Как найти процессы, жрущие RAM и CPU в Linux
TL;DR
- Используйте free, vmstat, top/htop и ps, чтобы быстро найти процессы, потребляющие память и процессор.
- Поймите разницу между кешем, RSS и виртуальной памятью, прежде чем убивать процессы.
- Следуйте пошаговому плану: измерить → локализовать процесс → оценить последствия → корректно завершить (SIGTERM → SIGKILL).
Быстрые ссылки
- Баланс между процессами и ресурсами
- Исследование высокой загрузки памяти
- Команда free
- Чтение /proc/meminfo
- vmstat для поиска потребителей памяти
- top и htop для поиска процессов по памяти
- ps для поиска процессов по памяти
- Исследование высокой загрузки CPU
- top и htop для поиска по CPU
- mpstat для мониторинга CPU
- ps для поиска процессов по CPU
- Небольшая уборка
Введение
Каждая единица кода, запущенная в Linux, требует оперативной памяти (RAM) и процессорного времени (CPU). Процесс, который потребляет больше ресурса, чем положено, замедляет остальные. В этой статье подробно описано, как найти «вредителей», понять, почему они так себя ведут, и безопасно избавиться от них.
Определения в одну строку:
- Процесс: выполняющаяся программа с PID (идентификатором процесса).
- RSS (resident set size): фактическая физическая оперативная память процесса.
- VMS/VIRT: виртуальная адресная область процесса (включает зарезервированную, неиспользуемую память).
- Кеш: свободная память, используемая системой для ускорения операций ввода-вывода; при необходимости её можно освободить.
Баланс между процессами и ресурсами
RAM и CPU — конечные ресурсы. Когда программа выполняется, ядро создаёт процесс и распределяет ресурсы. Помимо ваших приложений, процессы создает сама ОС и графическая оболочка. Задача ядра — справедливо распределять CPU между потоками и обеспечивать выделение памяти по требованию.
Приложения должны корректно освобождать память и не блокировать CPU. Но бывают ошибки, утечки памяти и некорректные алгоритмы, из-за которых процесс начинает «жрать» ресурсы. Чтобы вернуть систему в рабочее состояние, нужно уметь быстро локализовать источник проблемы.
Исследование высокой загрузки памяти
Linux использует свободную RAM как кеш для ускорения доступа к файлам и данным. Поэтому на первый взгляд может показаться, что вся память занята. На самом деле кеш можно освободить при необходимости; это норма.
Важно понять, что именно растёт: кеш или реальное потребление процессов (RSS). Не торопитесь убивать процессы, пока не убедились, что это действительно ошибка.
Команда free
Команда free даёт быстрый снимок использования памяти. Опция -h делает вывод удобочитаемым.
Пример последовательного запуска (как в демонстрации):
free -h
free -h
free -h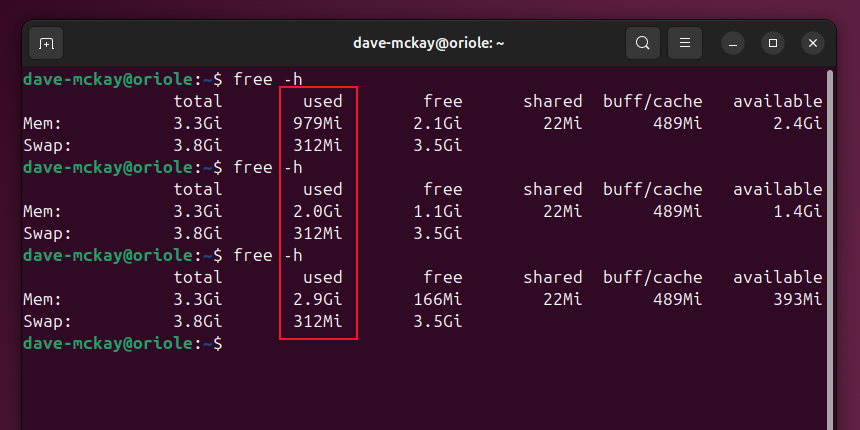
Если вы видите быстро уменьшающуюся строку “available” или “free”, это признак активного расходования памяти. Но сначала проверьте, что растёт: кеш или RSS.
Советы по чтению free:
- available — лучший индикатор реальной доступной памяти для приложений.
