Как преобразовать книгу в полнотекстовый PDF с поиском

Введение
Традиционные бумажные книги сохраняют свою эстетику, но в реальной работе и обучении часто требуется не весь том целиком, а отдельные главы или фрагменты. Цифровизация упрощает доступ: документы можно хранить в облаке, быстро искать ключевые слова и передавать файлы коллегам или родственникам.
Рост медиаграмотности и повсеместная цифровизация рабочих процессов усиливают потребность конвертировать печатные источники в удобные для поиска и редактирования форматы.
Почему важно делать PDF с поддержкой поиска
- Быстрый поиск по ключевым словам и фразам ускоряет работу с большими коллекциями.
- Текст в документе можно копировать, править и экспортировать в другие форматы.
- Цифровые копии экономят место и упрощают совместную работу и архивирование.
Важно: при оцифровке стоит думать не только о изображениях страниц, но и о удобстве дальнейшего использования текста.
Типы PDF и как их отличить
Image-based PDF (PDF на основе изображений)
- Создаются при сканировании, фотографировании или сохранении снимков страниц.
- Страницы представляют собой изображения, текст нельзя выделить или искать.
True/text-based PDF (текстовые PDF)
- Создаются цифровыми средствами: «Сохранить как PDF» или «Печать в PDF» из текстового редактора.
- Текст полностью машинно-читаем и доступен для поиска и копирования.
OCR’d PDF (PDF, обработанные OCR)
- Исходно были image-based, но к ним применили OCR: поверх изображений добавлен текстовый слой.
- Распознавание символов и структуры документа приближает такие файлы к настоящим текстовым PDF, хотя распознавание может быть неидеальным.
Что такое OCR
OCR (оптическое распознавание символов) — это технология, которая преобразует изображение с текстом в машинно-читаемый текст. Коротко: OCR извлекает символы и позиционирование текста, после чего создаёт текстовый слой над изображением.
Как работает процесс OCR и почему это важно
- Сканер или камера создаёт изображение страницы.
- Алгоритмы анализируют контуры символов, сегментируют строки и слова.
- В результате формируется текстовый слой, который можно индексировать и редактировать.
Преимущества применения OCR:
- Документы становятся полнотекстовыми и поисковыми.
- Упрощается автоматизация извлечения данных и аналитика.
- Снижаются ручные операции и ошибки при переносе информации.
Ограничения и когда OCR может давать ошибки
Important: OCR не всегда безошибочен. Типичные причины ошибок:
- Низкое качество исходного изображения (размытость, шумы).
- Старые или декоративные шрифты, рукописный текст.
- Неровные или сильно изогнутые страницы, блики на глянцевых поверхностях.
- Языки с необычной разметкой или смешанная верстка (таблицы, формулы).
Контрмеры: используйте высококачественное сканирование, корректную подсветку и программные инструменты для выравнивания кривизны страницы.
Альтернативные подходы
- Ручной набор текста — применим для коротких фрагментов, но затратен по времени.
- Заказ цифровой версии у правообладателя — лучший вариант для коммерческих изданий.
- Гибрид: начальное OCR + ручная посткоррекция критических участков.
Практическая методика: шаги для получения полнотекстового PDF
- Подготовка материала
- Очистите книгу от заметок и посторонних предметов. Пометьте страницы, которые нужно сканировать.
- Выбор оборудования
- Стационарный сканер, камера высокого разрешения или скоростной книжный сканер — в зависимости от объёма.
- Настройка сканирования
- Разрешение 300–400 DPI обычно достаточно для OCR; для мелкого шрифта можно повысить.
- Выберите режим цвет/градации серого в зависимости от источника.
- Сканирование
- Используйте равномерную подсветку и устраните блики. Не разрывайте книги без необходимости.
- Применение OCR
- Выберите корректный язык распознавания.
- Проведите постобработку: выравнивание, коррекция кривизны, удаление шумов.
- Валидация и экспорт
- Проверяйте ключевые страницы вручную. Экспортируйте в PDF с наложенным текстовым слоем, сохраняйте оригинальные изображения.
- Архивирование и доступ
- Присвойте понятные имена файлам, добавьте метаданные и размещайте в защищённом облаке или архиве.
Пример инструментов и функции, на которые обращать внимание
- Поддержка нескольких языков распознавания.
- Возможность пакетной обработки страниц.
- Сохранение в PDF с текстовым слоем и в формате Word/Excel для экспорта таблиц.
- Инструменты постобработки: исправление кривизны, удаление артефактов, коррекция перспективы.

CZUR E18 Pro и его особенности
Если вас интересует аппаратное решение, упомянутая модель CZUR E18 предлагает ряд функций, оптимизированных под оцифровку книг:
- Сканирует документы до A3 без разрезания и расплетения страниц.
- Создаёт редактируемые PDF, TIFF, Excel и Word с помощью OCR.
- Патентованная технология Flattening Curve: три лазерные линии (безопасные) анализируют контур страницы и вычисляют кривизну для программного выпрямления.
В устройстве ET18 используется 32‑битный MIPS CPU, который позволяет сканировать 2 страницы открытой книги за 1,5 секунды. Камера 16MP фиксирует детальную текстуру и иллюстрации, а боковые прожекторы уменьшают блики с глянцевых страниц.
