Установка одного узла Apache Hadoop на Ubuntu 20.04

Введение
Apache Hadoop — это открытая платформа для хранения и распределённой обработки больших данных в кластере. Основные компоненты:
- Hadoop Common — утилиты и библиотеки, общие для всех модулей.
- HDFS (Hadoop Distributed File System) — распределённая файловая система.
- MapReduce — фреймворк для пакетной обработки больших объёмов данных.
- YARN (Yet Another Resource Negotiator) — диспетчер ресурсов кластера.
В этом руководстве показана установка и базовая конфигурация однозвенного кластера Hadoop на Ubuntu 20.04. Под однозвенным кластером понимается установка всех ролей (NameNode, DataNode, ResourceManager, NodeManager и т.д.) на одной виртуальной или физической машине — удобный вариант для тестирования и разработки.
Что нужно знать перед началом
- Минимальные требования: Ubuntu 20.04, 4 ГБ ОЗУ (рекомендуется больше для тестовой нагрузки).
- Нужен доступ с правами root или возможность sudo.
- В этом руководстве используется Hadoop 3.2.1 и OpenJDK 11.
Важно: однозвенный кластер не предназначен для продакшена. Для боевой эксплуатации используйте многозвенную схему с репликацией и мониторингом.
Содержание
- Предварительные требования
- Обновление системы
- Установка Java
- Создание пользователя hadoop и настройка SSH без пароля
- Установка Hadoop 3.2.1
- Настройка переменных окружения и конфигурационных файлов
- Форматирование NameNode и запуск кластера
- Доступ к веб-интерфейсам
- Чеклисты и проверка приёмки
- Советы по безопасности и миграции в многозвенный кластер
- Часто задаваемые вопросы
Предварительные требования
- Сервер с Ubuntu 20.04, 4 ГБ ОЗУ или больше.
- Настроен root-пароль или пользователь с sudo.
- Доступ в интернет для скачивания пакетов и архивов.
Обновление системных пакетов
Перед установкой обновите систему:
apt-get update -y
apt-get upgrade -yПосле обновления рекомендуется перезагрузка, чтобы все изменения вступили в силу.
Установка Java
Hadoop — Java-приложение, поэтому требуется JDK/JRE. Установите OpenJDK 11:
apt-get install default-jdk default-jre -yПроверьте версию:
java -versionОжидаемый вывод (пример):
openjdk version "11.0.7" 2020-04-14
OpenJDK Runtime Environment (build 11.0.7+10-post-Ubuntu-3ubuntu1)
OpenJDK 64-Bit Server VM (build 11.0.7+10-post-Ubuntu-3ubuntu1, mixed mode, sharing)Если версия отличается, убедитесь, что путь к JAVA_HOME соответствует установленной версии.
Создание пользователя hadoop и настройка SSH без пароля
- Создайте системного пользователя hadoop:
adduser hadoop- Добавьте пользователя в группу sudo:
usermod -aG sudo hadoop- Переключитесь на пользователя hadoop и создайте SSH-ключи:
su - hadoop
ssh-keygen -t rsaПри создании ключей можно оставить passphrase пустым для упрощения автоматизации (в тестовой среде). Затем добавьте публичный ключ в authorized_keys и задайте права:
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysПроверьте соединение без пароля:
ssh localhostЕсли вход проходит без запроса пароля — SSH настроен корректно.
Установка Hadoop
- Скачайте архив Hadoop 3.2.1 (в примере используется официальное зеркало Apache):
su - hadoop
wget https://downloads.apache.org/hadoop/common/hadoop-3.2.1/hadoop-3.2.1.tar.gz- Распакуйте и переместите в /usr/local:
tar -xvzf hadoop-3.2.1.tar.gz
sudo mv hadoop-3.2.1 /usr/local/hadoop
sudo mkdir /usr/local/hadoop/logs
sudo chown -R hadoop:hadoop /usr/local/hadoop- Настройте переменные окружения пользователя hadoop (прибавьте в ~/.bashrc):
nano ~/.bashrcДобавьте:
export HADOOP_HOME=/usr/local/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native"Сохраните и примените:
source ~/.bashrcКонфигурация Hadoop (один узел)
Далее произведём минимальную настройку для работы всех компонентов на одной машине.