- used включает кеш/буферы. Не паникуйте, если used велико, но available тоже приличный.
Чтение /proc/meminfo
Инструменты top и htop берут данные о памяти из /proc/meminfo. Это псевдо-файл, который можно просматривать как текст.
less /proc/meminfo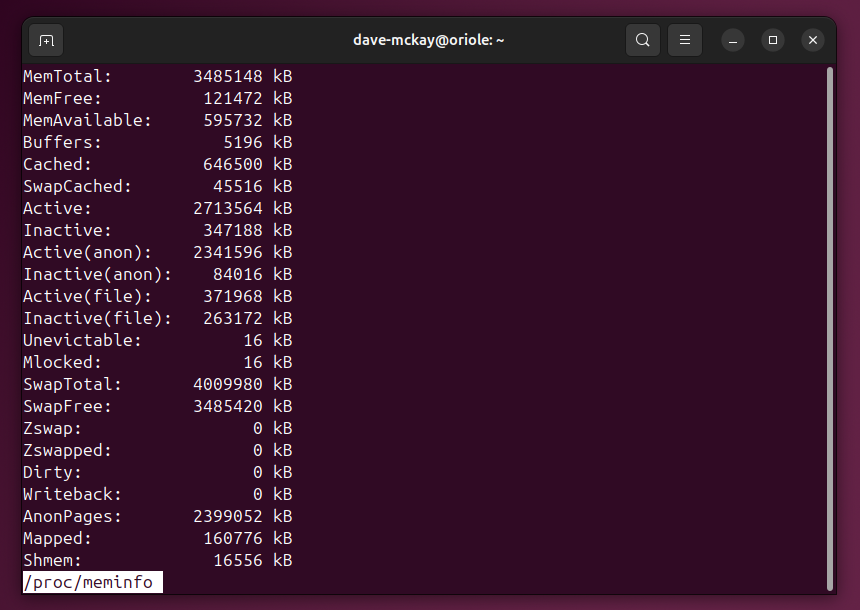
Здесь вы увидите подробные поля: MemTotal, MemFree, Buffers, Cached, SwapTotal, SwapFree и другие. Они зависят от версии ядра и архитектуры, но помогают понять структуру расхода памяти. /proc/meminfo полезен, если хотите точные значения по областям памяти, но он не показывает, какие процессы используют память.
vmstat для поиска потребителей памяти
vmstat показывает статистику виртуальной памяти за выбранный интервал. Оно помогает увидеть тренд, а не только снимок.
Пример: 4 отчёта с интервалом 5 секунд, значения в MiB:
vmstat 5 4 -S M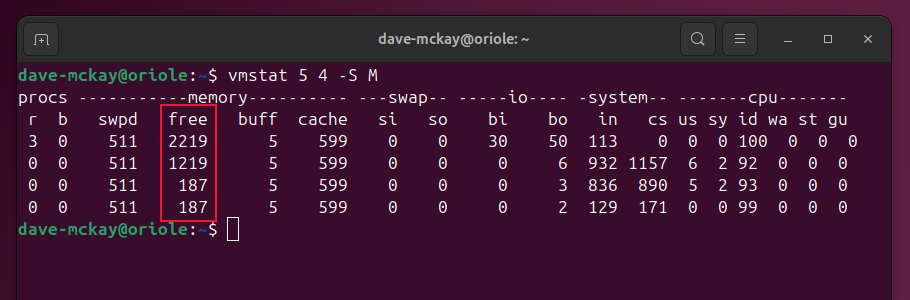
На что смотреть в vmstat:
- free — свободная физическая память.
- buff/cache — память, занятая буферами/кешем.
- si/so — обращение к swap (swap in/out, знак проблем).
Если наблюдается сильный рост si/so — система активно использует swap, и это указывает на недостаток памяти для рабочих процессов.
top и htop для поиска процессов по памяти
top и htop дают динамическую таблицу процессов. В ней каждая строка — отдельный процесс с метриками.
