Как извлечь текст из изображения: полное руководство по OCR
Введение
В цифровую эпоху изображения постоянно сопровождают нашу работу и личную жизнь. Часто в картинках содержится важная текстовая информация: квитанции, заметки, скриншоты чатов, фото документов. OCR (оптическое распознавание символов) превращает такие изображения в редактируемый и поисковый текст — экономя время и снижая ручной ввод.
Короткое определение: OCR — технология, которая анализирует растровые изображения и преобразует распознаваемые символы в текст.
Важно: выбор инструмента зависит от качества изображения, языка, требований конфиденциальности и формата выходного результата.
Основные варианты и когда их выбирать
- Локальные приложения (например, платные OCR-решения) — когда важна конфиденциальность и высокая точность.
- Облачные сервисы (Google Drive, специализированные API) — когда нужен быстрый результат и масштабируемость.
- Онлайн-инструменты — для единичных задач и удобства без установки.
Способ 1. Gemoo Snap — быстрый десктопный OCR и скриншоты
Gemoo Snap — это приложение для Windows и macOS (есть расширение для Chrome), которое сочетает в себе функцию снимка экрана и встроенный OCR.
Преимущества Gemoo Snap:
- Быстрое распознавание текста прямо со скриншота.
- Поддержка нескольких языков распознавания.
- Встроенный простой редактор распознанного текста и кнопка копирования.
- Интеграция с облаком для хранения скриншотов.
Пошаговая инструкция для Gemoo Snap
- Скачайте и установите Gemoo Snap для вашей ОС или добавьте расширение в Chrome.
- Запустите приложение и выберите функцию “Recognize Text (OCR)” в интерфейсе.
- Укажите код языка вывода (в исходной инструкции использовался EN для английского).
- Выделите область на экране, содержащую текст.
- Просмотрите результат распознавания, отредактируйте при необходимости и скопируйте текст.

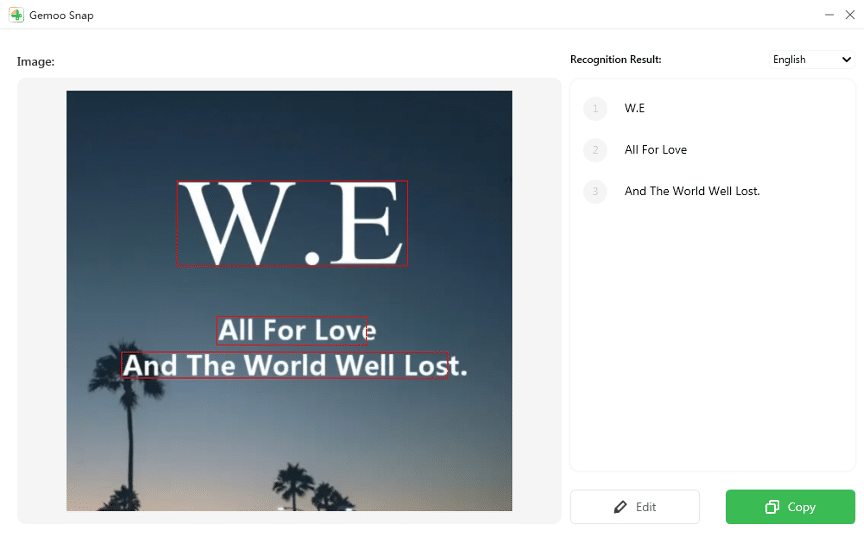
Примечание: для сложных макетов (таблицы, колонки) встроенный редактор может потребовать ручной доработки.
Способ 2. Google Drive / Google Docs — облачный бесплатный путь
Google Drive умеет автоматически распознавать текст в изображениях при открытии их через Google Docs.
Шаги:
- Загрузите изображение в Google Drive.
- Правой кнопкой мыши кликните по файлу и выберите “Открыть с помощью → Google Документы”.
- Документ откроется: над картинкой появится распознанный текст.
- Отредактируйте текст, сохраните или экспортируйте в нужном формате.
Плюсы: доступность, простота, интеграция с редактором и облаком. Минусы: передача данных на сервер Google, возможные ограничения по языкам и форматированию.
Способ 3. Онлайн-инструменты — OCR в браузере
Примеры: Online OCR, Free OCR, OCR.space и другие. Общая схема работы:
- Заходите на сайт → загружаете изображение → выбираете язык → стартуете распознавание → копируете результат.
Когда использовать: если нужно быстро получить текст без установки ПО и без конфиденциальных данных.
Сравнение подходов
| Критерий | Gemoo Snap (локально) | Google Drive (облако) | Онлайн-инструменты |
|---|---|---|---|
| Конфиденциальность | Высокая (локально) | Средняя (облако Google) | Низкая/зависит от сайта |
| Удобство | Высокое | Высокое | Очень быстрое |
| Точность для сложных макетов | Средняя — зависит от редактора | Хорошая | Варьируется |
| Поддержка языков | Несколько | Много | Разная |
Когда OCR не сработает или даст плохой результат
- Низкое качество фотографии: размытость, шум, тени.
