Как правильно создать таблицу в SQL
! Схематичное изображение таблицы и схемы базы данных
{kind=link}
Создание таблицы SQL — базовый навык для любого, кто работает с базами данных. В этом руководстве показано, как быстро и корректно создать таблицу в MySQL с пояснениями и практическими советами по дизайну.
Начало работы с таблицей SQL
Перед созданием таблицы убедитесь, что у вас настроена схема в SQL-сервере. В примерах используется MySQL и MySQL Workbench.
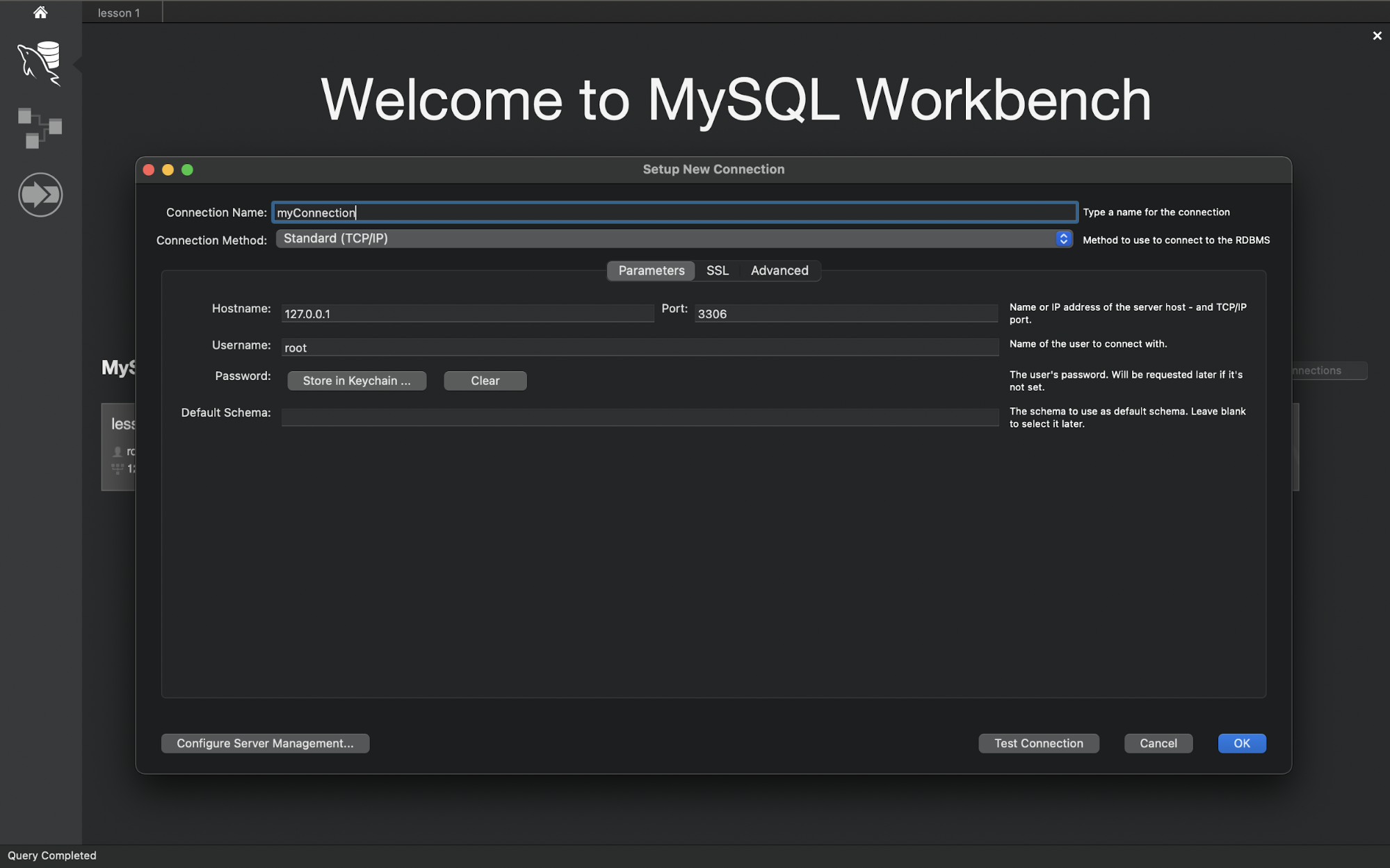
- Откройте MySQL Workbench.
