Переименование множества файлов в числовую последовательность в Linux

Быстрые ссылки
Numeric File Names — Числовые имена файлов
Bulk Rename Files to Numeric File Names — Массовое переименование в числовую последовательность
Цель этой статьи — показать рабочую, безопасную и совместимую технику для переименования множества файлов в числовую последовательность в Linux, объяснить нюансы, предложить альтернативы и дать набор проверок и процедур для безопасного применения в реальной среде.
Когда это полезно
При сканировании документов, импорте фото или сборе файлов с разных источников вы часто получаете имена вроде 2020_11_28_13_43_00.pdf или names-with-spaces.pdf. Для упорядочивания, автоматической обработки пакетов или подготовки к архивированию удобно привести такие файлы к единообразному числовому формату.
Примеры сценариев:
- Сканированные PDF-файлы из разных устройств
- Пакеты SQL-скриптов, которые нужно выполнить в определённом порядке
- Коллекции фотографий или рецептов для простого перебора
- Логи и дампы, которые подготавливаются для архивирования
Рабочая однострочная команда
Ниже — однострочный скрипт, который я использую и тестировал на наборах файлов с особыми символами (включая имена с переводом строки) и на больших объёмах (десятки тысяч файлов). Команда создаёт два временных файла: _e (расширение) и _c (счётчик). Перед исполнением она проверяет, что этих файлов нет, чтобы избежать конфликтов.
if [ ! -r _e -a ! -r _c ]; then echo 'pdf' > _e; echo 1 > _c ;find . -name "*.$(cat _e)" -print0 | xargs -0 -I{} bash -c 'mv -n "{}" $(cat _c).$(cat _e);echo $[ $(cat _c) + 1 ] > _c'; rm -f _e _c; fiПримечание: в этом примере расширение фиксировано как pdf (строка echo ‘pdf’ > _e). Чтобы переименовывать другие расширения, замените ‘pdf’ на нужную строку (без точки).
Как это работает — шаг за шагом
- Безопасная проверка:
if [ ! -r _e -a ! -r _c ]; then ... fi— выполняем тело только если файлов _e и _c не существует (чтобы не перезаписать случайные файлы). - Создаём файлы состояния:
echo 'pdf' > _eиecho 1 > _c— хранение расширения и начального счётчика. find . -name "*.$(cat _e)" -print0— находит все файлы с заданным расширением в текущем каталоге и подкаталогах, выводя результаты через NUL (безопасно для пробелов и переводов строк).xargs -0 -I{} bash -c '...'{}— для каждого нуль-терминированного имени файла запускаем bash-подпроцесс.- Внутри bash-подпроцесса:
mv -n "{}" $(cat _c).$(cat _e)— перемещаем/переименовываем файл в N.pdf (при этом флаг -n защищает от перезаписи существующих файлов). echo $[ $(cat _c) + 1 ] > _c— увеличиваем счётчик в файле _c.- После завершения удаляем временные файлы:
rm -f _e _c.
Почему используются файлы вместо переменных
- Переменные окружения, экспортированные в родительском шелле, могут конфликтовать при параллельных запусках скрипта или при одновременной работе других сценариев.
- Комбинация
xargs+bash -cнеудобна для передачи и надёжной инкрементации переменных, поэтому файл-счётчик — простое и надёжное решение.
Почему используется NUL-терминация
- Имена файлов могут содержать пробелы, табы, нечитаемые символы и переводы строк. NUL-терминация (опции
-print0и-0) — стандартный способ безопасно передавать имена файлов между инструментами в POSIX-среде.
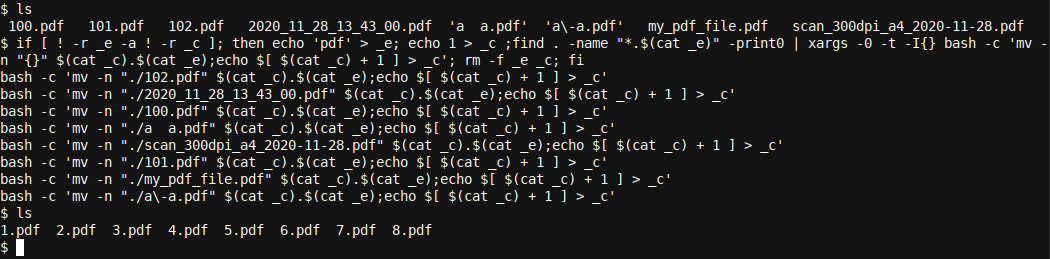
Примеры использования и варианты
- Начать с другого счётчика (например, с 100):
echo 'pdf' > _e; echo 100 > _c- Переименовать только в текущей папке (без рекурсии) — используйте
-maxdepth 1:
find . -maxdepth 1 -name "*.$(cat _e)" -print0 | xargs -0 ...- Исключить файлы в определённых папках:
find . -path './exclude_dir' -prune -o -name "*.$(cat _e)" -print0- Сохранять порядок по времени изменения вместо произвольного списка find (если важен порядок): сортировать с помощью
lsне рекомендуется; вместо этого можно использоватьfindс-printf '%T@ %p\0' | sort -z -nи затем извлечь поле с именем. Это сложнее, но реализуемо, если порядок обязателен.
Альтернативные подходы
- Использовать утилиту rename (перл/переименование): гибка для шаблонов, но часто не обеспечивает безопасной обработки новых строк и прочих специальных символов.
- Писать скрипт на Python: позволяет гибкий контроль и атомарные операции, удобно логировать и откатывать. Пример: использовать os.walk + os.replace с созданием карты старое->новое и проверкой коллизий.
- Использовать mmv или util-linux
renameдля простых сценариев, но внимательно тестируйте с нештатными именами.
Когда стоит выбрать Python:
- нужно сложное сопоставление имён;
- требуется журнал действий (лог) и возможность отката;
- нужно работать с метаданными файлов.
Когда достаточно однострочника с find/xargs:
- большая производительность для простых массовых переименований;
- нужно максимальное соответствие стандартным POSIX-инструментам;
- важна корректная работа с NUL-терминацией.
