Как использовать IMPORTXML в Google Sheets для веб-скрейпинга и автоматизации данных

Что такое IMPORTXML и зачем он нужен
IMPORTXML — это функция Google Sheets, предназначенная для импорта данных с веб-страниц, которые представлены в формате XML или HTML. Простыми словами: вы указываете URL и XPath-запрос, а Google Sheets возвращает найденные элементы в таблицу.
Кратко о ключевых терминах:
- XPath — язык навигации по XML/HTML-документу; позволяет выбрать узлы (элементы, атрибуты, текст).
- URL — адрес веб-страницы, откуда брать данные.
Основной синтаксис:
=IMPORTXML(url, xpath_query)- url: строка с адресом (можно ссылаться на ячейку с адресом).
- xpath_query: строка с XPath-выражением.
Быстрый пример
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")Эта формула собирает все значения атрибута href с указанной страницы.
Основы XPath (коротко и наглядно)
/и//— одноуровневый и рекурсивный поиск.//aвыбирает все теги a на странице.@— доступ к атрибутам, например//@hrefили//a/@href.text()— текст внутри элемента —//p/text().- Предикаты
[ ]— фильтры://div[@class='container']. - Функции:
contains(),starts-with(),normalize-space().
Совет: используйте относительные пути и классы, а не абсолютные пути, если структура страницы может меняться.
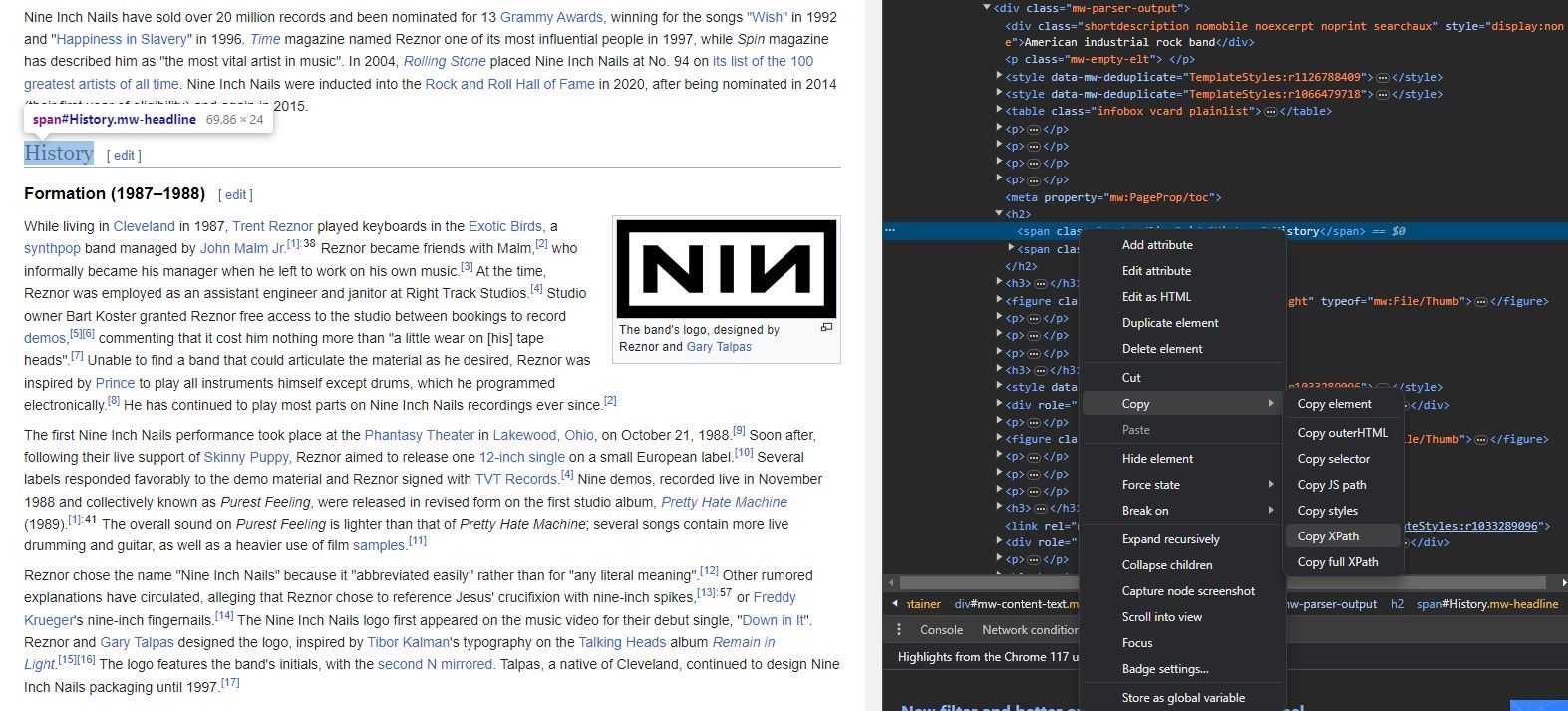
Как получить XPath элемента в браузере
- Откройте страницу в браузере (Chrome/Firefox/Edge).