- Нажмите на значок «+», чтобы добавить подключение.
- В диалоге задайте имя подключения и подтвердите.
После подключения вы попадёте в редактор, где можно вводить запросы для создания и управления схемами.
Создадим новую схему для теста:
CREATE schema mySchema;
USE mySchema
Эта команда создаёт схему (базу данных) mySchema и переключает контекст на неё. Схема хранит таблицы и связи между ними.
Создание таблицы SQL
Таблица создаётся с помощью ключевого слова CREATE TABLE. Нужны: имена столбцов, типы данных и первичный ключ.
Общий синтаксис выглядит так:
CREATE TABLE table_name(
column1 datatype,
column2 datatype,
column3 datatype,
.....
columnN datatype,
PRIMARY KEY(columnName)
);
Пример — таблица для хранения сотрудников компании:
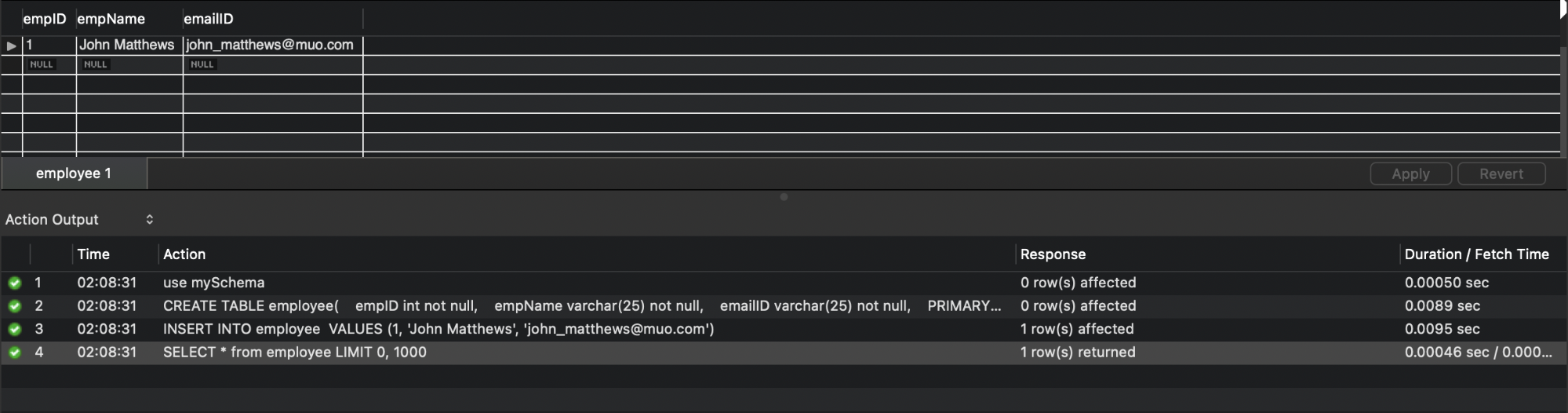
use mySchema;
CREATE TABLE employee(
empID int not null,
empName varchar(25) not null,
emailID varchar(25) not null,
PRIMARY KEY (empID)
);
Короткие пояснения:
- INT, VARCHAR — типы столбцов. Выбирайте тип по данным (числа — INT/DECIMAL, текст — CHAR/VARCHAR/TEXT, даты — DATE/DATETIME).
- NOT NULL запрещает пустые значения в столбце.
- PRIMARY KEY гарантирует уникальность строки и обычно индексируется.
Важно: продумывайте длину VARCHAR и ограничивайте NULL там, где значения обязательны.
Добавление данных в таблицу
Для добавления строки используйте INSERT INTO:
INSERT INTO employee
VALUES (1, 'John Matthews', 'john_matthews@muo.com');
Советы:
- Явно указывайте список столбцов при вставке: INSERT INTO employee(empID, empName, emailID) VALUES(…). Это защищает от ошибок при изменении структуры таблицы.