Определение Java в hadoop-env.sh
Найдите путь к javac и определите JAVA_HOME в конфигурации Hadoop:
which javac
readlink -f /usr/bin/javac
sudo nano $HADOOP_HOME/etc/hadoop/hadoop-env.shДобавьте (пример пути для OpenJDK 11):
export JAVA_HOME=/usr/lib/jvm/java-11-openjdk-amd64
export HADOOP_CLASSPATH+=" $HADOOP_HOME/lib/*.jar"Примечание: путь к JAVA_HOME может отличаться в зависимости от дистрибутива и версии JDK. Используйте вывод readlink для точного определения.
Дополнительно загрузите javax.activation-api, если этого требует ваша версия Hadoop/MapReduce:
cd /usr/local/hadoop/lib
sudo wget https://jcenter.bintray.com/javax/activation/javax.activation-api/1.2.0/javax.activation-api-1.2.0.jarПроверьте версию Hadoop:
hadoop versionОжидаемый результат содержит строку “Hadoop 3.2.1” и путь /usr/local/hadoop.
core-site.xml — указание URI файловой системы
Отредактируйте $HADOOP_HOME/etc/hadoop/core-site.xml и укажите URI NameNode:
sudo nano $HADOOP_HOME/etc/hadoop/core-site.xmlДобавьте:
fs.default.name
hdfs://0.0.0.0:9000
The default file system URI
Фактический адрес NameNode в продакшене должен быть IP или hostname управляющего узла.
hdfs-site.xml — директории для метаданных
Создайте каталоги для NameNode и DataNode и задайте права:
sudo mkdir -p /home/hadoop/hdfs/{namenode,datanode}
sudo chown -R hadoop:hadoop /home/hadoop/hdfsОтредактируйте $HADOOP_HOME/etc/hadoop/hdfs-site.xml:
sudo nano $HADOOP_HOME/etc/hadoop/hdfs-site.xmlДобавьте:
dfs.replication
1
dfs.name.dir
file:///home/hadoop/hdfs/namenode
dfs.data.dir
file:///home/hadoop/hdfs/datanode
Обратите внимание: dfs.replication=1 подходит для однозвенной среды. В кластере с несколькими узлами значение должно быть ≥2.
mapred-site.xml — MapReduce через YARN
sudo nano $HADOOP_HOME/etc/hadoop/mapred-site.xmlДобавьте:
mapreduce.framework.name
yarn
yarn-site.xml — настройки YARN
sudo nano $HADOOP_HOME/etc/hadoop/yarn-site.xmlДобавьте:
yarn.nodemanager.aux-services
mapreduce_shuffle
Форматирование NameNode
Перед первым запуском нужно отформатировать HDFS NameNode:
su - hadoop
hdfs namenode -formatВ выводе вы увидите сообщения о создании FSImage и успешном форматировании каталога /home/hadoop/hdfs/namenode.
Запуск кластера
Запустите DFS (NameNode, DataNode и SecondaryNameNode):
start-dfs.shЗапустите YARN (ResourceManager и NodeManager):
start-yarn.shПроверьте запущенные Java-процессы Hadoop:
jpsОжидаемые процессы: NameNode, DataNode, SecondaryNameNode, ResourceManager, NodeManager и Jps.
Веб-интерфейсы
- NameNode UI: http://your-server-ip:9870 — основная панель HDFS.