- Найдите нужный элемент на странице.
- Правый клик → Инспектировать (Inspect).
- В панели с HTML-кодом правый клик по выделенному узлу → Copy → Copy XPath.
Это удобный стартовый путь, но скопированный XPath часто бывает слишком детализирован (валидный, но хрупкий). Подумайте о том, чтобы упростить путь, заменив абсолютные индексы на классы или функции contains().
Как собирать ссылки: практические примеры
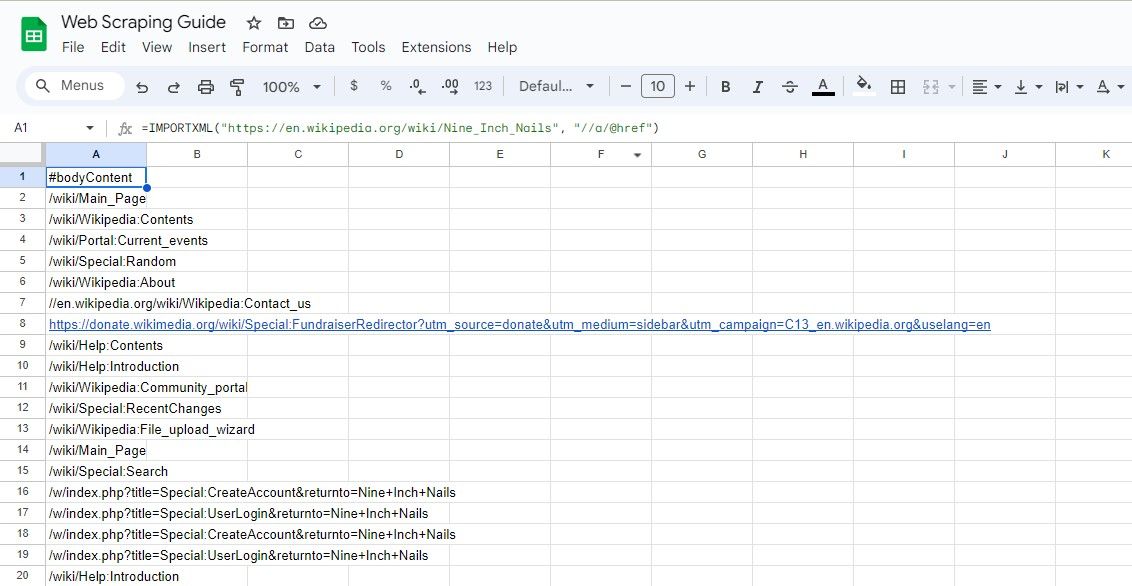
1. Собрать все ссылки (URL)
=IMPORTXML(url, "//a/@href")Пример:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a/@href")Совет: поместите URL в отдельную ячейку, например A1, и используйте =IMPORTXML($A$1, "//a/@href").