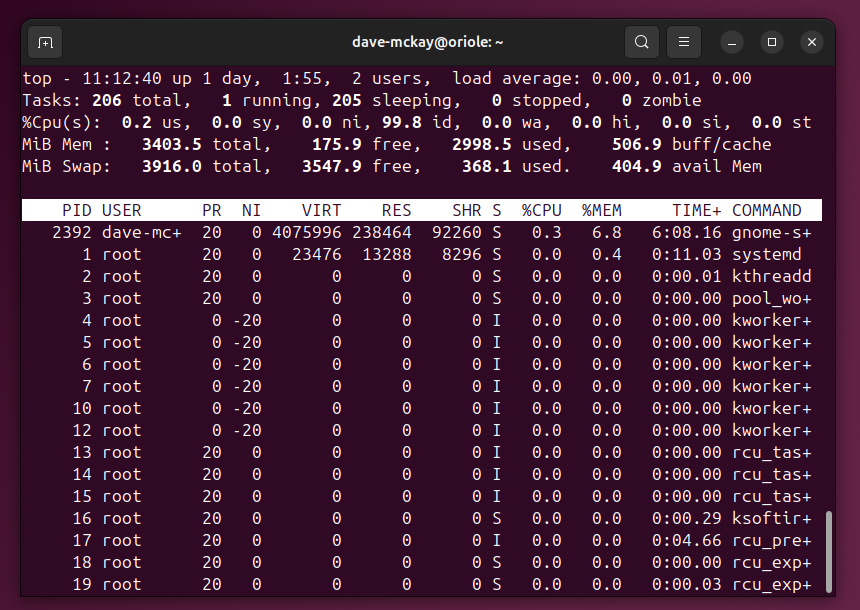
В top нажмите Shift+M, чтобы отсортировать по использованию памяти. В htop можно кликнуть заголовок столбца или нажать F6 для сортировки.
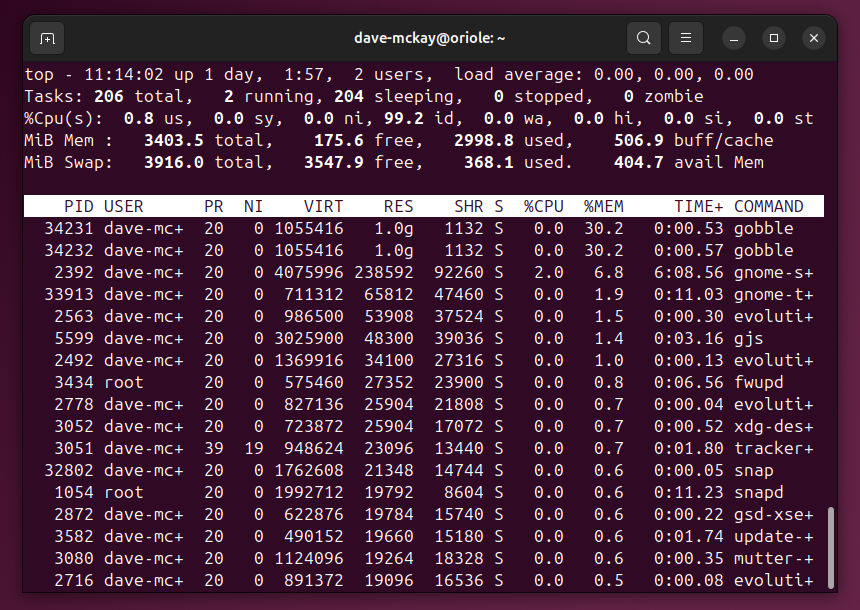
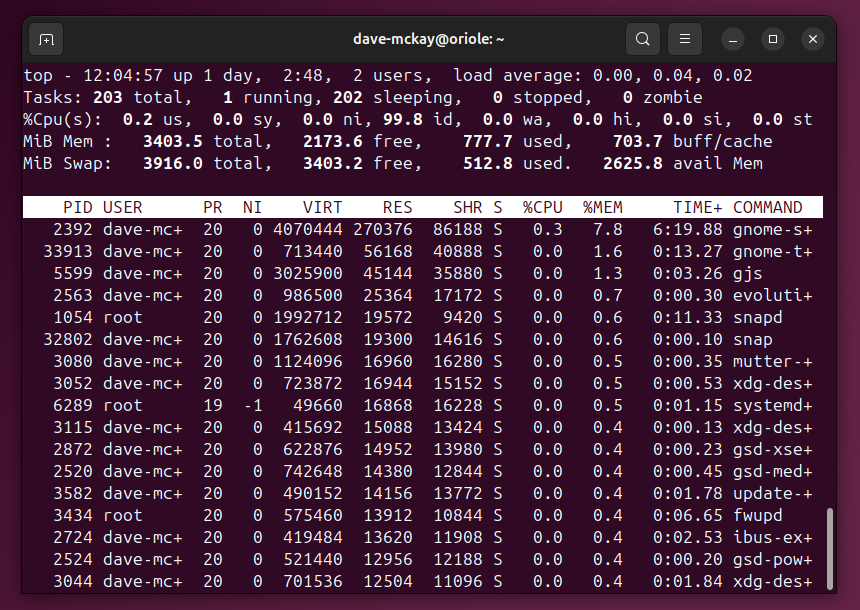
На примере показано приложение gobble, запущенное дважды и занявшее большую часть RAM. Чтобы корректно завершить процесс в top:
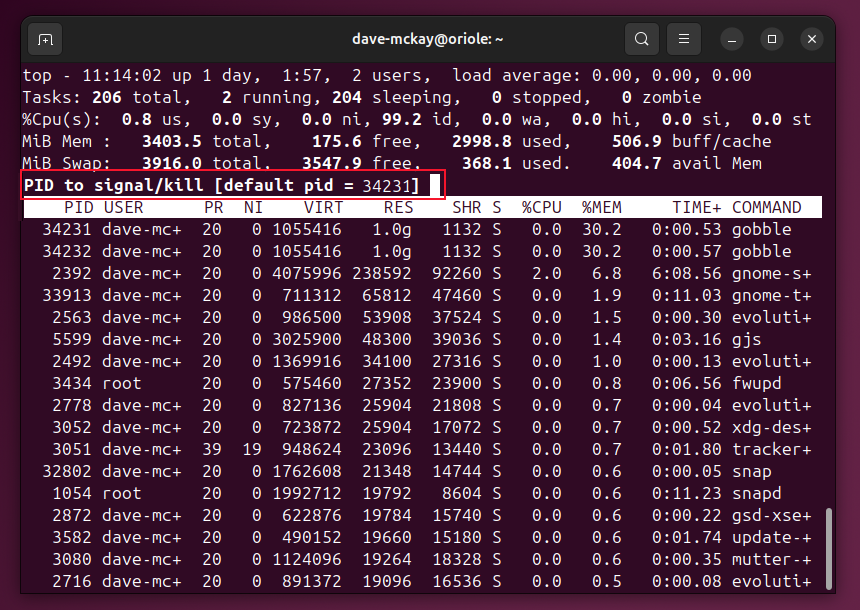
- Нажмите k. Top предложит PID по умолчанию — это процесс в первой строке.
- Нажмите Enter, чтобы принять PID.
- Введите номер сигнала (например, 9 для SIGKILL) и нажмите Enter.
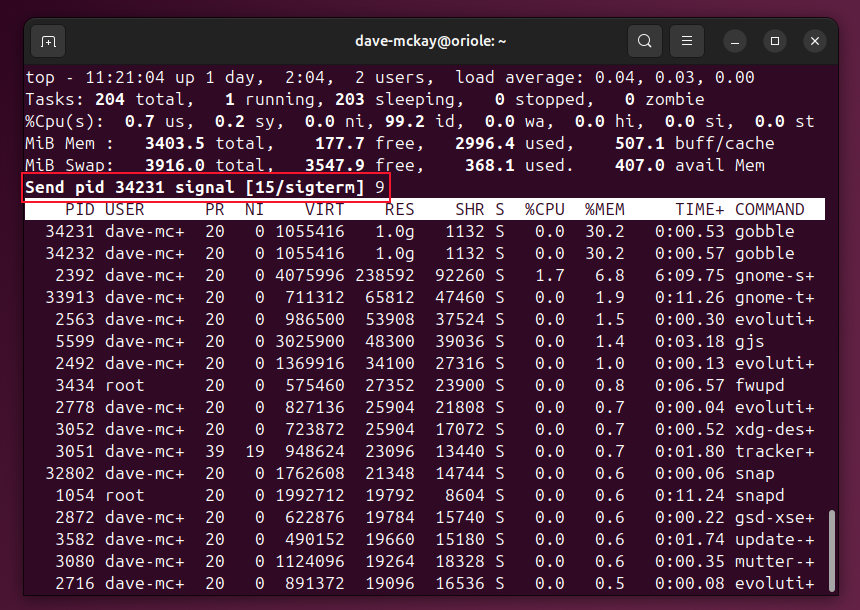
После отправки сигнала оба процесса gobble завершились.
