Почему при выключении Linux появляется «A stop job is running» и как сократить ожидание

Что означает сообщение
Когда вы выбираете выключение или перезагрузку, systemd посылает каждому работающему процессу сигнал SIGTERM — вежливую просьбу завершиться. Большинство приложений сохраняют состояние и закрывают файлы. Если процесс игнорирует SIGTERM или требует дополнительного времени для завершения операций ввода/вывода (например, снятие снимка БД, размонтирование сетевого тома), systemd ждёт ограниченное время.
Если служба не завершилась в отведённый период, systemd применяет SIGKILL и принудительно завершает процесс, продолжая процедуру выключения. Эта пауза — преднамеренная мера, чтобы предотвратить потерю данных и повреждение файловых систем.
Термины в одну строку:
- SIGTERM — мягкий запрос на завершение процесса; даёт приложению шанс корректно закрыться.
- SIGKILL — немедленное принудительное завершение процесса; данные могут быть потеряны.
Почему это защита, а не баг
Systemd даёт сервисам паузу, чтобы завершить транзакции, синхронизировать данные на диск и корректно размонтировать файловые системы. Без этой паузы вы рискуете получить:
- повреждённые базы данных или журнал транзакций;
- незавершённые записи на внешний диск;
- повреждённые образа контейнеров или виртуальных машин;
- оставшиеся монтирования, требующие fsck при следующем старте.
Поэтому то, что кажется задержкой, зачастую предотвращает серьёзные проблемы.
Как уменьшить стандартный таймаут
По умолчанию systemd ждёт примерно 90 секунд. Если на вашем компьютере это слишком долго, можно изменить глобальный параметр DefaultTimeoutStopSec в конфиге systemd.
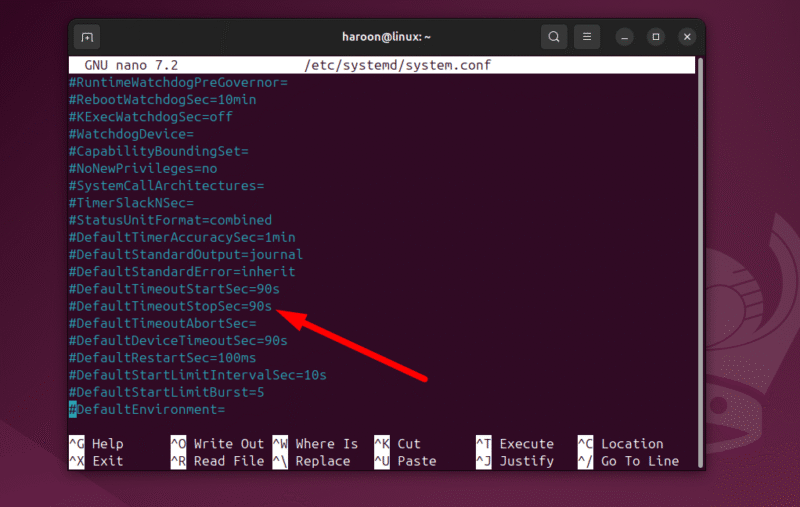
- Откройте файл настроек в редакторе с правами root:
sudo nano /etc/systemd/system.conf- Найдите строку, похожую на
#DefaultTimeoutStopSec=90s. Уберите#и измените значение, например на20sили30s:
DefaultTimeoutStopSec=30sПредупреждение: не устанавливайте значение в 0 — в systemd это может интерпретироваться по-разному и привести к нежелательным эффектам. Значение 20–30 секунд — практичный компромисс для большинства десктопов.
- Сохраните файл и перезагрузите систему. Изменение вступит в силу после следующей загрузки.
Пример быстрой правки через sed:
sudo sed -i 's/#DefaultTimeoutStopSec=.*/DefaultTimeoutStopSec=30s/' /etc/systemd/system.confЗамечание: в редких сборках также может понадобиться отредактировать DefaultDeviceTimeoutSec.
Как найти службу, вызывающую задержку
Если проблема появляется регулярно и на однотипных службах, лучше найти корень и исправить его, а не просто уменьшать таймаут. После медленного выключения перезагрузитесь и просмотрите логи предыдущего запуска:
journalctl -b -1 -eЭта команда покажет сообщения предыдущего сеанса и сразу переместит вас в конец лога. Для вывода предупреждений:
journalctl -b -1 -p warningЧтобы получить статус конкретной службы (замените name.service):
journalctl -u name.service -b -1
systemctl status name.serviceДля анализа служб, которые долго загружаются, полезна команда:
systemd-analyze blameХотя она ориентирована на старт, медленные старты часто коррелируют с долгими остановками.
Другие команды для диагностики:
systemctl list-jobs # показать активные задания systemd
mount | column -t # посмотреть монтированные тома
lsblk # состояние блоков и дисков
Альтернативные подходы и настройки юнита
Если определённый сервис постоянно вызывает задержки, у него можно настроить параметры в его юните вместо глобального снижения таймаута.
- Локальная переопределяющая конфигурация юнита (без правки основного файла):
sudo systemctl edit name.serviceВ открывшемся редакторе добавьте:
[Service]
TimeoutStopSec=20s
KillMode=control-groupСохраните. Это создаст переопределение в /etc/systemd/system/name.service.d/override.conf.
- Если служба не нужна при выключении, можно её отключить или замаскировать для теста:
sudo systemctl disable name.service
sudo systemctl mask name.service- Для сетевых монтирований — поместите опции automount и nofail в /etc/fstab, чтобы зависимость не блокировала завершение.
Важно: маскирование или отключение сервиса может снизить функциональность системы. Прежде чем удалять, убедитесь, что вы понимаете зависимость.