2. Собрать текст ссылок вместе с URL
=IMPORTXML(url, "//a")Формула вернёт набор HTML-элементов . В Google Sheets это представится как текст (тег вместе с содержимым). Чтобы извлечь именно видимый текст, используйте //a/text():
=IMPORTXML($A$1, "//a/text()")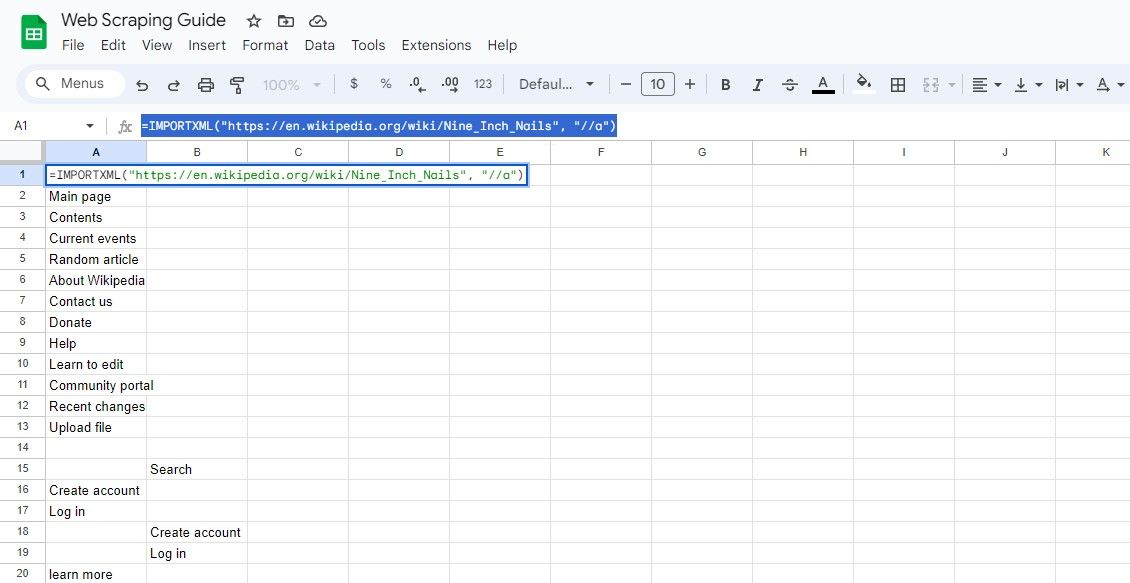
3. Собрать только ссылки с ключевым словом
=IMPORTXML(url, "//a[contains(@href, 'keyword')]/@href")Пример:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//a[contains(@href, 'record')]/@href")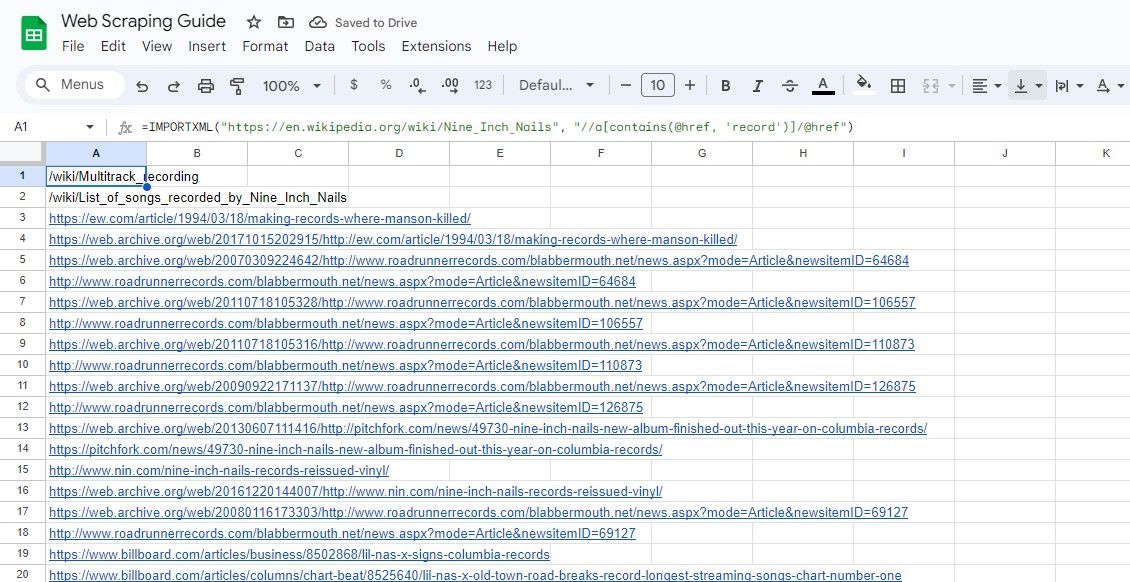
4. Собрать ссылки из конкретного раздела
=IMPORTXML(url, "//div[@class='mw-content-container']//a/@href")Пример:
=IMPORTXML("https://en.wikipedia.org/wiki/Nine_Inch_Nails", "//div[@class='mw-content-container']//a/@href")
Совет: проверьте структуру контейнера (например, id или class) и применяйте более узкие селекторы.