В htop процесс убивают аналогично — переместите курсор, нажмите k, выберите сигнал слева и подтвердите.
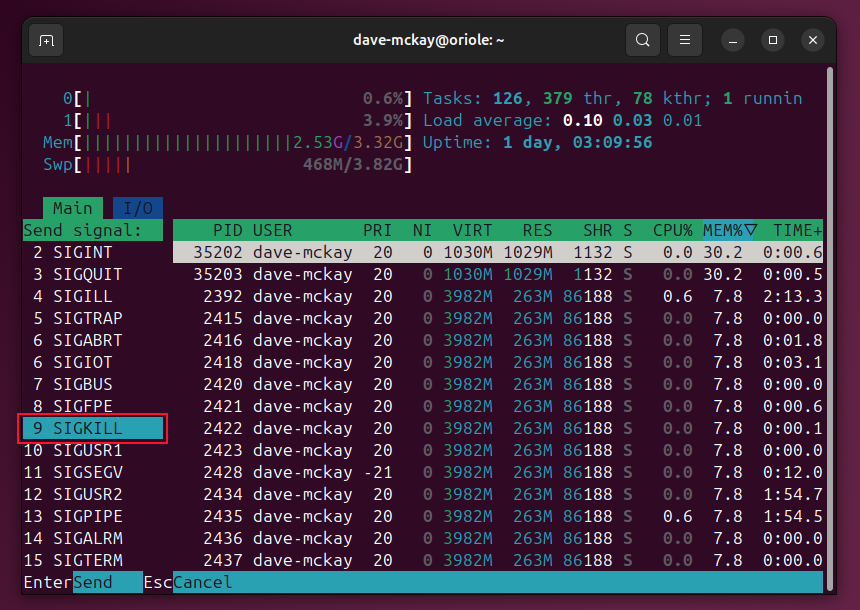
Важно: не торопитесь отправлять SIGKILL. Сначала пробуйте SIGTERM, чтобы процесс мог корректно завершить работу и освободить ресурсы.
ps для поиска процессов по памяти
ps позволяет формировать удобный вывод и сортировать. Мы попросим поля: pid, ppid, comm, %mem, rss, %cpu и отсортируем по памяти.
ps -e -o pid,ppid,comm,%mem,rss,%cpu --sort=-%mem | head -10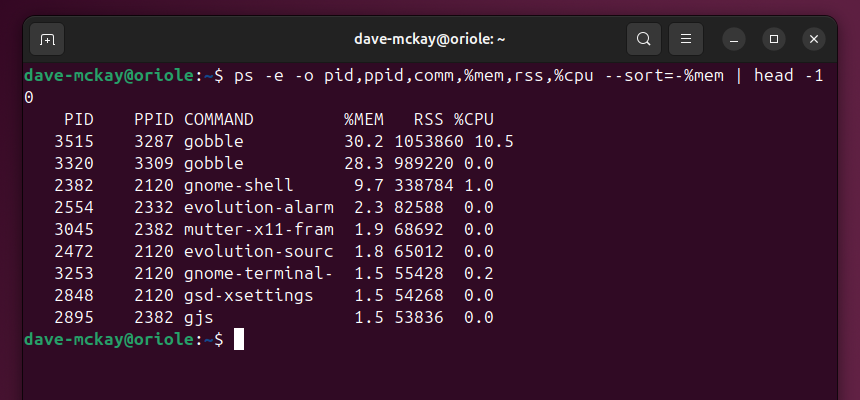
Пояснения к полям вывода:
- pid: идентификатор процесса.
- ppid: идентификатор родительского процесса. Если у многих расходников одинаковый ppid — задумайтесь об убийстве родителя.
- comm: имя команды/процесса.
- %mem: процент от общей памяти.
- rss: реальная физическая память в килобайтах.
- %cpu: накопленная загрузка процессора.
Если вы видите группы процессов с одинаковым ppid, возможно это потомки одного демона или скрипта.
Исследование высокой загрузки CPU
Процедура для CPU похожа на ту, что для памяти. Сначала измеряем, затем локализуем процесс с высокой загрузкой, затем аккуратно завершить или скорректировать его приоритет.
top и htop для поиска по CPU
По умолчанию top и htop сортируют по %CPU. В top, если сортировка изменилась, нажмите Shift+P, чтобы отсортировать по CPU.