Чек-листы для разных ролей
Для пользователя десктопа:
- Убедиться, что внешние диски безопасно извлекаются перед выключением.
- Отключить ненужные автозапускаемые сервисы через GUI или systemctl.
- Если часто используете VPN/сети, завершать соединения вручную.
Для системного администратора:
- Проанализировать
journalctl -b -1и логи проблемных юнитов. - Настроить
TimeoutStopSecдля проблемных сервисов черезsystemctl edit. - Добавить health-check и graceful-stop в сценарии сервисов.
Для девопса/инженера платформы:
- Автоматизировать мониторинг медленных остановов в логах и трекать регрессии.
- Обновить systemd-тайминги в образах/AMI с учётом типа нагрузки.
- Тестировать сценарии аварийного завершения и восстановление данных.
Runbook: как действовать при постоянно медленном выключении
- Перезагрузитесь после долгого выключения и соберите логи:
sudo journalctl -b -1 -u suspect.service -o cat > /tmp/suspect.log- Посмотрите сообщения в конце и временные метки. Ищите слова timeout, failed, sigterm, killed.
- Если это сетевой том — проверьте доступность целевого хоста и конфигурацию /etc/fstab.
- Попробуйте аккуратно остановить сервис вручную и посмотреть, есть ли зависимые процессы:
sudo systemctl stop suspect.service
ps aux | grep -E 'suspect|related'
sudo lsof /path/to/mount- Если процесс не останавливается, временно замаскируйте сервис и проверьте эффект при следующем выключении:
sudo systemctl mask suspect.service- После исправления не забудьте отменить маскирование и восстановить сервисы.
Частые причины и когда простое уменьшение таймаута не поможет
- Сетевые монтирования (NFS, SMB) становятся недоступными — унмонтировать неудобно, пока соединение «висит».
- Базы данных выполняют долгие операции записи или консистентные дампы; принудительное завершение может привести к восстановлению при старте.
- Контейнеры и VM требуют времени для корректной остановки и сохранения состояния.
- Некорректные systemd unit-файлы без настроек Stop/ExecStop.
В таких случаях правильнее исправлять причину (например, добавлять retry/timeout в сеть, настроить automount, оптимизировать завершение БД), а не просто снижать глобальный таймаут.
Факты и ориентиры
- Значение по умолчанию: ~90s (практически встречается в большинстве дистрибутивов с systemd).
- Безопасный диапазон для десктопов: 20–30s.
- Для критичных баз данных и серверов стоит оставить большие таймауты или настраивать индивидуально.
Риски и меры смягчения
Риски при слишком низком таймауте:
- Потеря последних несинхронизированных записей;
- Повреждение файловой системы или базы данных;
- Повторные проверки файловой системы при загрузке.
Меры смягчения:
- На серверах — тестировать и ставить более длительные таймауты для критичных сервисов.
- Делать регулярные бэкапы и проверять восстановление.
- Настроить мониторинг длительности остановки сервисов.
Критерии приёмки
- После внесённых изменений система выключается без превышения нового таймаута в 90% тестов (например, 9 из 10 выключений).
- Логи не содержат принудительных SIGKILL для критичных сервисов.
- Данные и файловые системы не требуют ручной проверки или восстановления после перезагрузки.
Короткий глоссарий
- systemd — init-система и менеджер служб в современных дистрибутивах Linux.
- юнит (unit) — конфигурационный файл, описывающий службу, сокет, том или задачу в systemd.
- TimeoutStopSec — параметр, задающий, сколько ждать завершения сервиса при его остановке.
Итог
Сообщение «A stop job is running» — нормальная защитная реакция systemd. Лучший путь — сначала найти и исправить проблему у проблемного сервиса, а затем при необходимости настроить глобальный или локальный таймаут. Понижение таймаута ускорит выключение, но увеличивает риск повреждения данных; меняйте настройки осознанно и тестируйте изменения.
Важно: перед массовыми изменениями на серверах протестируйте поведение в контролируемой среде и убедитесь в наличии резервных копий.
Похожие материалы

Зоны активности HomeKit для камер и звонков

Как выбрать потоковый музыкальный сервис

Мошенничество с клонированием голоса ИИ — как защититься

Как изменить кастомный URL в Steam

Как заменить лицо на фото в Picsart