Частые проблемы и когда IMPORTXML не работает
- Динамический контент (JS-rendered): IMPORTXML видит только исходный HTML, отправляемый сервером. Если страница загружает содержимое через JavaScript (AJAX, SPA), функция вернёт пустой или неполный результат.
- Блокировка по CORS или robots.txt: Google не будет нарушать политики сайтов, а сервер может блокировать запросы Google.
- Ограничения частоты и кеширование: Google иногда кэширует или ограничивает частые запросы. Множественные IMPORTXML на одной странице могут вернуть ошибки.
- Неправильный XPath: скопированный абсолютный путь может устареть при малейших изменениях HTML.
- Относительные URL: IMPORTXML вернёт относительные ссылки (например, /wiki/Page). Придётся приводить их к абсолютному виду.
Как диагностировать ошибки
- Если формула возвращает #N/A или пусто, сначала вставьте URL напрямую в браузер и посмотрите исходный код (Ctrl+U).
- Проверьте результат XPath в инструментах разработчика — используйте консоль XPath в браузере.
- Попробуйте более общий XPath:
//a[contains(@href,'record')]вместо длинного абсолютного пути.
Альтернативы и обходные пути
- IMPORTHTML и IMPORTDATA: работают для таблиц и CSV.
- Apps Script (Google Apps Script): можно отправить HTTP-запрос, выполнить рендеринг или использовать headless-браузер (через внешние сервисы) и вставить результаты в лист.
- Внешние инструменты: Python (requests + BeautifulSoup), Puppeteer/Playwright (для JS), Scrapy или облачные сервисы (Apify, Octoparse).
- API сайта: если сайт предлагает API — пользуйтесь им, это надежнее и законнее.
Мини-правило: сначала попробуйте IMPORTXML; если даёт неполные данные — переходите к Apps Script или headless-решению.
Практическая методология: шаг за шагом
- Сформулируйте цель: какие поля нужны (URL, текст ссылки, дата, цена и т.д.).
- Проверьте исходный HTML (Ctrl+U) — есть ли данные в исходном коде? Если да — IMPORTXML подходит.
- Найдите устойчивые селекторы (id, class, атрибуты data-*).
- Напишите XPath, протестируйте в консоли разработчика.
- Положите URL в ячейку A1, XPath в B1, формулы в C1:
=IMPORTXML($A$1,$B$1). - Обработайте результаты: очистка, удаление дубликатов, приведение относительных ссылок к абсолютным.
- Добавьте проверки и логирование (дату обновления, количество строк).
Практические сниппеты и полезные формулы
- Преобразовать относительные ссылки в абсолютные (если домен в ячейке D1):
=ARRAYFORMULA(IF(LEFT(A2:A,1)="/", D1 & A2:A, A2:A))- Очистить пробелы и нормализовать текст:
=ARRAYFORMULA(TRIM(SUBSTITUTE(A2:A, CHAR(160), " ")))- Удалить дубликаты:
=UNIQUE(A2:A)- Ограничение по числу результатов (например, первые 50):
=INDEX(IMPORTXML($A$1,"//a/@href"), SEQUENCE(50), 1)Рекомендации по производительности и устойчивости
- Используйте меньшее число IMPORTXML на одном листе; объединяйте запросы, если возможно.
- Кешируйте результаты: используйте копию листа или Apps Script для периодического обновления (каждые N часов).
- Обрабатывайте ошибки через IFERROR и проверяйте количество строк перед дальнейшими преобразованиями.
- Учитывайте задержки: добавляйте таймауты в Apps Script или встраивайте ожидание между запросами на уровне сервиса.
Юридические и этические замечания
- Соблюдайте условия использования сайта и robots.txt. Не собирайте персональные данные без правовой основы.
- Если вы планируете массовый сбор данных, проверьте требования GDPR/Закон о персональных данных для вашей юрисдикции.
- Предпочитайте API владельца сайта, если он доступен — это безопаснее и менее ресурсозатратно для сервера.
Рольные чек-листы
Маркетолог:
- Определил цели (CTR/ссылки/темы).
- Составил список страниц для скрейпинга.
- Проверил, доступны ли нужные данные в исходном HTML.
- Собрал ссылки/тексты и провел первичный анализ в Sheets.