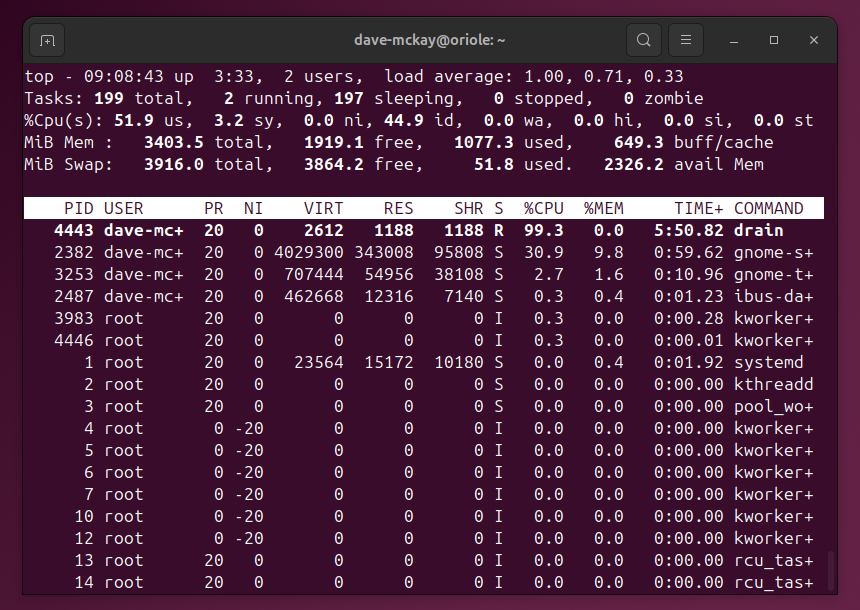
Если процесс монополизирует CPU, определите, можно ли его рестартовать, уменьшить нагрузку или временно приостановить.
Советы по работе с CPU-хогами:
- Примените nice/renice, чтобы снизить приоритет ресурсоёмкого процесса.
- Для ввода-вывода используйте ionice.
- Если процесс системный, уточните его роль перед убийством.
mpstat для мониторинга CPU
mpstat показывает загрузку CPU по категориям (user, system, iowait и др.) и по каждому ядру.
Установка пакета sysstat (содержит mpstat):
- Fedora:
sudo dnf install sysstat- Manjaro:
sudo pacman -S sysstatТипичный запуск: отчёты каждые 2 секунды, 5 отчётов по всем процессорам:
mpstat -P all 2 5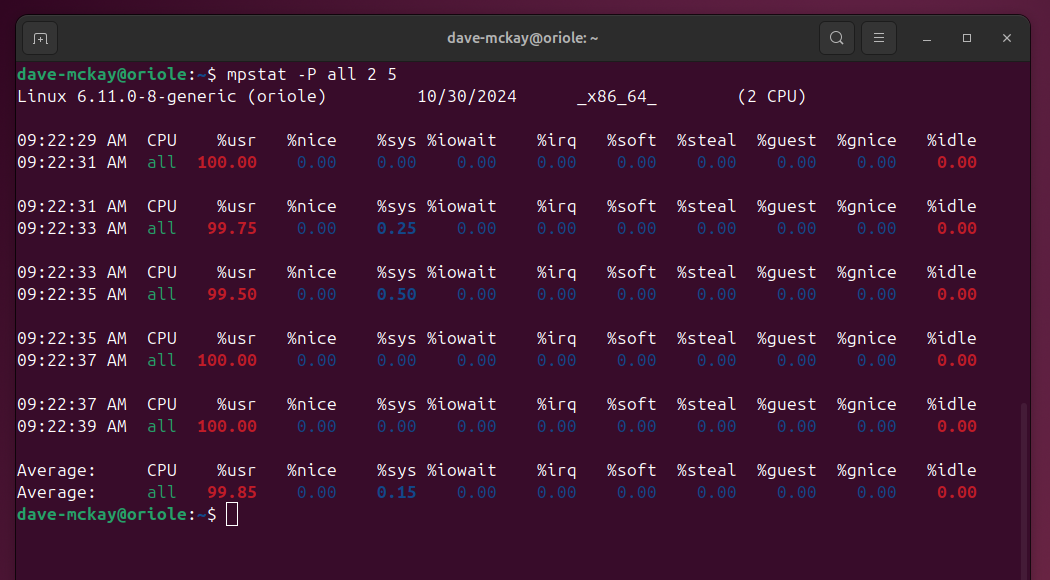
Строка average показывает среднее за заданный интервал. Если load идёт от user, значит ваши приложения; если system — смежные системные вызовы.