Безопасность и риск-менеджмент
Important: всегда работайте на резервной копии или на тестовой директории перед запуском на реальных данных.
Риски и смягчения:
- Потеря данных при перезаписи — используйте
mv -n(как в примере) или перед этим проверьте отсутствие конфликтов. - Выполнение в неправильной директории — сначала выполните команду с echo/экранной симуляцией (см. раздел тестирования).
- Прерывание на середине — временные файлы _e и _c останутся, скрипт откажется стартовать до их удаления; это защитный механизм.
Тестирование — как проверить перед запуском
Перед массовым применением прогоните несколько проверок:
- Создайте тестовую папку с файлами, содержащими пробелы, кавычки, апострофы и переводы строк.
- Запустите
find . -name "*.$(cat _e)" -print0 | xargs -0 -I{} echo mv -n "{}" $(cat _c).$(cat _e)— замените mv на echo, чтобы увидеть команды, которые будут выполнены. - Запустите на небольшой части реальных данных и проверьте результат.
- Убедитесь, что в целевой директории нет файлов с именами 1.pdf..N.pdf если вы не хотите перезаписи.
Критерии приёмки
- Все целевые файлы переименованы в последовательность без пропусков (если не было ошибок).
- Никакой файл не был перезаписан (для этого mv использует флаг -n).
- Скрипт корректно обработал файлы с пробелами, переводами строки и специальными символами.
- Временные файлы удалены по завершении.
Мини-методология внедрения (SOP)
- Создайте резервную копию исходной директории.
- Выполните симуляцию (замените mv на echo) и проверьте вывод.
- Запустите скрипт в тестовой папке.
- Проверьте результаты, выполните spot-check нескольких файлов.
- Если всё верно — запустите на основной директории.
- После успешной проверки удалите резервную копию или архивируйте её.
Чек-лист для ролей
Администратор:
- Создал резервную копию
- Проверил свободное место на диске
- Запустил тестовую имитацию
Разработчик/инженер данных:
- Проверил совместимость со скриптами, которые будут читать новые имена файлов
- Обновил документацию и pipeline, если нужно
Оператор:
- Убедился, что нет файлов с именами 1..N, которые попадут в конфликт
- Выполнил финальный запуск и проверил лог
Примеры альтернативных скриптов (кратко)
Python (псевдо-реализация, иллюстрация концепции — не забывайте тестировать):
import os
files = []
for root, _, filenames in os.walk('.'):
for fn in filenames:
if fn.lower().endswith('.pdf'):
files.append(os.path.join(root, fn))
files.sort() # или другой критерий
for i, path in enumerate(files, start=1):
new = os.path.join(os.path.dirname(path), f"{i}.pdf")
if not os.path.exists(new):
os.replace(path, new)Этот подход даёт больше контроля: легко логировать, делать dry-run и реализовать откат.
Контроль качества: тест-кейсы
- Файлы с пробелами и табами в имени
- Файлы с переводом строки в имени (пример: ‘a’$’n’’a.pdf’)
- Большой набор (10k+) файлов — проверка производительности
- Наличие уже существующих файлов 1.pdf..N.pdf — проверка поведения с mv -n
Когда предложенный метод может не сработать
- Если вам нужен специфичный порядок (например, метаданные EXIF для фотографий) — find не гарантирует нужный порядок без явной сортировки.
- Если файлы находятся на удалённых томах с ограничениями atomic-rename.
- Если у вас нет права на создание временных файлов в текущей директории.
Рекомендации по миграции и совместимости
- Для больших хранилищ рассмотрите скрипт с журналированием и возможностью отката: сначала формируйте карту старое->новое, сохраняйте её в файл, затем применяйте переименования и при ошибках используйте карту для восстановления.
- Для систем с CI/CD включите проверку на наличие конфликтов имен перед выполнением.
Быстрый справочник и подсказки
- Безопасность: всегда делайте dry-run
- Порядок: если важен порядок, отсортируйте список явно
- Производительность: однострочник с find/xargs даёт хорошую скорость, но создаёт множество подпроцессов
Итог
Предложенный однострочник — практичный и проверенный инструмент для массового переименования файлов в числовую последовательность, с учётом специальных символов и больших объёмов. Он не универсален для всех ситуаций (например, когда нужен сложный порядок или журналирование), но для большинства задач с простой последовательностью он удобен и безопасен при выполнении рекомендаций по тестированию.
Краткие рекомендации:
- Сделайте резервную копию
- Запустите dry-run (замените mv на echo)
- При необходимости адаптируйте стартовое значение счётчика или глубину поиска
Желаю успеха и аккуратной миграции файлов — наслаждайтесь чистой последовательностью имён!
Похожие материалы

Скрыть приложения в Windows — 4 проверенных способа
Как восстановить Windows‑ПК после вируса
GDM: добавить, изменить и удалить сеансы

Как сбросить Amazon Firestick до заводских настроек

Как поставить свою песню на звонок Android
