HPE и т.д.).
- Подтвердить целостность физических путей.
Оператор резервного копирования:
- Проверить используемый VSS-провайдер и совместимость с ReFS.
- Воспроизвести задачу бэкапа на одном узле и проанализировать ошибки.
Критерии приёмки / тесты (acceptance)
- CSV выходит из состояния паузы и возвращается в нормальное состояние на всех узлах.
- Нет новых записей Event ID 5142 или Error 1460 в течение 24 часов после исправления.
- Резервное копирование проходит успешно (если применимо) на тестовом томе.
- Все пути MPIO стабильны и не показывают Flapping/Offline.
Пример инцидентного плана (runbook)
- Зафиксировать время и собрать логи System, FailoverClustering и Storage.
- Проверить сетевые протоколы на узле с ошибкой (см. раздел Быстрое исправление).
- Выполнить Cluster Validation и сохранить отчёт.
- Если ошибка сохраняется — отключить аппаратный VSS и переключиться на Microsoft VSS.
- Если аппаратика заподозрена — инициировать работу с поставщиком хранилища и сетевого оборудования.
- Вернуть изменения после подтверждения исправности.
Короткий глоссарий
- CSV — общий том в кластере, используемый несколькими узлами одновременно.
- MPIO — технология мультипатинга, обеспечивает несколько путей к хранилищу.
- VSS — служба теневого копирования Windows.
Примечание
Если у вас одновременно появляются сообщения «Your disk can’t replace bad clusters» или «Group or resource is not in the correct state», эти ошибки могут требовать отдельных шагов — проверьте связанные статьи по каждому конкретному сообщению.
Итог
Если вы столкнулись с Error 1460 / Event ID 5142: начните с простых проверок — сетевые протоколы, MPIO, ownership CSV и VSS. Если базовые шаги не помогают, расширьте диагностику на аппаратный уровень (контроллеры хранения, коммутаторы) и привлекайте поставщика хранилища. Применяйте предложенный чеклист и runbook для систематической отладки.
Важно: перед любыми изменениями в кластере делайте полные резервные копии конфигурации и данных.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