ps для поиска по CPU
Сортируем как для памяти, но по CPU:
ps -e -o pid,ppid,comm,%mem,rss,%cpu --sort=-%cpu | head -10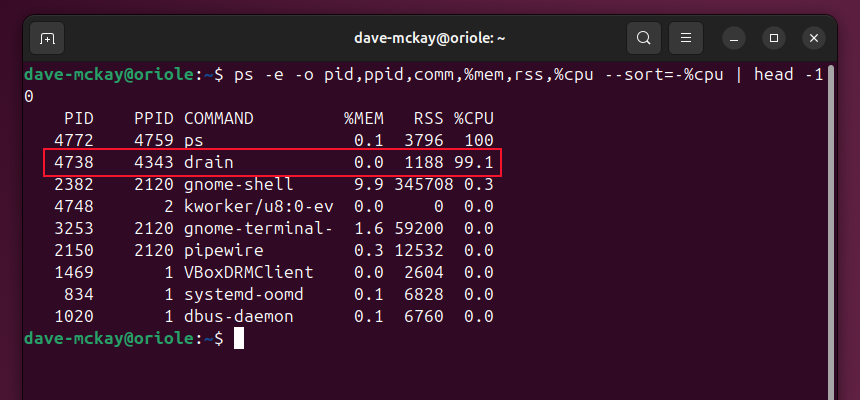
Учитывайте, что ps показывает накопленную CPU-время с момента запуска процесса. Краткосрочные spikes можно лучше увидеть в top/htop.
Дополнительные инструменты и приёмы
- smem — точнее считает потребности памяти по пользовательским и системным разделам.
- pmap /proc/
/maps — показывает карты памяти процесса. - /proc/
/status — детально про состояние процесса и использование ресурсов. - systemd-cgtop — показывает использование ресурсов по cgroup, полезно в контейнеризованных средах.
- cgroups и контейнеры: помните, что ограничение по cgroup может исказить видимость памяти внутри контейнера.
Примеры команд:
smem -k | sort -n -r -k 4 | head -10
pmap -x | less
cat /proc//status | egrep "VmRSS|VmSize|Threads"
systemd-cgtop Как правильно завершать процессы
Стандартный порядок действий перед принудительным завершением:
- Попробуйте дать процессу шанс завершиться: SIGTERM (15).
- Если не помогает и процесс не отвечает — SIGKILL (9).
- Для служб лучше использовать systemctl stop
. - Если убиваете родителя, учтите, что это закроет и детей.
Сигналы, которые часто применяют:
- SIGTERM (15): просит процесс корректно завершиться.
- SIGINT (2): как Ctrl+C, интерактивное прерывание.
- SIGKILL (9): немедленное завершение, процесс не может обработать сигнал.
- SIGHUP (1): обычно означает перезапуск/перечитать конфигурацию.
Не посылайте SIGKILL системным процессам без подготовки. Это может привести к потере данных или падению системы.
Mini-playbook: шаг за шагом
- Замер: free -h, vmstat 5 5, mpstat -P ALL 2 5.
- Локализация памяти: top (Shift+M), ps –sort=-%mem.
- Локализация CPU: top (Shift+P), ps –sort=-%cpu.
- Подтверждение: pmap, /proc/
/status, lsof -p . - Оценка: является ли процесс критичным? Какой риск при завершении?
- Действие: systemctl stop service || kill
(SIGTERM) → wait → SIGKILL как крайняя мера. - Поствольная проверка: снова free, vmstat, top; проверьте логи (/var/log/syslog, journalctl).
Частые ошибки и когда методы не сработают
- Если проблема — утечка в ядре или драйвере, пользовательские kill не помогут.
- Если процесс запускается менеджером (systemd, supervisord), он может автоматически рестартовать службу. Остановите службу через systemctl.
- В контейнерах видимость ресурсов может быть ограничена; проверяйте cgroup-ограничения.