- Для нескольких строк используйте одну команду с несколькими кортежами значений.
Вывод данных из таблицы
Чтобы увидеть данные, выполните SELECT:
SELECT * from employee;
Звёздочка * означает «все столбцы». Лучше выбирать только те столбцы, которые нужны: SELECT empID, empName FROM employee;
Если всё прошло успешно, вы увидите результат в панели “Result Grid” MySQL Workbench.
Советы по проектированию таблиц (мини-методология)
- Определите предметную область: какие сущности нужны и какие данные будут храниться.
- Выделите атрибуты сущности и назначьте типы данных.
- Решите вопросы уникальности и связей: первичные ключи, внешние ключи, индексы.
- Задайте ограничения (NOT NULL, UNIQUE, CHECK) и дефолтные значения.
- Нормализуйте до разумного уровня (обычно 3NF), затем учитывайте производительность.
- Создайте тестовые вставки и проверьте целостность данных.
Когда простой подход не сработает
- Если данные сильно меняют структуру (частые добавления полей), таблицы с фиксированными колонками усложняют поддержку. Решение: схемы на уровне приложения, EAV-модель или NoSQL.
- Для больших объёмов (миллионы строк) нужна проработка индексов, партиционирование и оптимизация запросов.
- Если важны транзакции и согласованность — используйте ACID-совместимые механизмы и контролируйте блокировки.
Альтернативные подходы
- ORM (например, SQLAlchemy, Sequelize) автоматизирует создание таблиц и миграции. Удобно для приложений, но может скрывать SQL-особенности.
- Миграции (Flyway, Liquibase) управляют версионированием схемы в командной разработке.
- NoSQL (MongoDB, DynamoDB) подходит для неструктурированных данных и гибкой схемы.
Чек-листы по ролям
Разработчик:
- Указать типы и длины столбцов.
- Явно указать список столбцов в INSERT.
- Добавить тестовые запросы SELECT/UPDATE/DELETE.
DBA:
- Проверить индексы и первичные/внешние ключи.
- Настроить бэкапы и мониторинг.
- Оценить партиционирование и ресурсы.
Аналитик/BI:
- Согласовать названия и форматы дат/валют.
- Обеспечить совместимость с ETL.
Критерии приёмки
- Таблица создана в нужной схеме и видна в информационной схеме.
- Первичный ключ присутствует и обеспечивает уникальность.
- Все обязательные столбцы имеют NOT NULL.
- INSERT/SELECT/UPDATE/DELETE работают без ошибок на тестовых данных.
- Производительность запросов соответствует требованиям (baseline-тесты пройдены).
Тестовые случаи и приёмка
- Вставка корректной строки — ожидается успешная запись.
- Попытка вставить NULL в NOT NULL — ожидается ошибка.
- Попытка вставить дублирующий PK — ожидается ошибка уникальности.
- Чтение данных — возвращаются ожидаемые столбцы и строки.
Шпаргалка: короткие примеры SQL
Создать таблицу:
CREATE TABLE product(
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100) NOT NULL,
price DECIMAL(10,2) DEFAULT 0.00
);Вставить строки:
INSERT INTO product(name, price)
VALUES ('Notebook', 19.99), ('Pen', 0.99);Обновить строку:
UPDATE product SET price = 17.99 WHERE id = 1;Удалить строку:
DELETE FROM product WHERE id = 2;Краткий глоссарий (1 строка на термин)
- Схема: логическая группа таблиц и объектов в СУБД.
- Таблица: набор строк и столбцов для хранения таксономии данных.
- Первичный ключ: уникальный идентификатор строки.
- Индекс: структура для ускорения поиска.
Итог
Создание правильной таблицы — простая комбинация хорошего проектирования и аккуратного использования синтаксиса SQL. Следуйте чек-листам, тестируйте вставку и выборку данных, и учитывайте альтернативы (ORM, миграции, NoSQL) когда требования изменяются.
Важно: держите схему компактной и понятной. Хорошая структура таблиц повышает читаемость, упрощает поддержку и ускоряет запросы.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