- Нестандартные или декоративные шрифты.
- Плохо освещённый текст или сильный контраст с фоном.
- Рукописный текст с неразборчивым почерком.
- Многоуровневые макеты (сканированные книги, сложные таблицы).
В таких случаях потребуется ручная корректировка или альтернативные подходы (см. ниже).
Альтернативные подходы и когда их применять
- Ручной ввод — когда требуется 100% точность для коротких фрагментов.
- Профессиональные услуги транскрипции — для больших объёмов и важной юридической информации.
- Комбинация OCR + постобработка скриптами — для пакетной обработки и восстановления структуры.
- Использование специализированных API (ABBYY, Google Cloud Vision) — для высокого качества и масштабирования.
Ментальные модели и эвристики при выборе инструмента
- Если важна конфиденциальность → выбирайте локальное ПО.
- Если нужна скорость и интеграция с документами → облако/Google Drive.
- Если задача одноразовая и не чувствительна к приватности → онлайн-сервис.
- Для регулярной обработки больших объёмов — API с автоматизацией.
Быстрый метод: чек-лист перед распознаванием
- Убедитесь, что изображение чёткое и правильно ориентировано.
- Обрежьте лишнее пространство, оставьте только текстовую область.
- Выберите правильный язык распознавания.
- Проверьте, нет ли водяных знаков/перекрытий.
- Сравните итоговый текст с оригиналом и исправьте форматирование.
Простой SOP для извлечения текста (шаблон)
- Подготовка: откройте изображение, обрежьте лишние края, сохраните копию.
- Выбор инструмента: выбрать по критериям (конфиденциальность, объём, язык).
- Запуск распознавания: указать язык, при необходимости задать формат вывода.
- Ревью: проверить орфографию, структуру, таблицы.
- Экспорт: сохранить в нужном формате (TXT, DOCX, CSV) и заархивировать/зашифровать при необходимости.
Критерии приёмки
- Все читаемые строки извлечены без искажения содержания.
- Форматирование основных элементов (заголовки, списки, таблицы) восстановлено приемлемо.
- Специальные символы (датировки, номера) распознаны корректно.
- Нет утечки конфиденциальных данных при использовании облака.
Тестовые случаи и примеры проверок
- Чёткий скриншот экрана с текстом на английском — ожидаемый успех.
- Фотография напечатанного документа с плохим освещением — частичные ошибки.
- Рукописная заметка — зависит от разборчивости; скорее всего потребуется ручной ввод.
- Таблица с колонками и заголовками — проверка на соответствие колонок.
Конфиденциальность и правовые замечания
Если изображение содержит персональные данные (имена, номера, адреса), учитывайте законы о защите данных (например, GDPR в ЕС). Для чувствительных данных предпочтительнее локальные решения или подписанные соглашения об обработке данных с поставщиком облачных услуг.
Примеры полезных случаев использования
- Перевод бумажных заметок в цифровые заметки.
- Индексация сканированных договоров для поиска.
- Извлечение текстов из фотографий документов для бухгалтерии.
Решающее дерево: какой метод выбрать
flowchart TD
A[Нужно извлечь текст?] --> B{Данные конфиденциальны?}
B -- Да --> C[Использовать локальное ПО 'Gemoo Snap или оффлайн OCR']
B -- Нет --> D{Требуется масштаб или интеграция?}
D -- Да --> E[Облачный API / Google Drive]
D -- Нет --> F[Онлайн-инструмент или быстрый скриншот]Часто задаваемые вопросы
Вопрос: Что такое OCR?
OCR — это технология распознавания символов на изображениях и их преобразования в машиночитаемый текст.
Вопрос: Какие форматы поддерживаются?
Чаще всего: JPEG, PNG, PDF, TIFF. Конкретный набор зависит от инструмента.
Вопрос: Можно ли распознавать рукописный текст?
Да, но точность зависит от разборчивости почерка и выбранного движка распознавания.
Вопрос: Что делать, если OCR дал много ошибок?
Попробуйте повысить качество изображения, изменить предобработку (контраст, удаление шума), выбрать другой движок или выполнить ручную корректировку.
Заключение
OCR делает текст из изображений доступным для поиска, редактирования и интеграции в рабочие процессы. Для простых и разовых задач подойдёт Google Drive или онлайн-сервис. Для задач с требованиями по безопасности или для регулярной обработки лучше выбирать локальные решения или платные API. Всегда проверяйте результат и используйте чек-листы и тест-кейсы для контроля качества.
Важно следить за конфиденциальностью данных и учитывать, как используются и хранятся результаты распознавания.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