Рекомендации по профилактике
- Настройте мониторинг (Prometheus + node_exporter, Zabbix, Grafana) для раннего оповещения по памяти и CPU.
- Ограничивайте ресурсы cgroups/containers для ненадёжных приложений.
- Автоматически перезапускайте службы только после проверки причин падения (чтобы не зациклить рестарты).
Контроль приоритетов и влияния
- nice/renice: изменяет приоритет планирования CPU (значения -20..19). Чем больше nice, тем ниже приоритет.
- ionice: влияет на планирование ввода-вывода.
Примеры:
renice +10 -p
ionice -c2 -n7 -p Рольовые чек-листы
Для десктоп-пользователя:
- Проверьте free -h, top/htop.
- Закройте ненужные приложения.
- Проверьте браузер на вкладки с высоким потреблением.
- Если не знаете, убейте процесс SIGTERM, затем SIGKILL.
Для системного администратора:
- Проверьте mpstat, vmstat, dmesg/journalctl на OOM или kernel errors.
- Используйте ps/pmap/smem для глубокого анализа.
- Если служба авто-перезапускается, временно отключите рестарт в systemctl.
Для разработчика:
- Воспроизведите утечку на тестовом стенде.
- Используйте профилировщики памяти (valgrind, massif, heap profiler).
- Закройте утечку и мониторьте релиз.
Диагностические сценарии и тест-кейсы
- Симптом: система медленная без явной swap-активности. Тест: top/htop → проверьте load + iowait.
- Симптом: быстрый рост used в free. Тест: vmstat, затем ps –sort=-%mem.
- Симптом: процесс рестартует сам себя. Тест: systemctl status / проверка supervisor.job.
Ментальные модели и эвристики
- “Кеш — не враг”: большое значение used часто означает, что система эффективно использует RAM.
- “RSS важнее VIRT”: смотрите на RSS, чтобы понимать реальное физическое потребление.
- “Не убивай системный процесс без плана”: сначала резервная копия/логирование, затем действие.
Краткая памятка по командам (cheat sheet)
- free -h — быстрый снимок памяти.
- vmstat 5 4 -S M — тренд виртуальной памяти.
- top / htop — интерактивный мониторинг.
- ps -e -o pid,ppid,comm,%mem,rss,%cpu –sort=-%mem | head -10 — 10 крупнейших по памяти.
- ps -e -o pid,ppid,comm,%mem,rss,%cpu –sort=-%cpu | head -10 — 10 крупнейших по CPU.
- pmap -x
— карта памяти процесса. - cat /proc/
/status — детальное состояние процесса. - systemctl stop/start/status
— управлять службами.
Часто задаваемые вопросы
Q: Какой сигнал лучше использовать первым? A: SIGTERM (15).
Q: Что делать, если процесс сразу рестартует? A: Остановите менеджер (systemctl stop) или временно отключите автоперезапуск.
Q: Можно ли очистить кеш вручную? A: Да, но это редко нужно. echo 3 > /proc/sys/vm/drop_caches сбрасывает кешы, но это влияет на производительность I/O.
Сводка
- Измеряйте прежде чем действовать.
- Понимайте, что именно растёт: кеш или RSS.
- Используйте top/htop, ps, vmstat и mpstat для локализации проблемы.
- Завершайте процессы аккуратно: SIGTERM → SIGKILL, и предпочтительно через systemctl для системных служб.
Важно: большинство систем работают нормально без вмешательства. Но при заметной деградации используйте описанный план действий для быстрого восстановления.
Ключевые сведения
- Кеш можно освободить, но лучше позволить системе управлять им.
- RSS указывает реальное физическое использование памяти процессом.
- Swap-интенсивность (si/so) — признак нехватки RAM.
1‑строчный глоссарий
- RSS: физическая RAM процесса.
- VIRT: полная виртуальная память процесса.
- OOM: out-of-memory — ситуация нехватки памяти.
- cgroup: механизм ограничений ресурсов для групп процессов.
Важно: всегда делайте резервные копии и проверьте логи перед критическими действиями по удалению процессов.
Похожие материалы

Снизить нагрузку CPU во время игр

Почему ноутбук тормозит при зарядке — как исправить

Восстановление фото из превью Lightroom

F.lux — автоматическая подстройка цвета экрана

Ошибка регистрации Kindle — как исправить