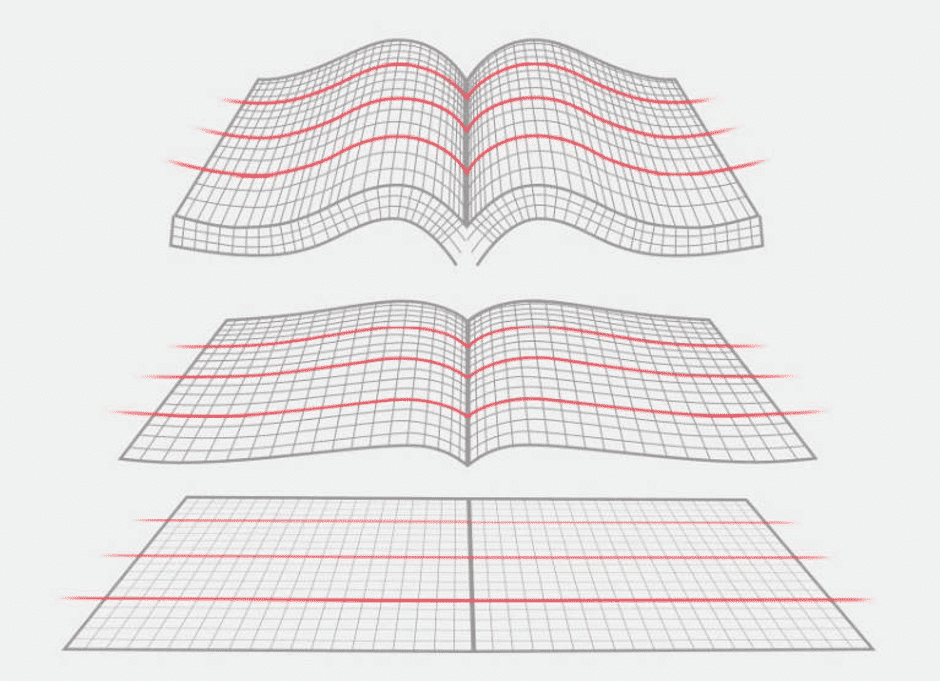
Эти аппаратные функции особенно полезны для архивов, библиотек и организаций, которым важно сохранить как содержимое, так и визуальную целостность изданий.
Чек‑лист при подготовке к сканированию (роль: библиотекарь)
- Проверить права на оцифровку и использование материалов.
- Оценить состояние переплёта, пометить проблемные страницы.
- Настроить разрешение сканера и язык OCR.
- Выполнить пробное сканирование нескольких страниц.
- Провести контроль качества после OCR и сохранить резервные копии.
Чек‑лист при подготовке к сканированию (роль: преподаватель)
- Выделить фрагменты и главы для оцифровки.
- Выбрать формат экспорта (PDF/Word/Excel).
- Проверить доступность файлов для студентов (формат, права доступа).
- Подготовить краткие инструкции по поиску в PDF для учащихся.
Критерии приёмки
Документ считается корректно оцифрованным, если:
- Текст на ключевых страницах читается и корректно распознаётся при поиске.
- Сохранена верстка и структура (оглавление, заголовки, таблицы) в пределах технических возможностей.
- Файл снабжён метаданными и присвоен уникальный идентификатор.
Простая эвристика для оценки необходимого подхода
- Малая партия страниц, простой шрифт → OCR на обычном сканере.
- Большой архив, плотные переплёты → книжный сканер с технологией выравнивания.
- Коммерческое издание → сначала проверить наличие цифровой версии у правообладателя.
Порядок действий при проблемах с качеством распознавания
- Увеличьте разрешение сканирования и устраните блики.
- Проверьте правильность выбранного языка OCR.
- Примените программные фильтры удаления шума и коррекции контраста.
- При необходимости выполните ручную корректировку критичных участков.
Конфиденциальность и права
- Перед сканированием проверьте авторские права и правомочность оцифровки.
- Для персональных или конфиденциальных данных настройте шифрование хранения и контроля доступа.
Decision flowchart
flowchart TD
A[Есть физическая книга?] -->|Да| B{Есть цифровая версия у правообладателя?}
A -->|Нет| Z[Не нужно сканировать]
B -->|Да| Y[Получить цифровую версию]
B -->|Нет| C{Нужен полный том или фрагменты?}
C -->|Фрагменты| D[Сканировать разделы вручную]
C -->|Полный том| E[Использовать книжный сканер]
E --> F[Применить OCR]
D --> F
F --> G[Постобработка и проверка]
G --> H[Экспорт в PDF с текстовым слоем]Частые ошибки и как их избежать
- Сканирование с низким разрешением — уменьшает качество распознавания.
- Игнорирование метаданных — усложняет поиск и каталогизацию.
- Отсутствие резервных копий — риск потери оцифрованного материала.
Notes: автоматическое OCR удобно, но для критичных документов рекомендуется ручная проверка.
Краткое резюме
Преобразование книг в полнотекстовые PDF повышает доступность, экономит место и ускоряет работу с информацией. Технологии OCR и современные книжные сканеры (например, CZUR E18/ET18) значительно упрощают процесс, но важно учитывать ограничения распознавания и соблюдать права на контент.
Краткие шаги: подготовка → сканирование → OCR → постобработка → валидация → архивация.
Summary:
- OCR делает изображения страниц поисковыми и редактируемыми.
- Качество исходного скана напрямую влияет на точность распознавания.
- Выбор оборудования и методики зависит от объёма и состояния книг.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
