Как извлечь текст из изображений и PDF с помощью Google Drive

Иногда нужно быстро получить текст из картинки или PDF — для исследования, презентации или цитаты. Google Drive позволяет извлекать текст из изображений (JPEG, PNG, GIF) и из PDF (одно- и многостраничных). Процесс быстрый: загрузить файл в Drive и открыть его через Google Docs.
Важно: Google Docs использует встроенное распознавание текста (OCR). Оно автоматически определяет язык документа и преобразует видимый текст в редактируемый формат. Ниже — пошаговая инструкция, советы по качеству результата, варианты при сбоях и готовые чеклисты.
Как подготовить изображения и файлы для лучшего результата
Короткая версия:
- Формат: JPEG, PNG, GIF или PDF.
- Размер файла: желательно ≤ 2 МБ.
- Минимальная высота символа: ~10 пикселей (приблизительно 7,5 pt).
- Качество: резкое изображение, ровное освещение, высокий контраст.
- Ориентация: документ должен быть повернут в правую сторону.
Детали и пояснения:
- Если текст мелкий или изображение размытое, OCR пропустит символы или неправильно распознает слова. По возможности увеличьте разрешение перед загрузкой.
- Простые веб-шрифты (Arial, Times New Roman) распознаются лучше, чем декоративные шрифты или рукопись.
- Для многостраничных PDF Google Docs распознаёт страницы и помещает текст под соответствующими изображениями.
Важно: если в документе много сложной верстки (таблицы, колонки, графика), сохраните исходный PDF и проверьте выровненный текст — форматирование может потеряться.
Пошаговая инструкция
- Откройте сайт Google Drive на компьютере или в Chrome через меню «Приложения Google».
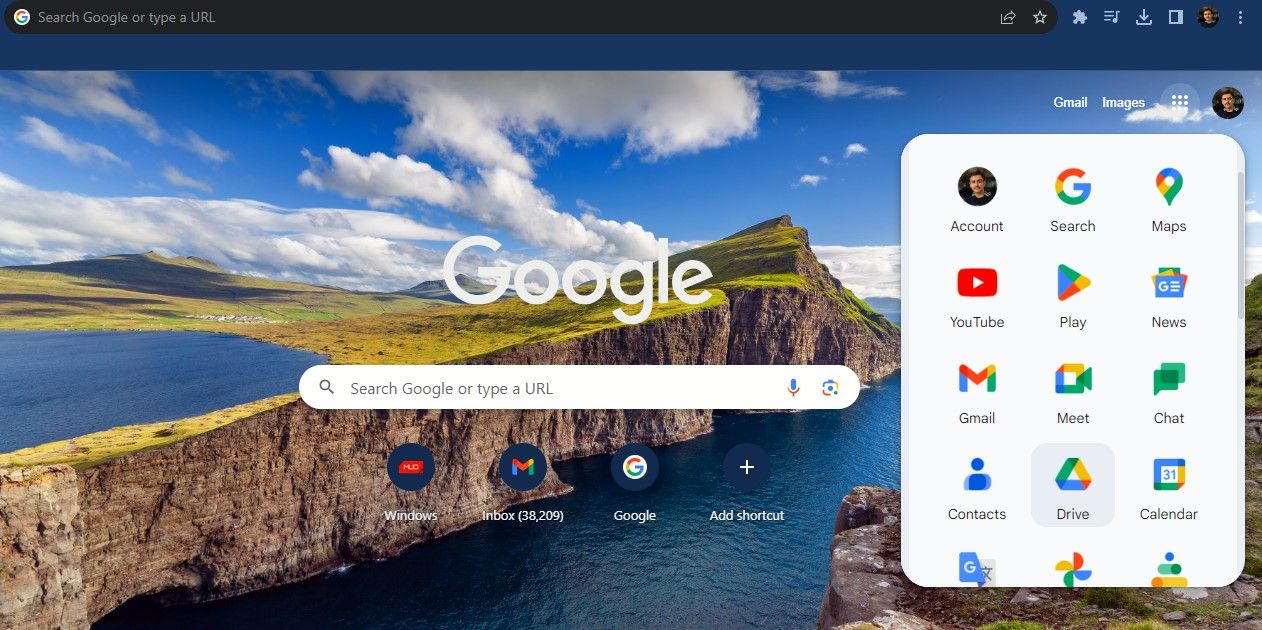
- Найдите изображение или PDF в Drive, щёлкните по нему правой кнопкой мыши. Выберите “Открыть с помощью”, затем — “Google Docs”.