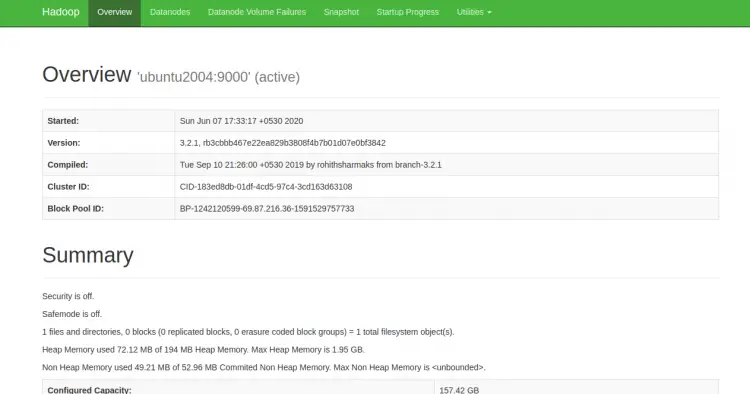
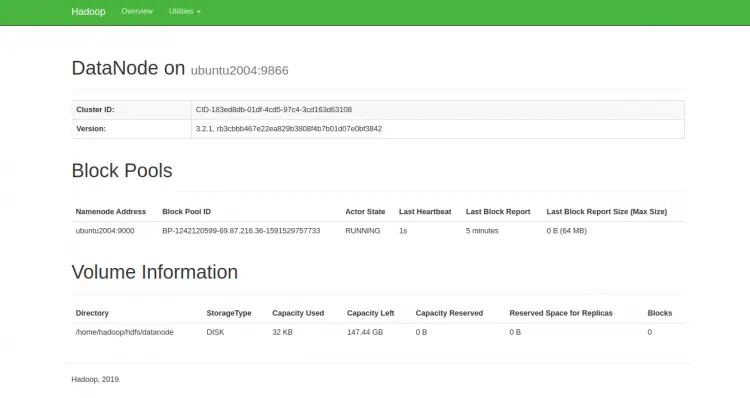
- DataNode UI: http://your-server-ip:9864 — информация по DataNode.
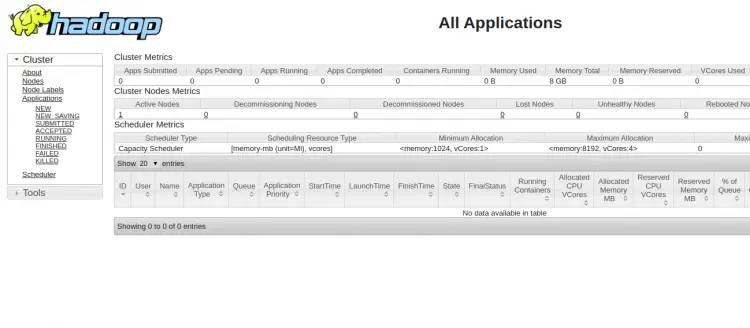
- YARN ResourceManager: http://your-server-ip:8088 — управление приложениями YARN.
Замените your-server-ip на IP вашей машины или используйте localhost для локальной проверки.
Проверочные команды (cheat sheet)
- Проверка версий:
hadoop version
java -version- Проверка HDFS:
hdfs dfs -ls /
hdfs dfs -mkdir /user/hadoop
hdfs dfs -put somefile /user/hadoop/
hdfs dfs -cat /user/hadoop/somefile- Остановка и перезапуск:
stop-yarn.sh
stop-dfs.sh
start-dfs.sh
start-yarn.shЧеклист приёмки (KPI простая проверка)
- java -version возвращает корректную версию (OpenJDK 11+).
- hadoop version показывает Hadoop 3.2.1.
- ssh localhost выполняется без пароля для пользователя hadoop.
- jps демонстрирует NameNode, DataNode, SecondaryNameNode, ResourceManager и NodeManager.
- NameNode UI доступен на порту 9870.
- YARN UI доступен на порту 8088.
- Можно записать и прочитать файл через HDFS (hdfs dfs -put / -cat).
Критерии приёмки: все пункты чеклиста должны быть отмечены.
Советы по безопасности и эксплуатации
- Ограничьте доступ к веб-интерфейсам (9870, 9864, 8088) через брандмауэр (ufw/iptables) или проксируйте за аутентификацией.