Аналитик:
- Настроил очистку и нормализацию данных.
- Объединил данные с внутренними источниками (UTM/CRM).
- Настроил мониторинг изменений (дата обновления).
Разработчик:
- Подготовил Apps Script или внешний скрипт для сложных случаев.
- Настроил обработку JS-рендеринга через headless-браузер.
- Обеспечил логирование ошибок и повторные попытки.
Критерии приёмки (что считать успешным скрейпингом)
- Все целевые поля собраны для ≥95% страниц выборки.
- Нет дубликатов в финальном наборе.
- Все относительные URL приведены к абсолютным.
- Есть дата последнего обновления и число успешных/ошибочных запросов.
Тестовые случаи и приемочные проверки
- Тест 1: Страница без JavaScript — IMPORTXML возвращает >0 результатов.
- Тест 2: Страница с динамическим контентом — IMPORTXML возвращает пусто; альтернативный метод (Apps Script + render) возвращает данные.
- Тест 3: Набор из 100 URL — собран хотя бы 95% целевых полей.
- Тест 4: Относительные ссылки корректно преобразуются в абсолютные домены.
Когда лучше не использовать IMPORTXML (примеры)
- Порталы вакансий, которые рендерят блоки через JS и активно блокируют scraping.
- Сайты с частыми динамическими изменениями DOM — XPath быстро сломается.
- Если нужен большой масштаб (тысячи страниц), лучше автоматизировать вне Sheets.
Decision flow (краткое дерево принятия решения)
flowchart TD
A[Нужно собрать данные с веба?] --> B{Данные есть в исходном HTML?}
B -- Да --> C[Использовать IMPORTXML/IMPORTHTML]
B -- Нет --> D{Может ли сайт предоставить API?}
D -- Да --> E[Использовать API]
D -- Нет --> F[Использовать Apps Script или headless-браузер]
C --> G[Проверить XPath, кеш, лимиты]
F --> G
E --> GБезопасность и приватность
- Не храните чувствительные личные данные в общедоступных листах.
- Если собираете пользовательские данные, документируйте правовую базу и срок хранения.
- Ограничьте доступ к листу и используйте аудит доступа в G Suite/Google Workspace.
Примеры: полная рабочая схема для таблицы
- Лист «Input»: столбец A — URL, столбец B — XPath.
- Лист «Raw»: C2:
=IMPORTXML(Input!A2, Input!B2)и вниз по диапазону. - Лист «Clean»: приведение относительных ссылок, TRIM, UNIQUE.
- Лист «Report»: сводная таблица по доменам, частоте ссылок, датам обновлений.
Частые ошибки и как их исправлять
- Ошибка: пустой результат — проверьте исходный HTML.
- Ошибка: #N/A — возможно, Google ограничил доступ; попробуйте подождать или уменьшить частоту обновлений.
- Проблема: дубликаты — используйте UNIQUE или QUERY для агрегирования.
Короткая шпаргалка XPath для веб-аналитика
- Все ссылки:
//a/@href - Текст параграфов:
//p/text() - Заголовки H1:
//h1/text() - Кнопки с классом btn:
//button[contains(@class,'btn')] - Элементы с data-атрибутом:
//*[@data-id]
Часто задаваемые вопросы
Что делать, если IMPORTXML возвращает пусто?
Проверьте исходный HTML страницы (Ctrl+U). Если данные появляются только после выполнения JavaScript, IMPORTXML не подойдёт. Используйте Apps Script с headless-рендерингом или внешние инструменты.
Можно ли автоматизировать регулярный сбор?
Да. Для стабильного ежечасного/ежедневного сбора используйте Apps Script (Timed Triggers) либо внешние ETL-системы и обновляйте Google Sheet через API.
Как работать с JavaScript-генерируемым контентом?
Варианты: 1) найти API, который использует страница; 2) использовать headless-браузер (Puppeteer/Playwright); 3) запускать серверный скрипт и записывать результаты в таблицу.
Короткое резюме
IMPORTXML — мощный инструмент для быстрого сбора данных из статического HTML прямо в Google Sheets. Он идеален для малого и среднего объёма задач: сбор ссылок, текстов, таблиц. При работе учитывайте ограничение на динамический контент и возможные блокировки. Для устойчивых и масштабных решений комбинируйте Sheets с Apps Script или внешними инструментами.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