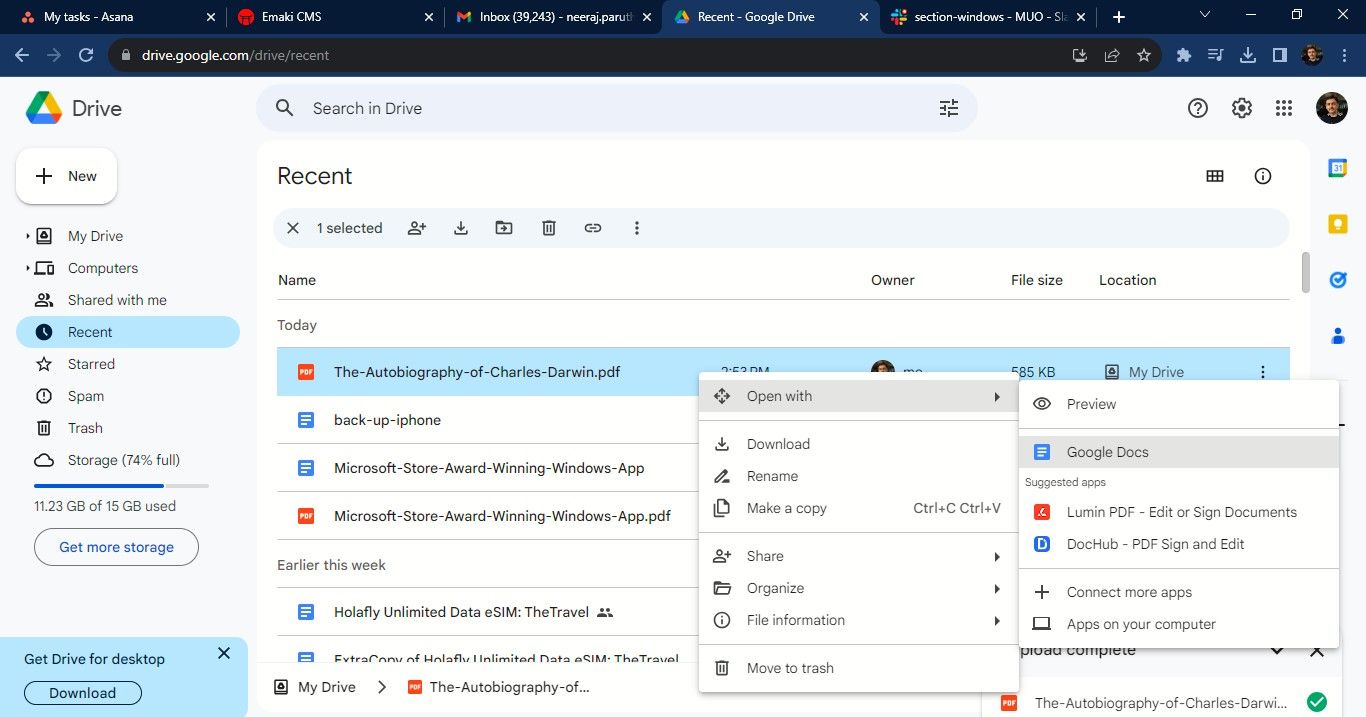
- Если файл на вашем компьютере, загрузите его в Drive: нажмите «Новый» → «Загрузка файла».
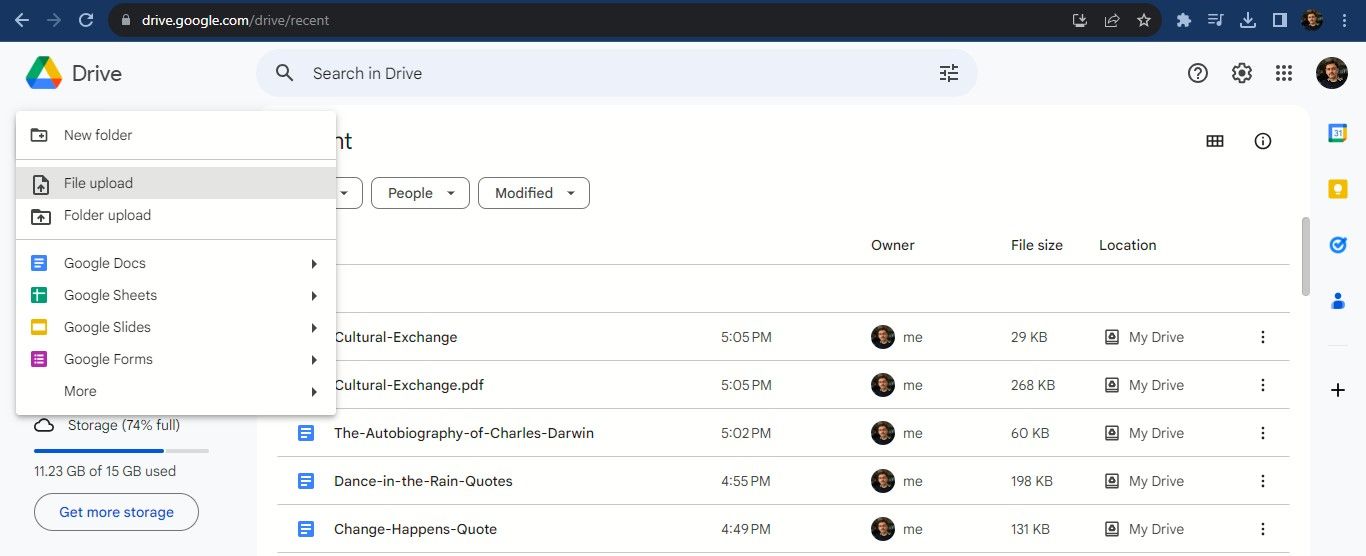
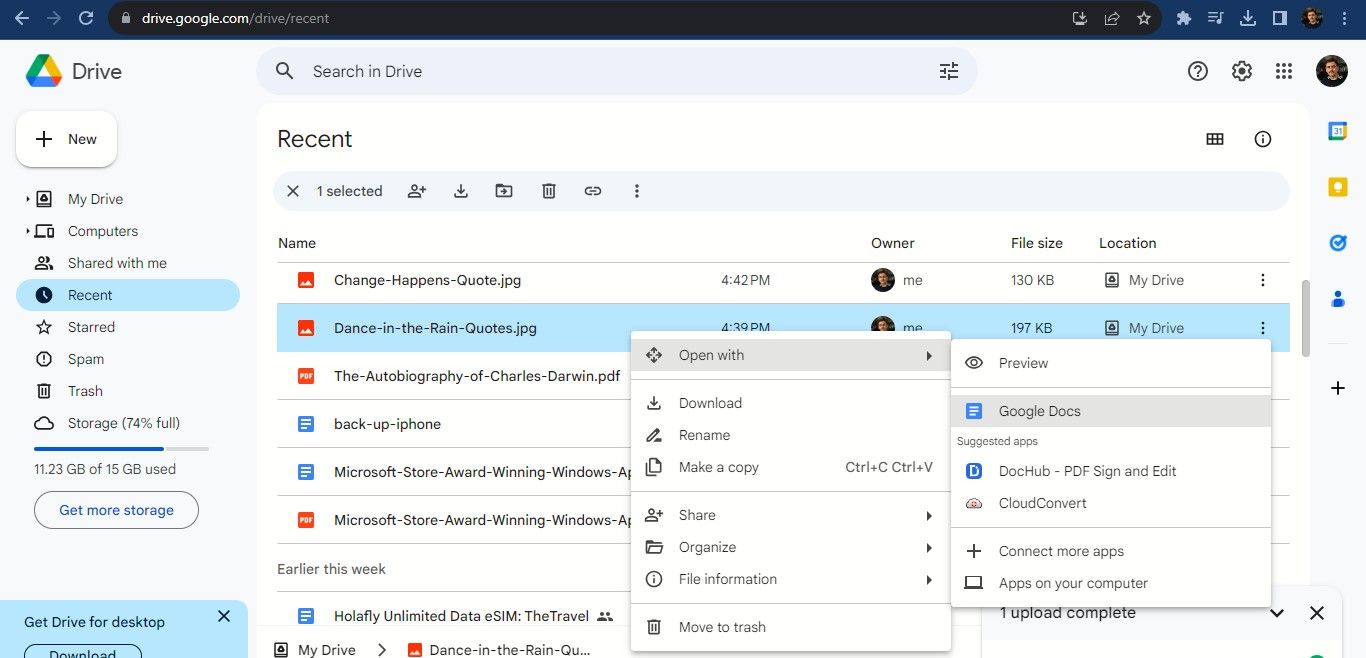
- После загрузки откройте вкладку “Недавние”, если нужно быстро найти файл. Правый клик → “Открыть с помощью” → “Google Docs”.
- В документе Google Docs вы увидите изображение сверху, а под ним — распознанный текст, готовый для редактирования и копирования.
Совет: после распознавания сначала просмотрите текст на ошибки, затем скопируйте в нужный формат (Word, PowerPoint, Notepad и т. п.).
Типичные проблемы и как их решать
- Нечёткий или урезанный текст: проверьте исходное изображение, при необходимости сделайте новый скан или фото.
- Неправильная ориентация: поверните изображение до загрузки.
- Плохая подсветка/блики: используйте ровный свет, избегайте засветов от окна или лампы.
- Рукописный текст: стандартный OCR Drive часто плохо справляется с почерком; используйте Google Lens или специализированный OCR.
Примечание: иногда Google Docs некорректно разбивает строки при сложной верстке. Вручную приведите текст в нужный вид или используйте более продвинутые инструменты для конвертации PDF.