- Для production используйте отдельные сервисные учётные записи с минимальными правами.
- Настройте логирование, ротацию логов и мониторинг (Prometheus/Grafana или встроенные метрики).
- В продакшене установите dfs.replication ≥2 и распределяйте DataNode на разные аппаратные узлы.
- Обновляйте Java и Hadoop в тестовой среде перед применением в продакшене.
Миграция в многозвенный кластер — мини-методология
- Планирование инфраструктуры: выделите отдельные узлы для NameNode(s), ResourceManager, DataNode, ZooKeeper (если требуется).
- Настройте сетевую доступность и hostnames.
- Экспортируйте данные с однозвенного HDFS и скопируйте на новый кластер или настройте безопасную репликацию.
- Настройте dfs.replication и политики отказоустойчивости.
- Тестирование: запуск рабочих нагрузок, тесты отказа узлов.
- Переключение рабочих нагрузок на новый кластер поэтапно.
Когда этот подход не подходит (контрпримеры)
- Если вам нужна высокая доступность: однозвенная схема не обеспечивает отказоустойчивости (нет реплик).
- Если ожидается большая нагрузка и много параллельных задач — нужны распределённые ресурсы и настройка YARN на кластере.
- Для чувствительных данных потребуется настройка шифрования и интеграция с системами управления доступом.
Роли и базовый чеклист для команды
Администратор:
- Установить Java, создать пользователя hadoop, настроить SSH.
- Настроить переменные окружения и корректные разрешения каталогов.
Разработчик:
- Проверить запуск тестовой MapReduce-работы.
- Убедиться в доступности HDFS и YARN UI.
Инженер по безопасности:
- Закрыть неиспользуемые порты и настроить аутентификацию/авторизацию.
Быстрые тест-кейсы и приёмка
- Создание каталога в HDFS: hdfs dfs -mkdir /test — ожидаемый результат: директория создана.
- Загрузка файла и чтение: hdfs dfs -put /etc/hosts /test && hdfs dfs -cat /test/hosts — ожидаемый результат: содержимое файла соответствует локальному.
- Запуск sample MapReduce job (по желанию): hadoop jar $HADOOP_HOME/share/hadoop/mapreduce/hadoop-mapreduce-examples-*.jar grep input output “dfs[a-z.]+” — проверить выполнение в YARN UI.
Часто задаваемые вопросы
В: Можно ли использовать этот однозвенный кластер в продакшене?
A: Нет. Однозвенный кластер подходит только для тестов и разработки. Для продакшена нужна многозвенная архитектура, репликация и HA (High Availability).
В: Что делать, если hdfs namenode -format выдаёт ошибку доступа?
A: Проверьте владельца и права на каталог, указанный в dfs.name.dir (обычно /home/hadoop/hdfs/namenode). Владельцем должен быть hadoop: sudo chown -R hadoop:hadoop /home/hadoop/hdfs.
В: Как изменить порт NameNode 9000 или веб-интерфейс 9870?
A: Порт FS URI меняется в core-site.xml (fs.default.name). Веб-порты настраиваются через соответствующие свойства в hdfs-site.xml и yarn-site.xml (см. документацию Hadoop).
В: Нужен ли отдельный ZooKeeper?
A: Для базовой однозвенной установки — нет. Для HA и некоторых приложений (например, HBase) ZooKeeper обязателен.
Риски и дополнительные замечания
- Риск потери данных: при dfs.replication=1 данные потеряются при отказе диска. Решение: увеличить репликацию и использовать резервное копирование.
- Безопасность: веб-интерфейсы по умолчанию не защищены; защитите их через VPN/файрвол или прокси с аутентификацией.
Заключение
Вы установили и запустили однозвенный кластер Hadoop на Ubuntu 20.04. Теперь можно изучать HDFS-команды, запускать примеры MapReduce и планировать переход в многозвенную архитектуру для боевого использования. Если нужны дополнительные инструкции (HA, Kerberos, настройка мониторинга или миграция), спросите — подготовлю последовательный план.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