Когда встроенный OCR не подойдёт — альтернативы
- Google Lens (мобильные устройства): хорошо работает с фото и рукописью.
- Microsoft OneNote / Office Lens: удобны для смартфона, умеют править перспективу.
- PowerToys Text Extractor (Windows) — быстрый способ захвата текста с экрана.
- Adobe Acrobat Pro: лучше обрабатывает сложные PDF и таблицы.
- Специализированные OCR-сервисы (Tesseract, ABBYY FineReader) — при высоких требованиях к точности и сохранению верстки.
Каждый инструмент имеет свои сильные стороны: мобильные решения удобны в поле, а десктопные — при пакетной обработке больших объёмов.
Быстрые правила оценки качества (ментальная модель)
- Четкость — основной фактор: чем резче буквы, тем выше точность.
- Контраст — важен при монохромных текстах на фоне изображения.
- Шрифт — стандартные шрифты распознаются лучше.
- Структура — колонки и таблицы усложняют задачу OCR.
Эту модель можно применять при выборе, стоит ли доверить задачу встроенному OCR или использовать продвинутые инструменты.
Чеклист перед загрузкой (готовое действие)
- Файл в формате JPEG/PNG/GIF или PDF
- Размер файла ≤ 2 МБ (если возможно)
- Текст в правой ориентации
- Ровное освещение и высокий контраст
- Минимум декоративных шрифтов
Важно: даже если один из пунктов нарушен, загрузка всё равно может дать полезный результат, но проверка пригодности обязана быть быстрее, чем ручной набор текста.
Краткий SOP для команды (быстрая команда)
- Откройте Google Drive → загрузите файл.
- Правый клик по файлу → Открыть с помощью → Google Docs.
- Проверьте распознанный текст на ошибки и отформатируйте.
- Сохраните копию в нужном формате или поделитесь ссылкой.
Критерии приёмки
- Распознанный текст читаем и допускает не более 2–3 ошибок на страницу при обычном шрифте.
- Ключевые метаданные (названия, заголовки, цифры) сохранены корректно.
Тестовые случаи для проверки качества распознавания
- Фото высококонтрастного печатного текста (стандартный шрифт).
- Сканы с колонками и таблицами (оцените сохранение структуры).
- Низкоконтрастные изображения (проверьте количество ошибок).
- Рукописный текст (оцените пригодность и необходимость альтернатив).
Диаграмма принятия решения
flowchart TD
A[Есть изображение или PDF?] --> B{Файл на ПК или в Drive}
B -- В ПК --> C[Загрузить в Drive]
B -- В Drive --> D[Открыть правой кнопкой]
C --> D
D --> E[Открыть с помощью Google Docs]
E --> F{Текст распознан корректно?}
F -- Да --> G[Скопировать/сохранить и использовать]
F -- Нет --> H[Попробовать улучшить изображение или альтернативу]
H --> I{Нужно много страниц или точная верстка?}
I -- Да --> J[Использовать Adobe/ABBYY/Tesseract]
I -- Нет --> K[Попробовать Google Lens или PowerToys]Ролевые чеклисты
- Исследователь: проверяй точность цитат и источников; сохраняй оригинал.
- Студент: проверяй форматирование и кавычки; сохрани скриншоты для ссылок.
- Дизайнер: бери исходное изображение для редактирования; проверяй выравнивание текста.
- Менеджер: делегируй распознавание, проверь итоговый документ на основные ошибки.
Факт-бокс — ключевые параметры
- Поддерживаемые форматы: JPEG, PNG, GIF, PDF.
- Рекомендуемый размер: ≤ 2 МБ.
- Минимальная высота символа: ~10 пикселей ≈ 7,5 pt.
- Языки: автоматическое обнаружение множества языков.
Важно: Google Drive — удобное бесплатное решение для большинства задач по извлечению текста. Для критичных по точности случаев используйте профессиональные OCR-инструменты.
Часто задаваемые вопросы
Q: Можно ли распознать рукопись?
A: Частично. Google Docs чаще ошибается на рукописи. Для рукописи лучше использовать Google Lens или специализированные решения.
Q: Сохраняется ли форматирование?
A: Нет, или частично. Google Docs фокусируется на тексте; сложная верстка и таблицы требуют ручной доработки или других инструментов.
Q: Могу ли я поделиться распознанным текстом?
A: Да. Документ Google Docs можно легко поделиться через ссылку или экспортировать в формат Word/PDF.
Итог
Google Drive — быстрый и бесплатный способ извлечь текст из изображений и PDF. Он идеально подходит для одноразовых задач и небольших объёмов. Для массовой обработки или высоких требований по точности лучше рассмотреть специализированные OCR-инструменты.
Важно: начните с проверки качества исходного изображения — это самый эффективный способ улучшить результат распознавания.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
