Создание набора данных из IMDb с помощью веб-скрейпинга

Обзор способов сбора данных
Сбор данных можно организовать несколькими способами: ручной ввод, API, публичные датасеты и веб-скрейпинг. Кратко про плюсы и минусы каждого:
- Ручной ввод: полезен для небольших наборов и когда данных нет нигде в машиночитаемом виде. Минусы — большая трудоёмкость и ошибки человека.
- API: структурированный доступ, часто актуальные данные и поддержка. Минусы — требования аутентификации, лимиты и возможные платные тарифы.
- Публичные датасеты: экономят время, часто хорошо документированы. Минусы — могут не покрывать вашу задачу или устареть.
- Веб-скрейпинг: гибкость и возможность собрать то, чего нет в API. Минусы — требуются навыки программирования, понимание HTML и соблюдение юридических/этических ограничений.
Важно выбирать метод, отталкиваясь от объёма, требуемой точности, частоты обновления и легальности доступа.
Почему стоит выбрать веб-скрейпинг
Веб-скрейпинг подходит, когда:
- Источник не предоставляет API или API ограничено.
- Нужна кастомная структура данных, комбинирование нескольких страниц/сайтов.
- Требуется массовый сбор исторических или разрозненных данных.
В то же время скрейпинг требует планирования: учитывать частоту запросов, корректную обработку ошибок и хранение данных.
Выбор источника и юридические аспекты
Перед началом убедитесь, что сбор данных совместим с условиями использования сайта (Terms of Service) и локальным законодательством. Для публичных сайтов также проверьте robots.txt — он показывает, какие разделы запрещены для автоматизированного доступа. Тем не менее robots.txt является рекомендацией, а не юридическим документом, поэтому лучше сверяться с условиями сайта.
В качестве примера в этой статье используется IMDb (Internet Movie Database).
Важно: соблюдайте этику и законы — не собирайте персональные данные без основания, не перегружайте серверы частыми запросами и указывайте корректный User-Agent.
Настройка окружения
Создайте виртуальное окружение и установите необходимые библиотеки:
pip install requests beautifulsoup4 pandas
Библиотеки:
- requests — отправка HTTP-запросов.
- beautifulsoup4 — парсинг HTML и поиск элементов.
- pandas — манипуляция и сохранение табличных данных.
Полный исходный код можно хранить в репозитории GitHub и подключать версии зависимостей через requirements.txt.
Написание скрипта для скрейпинга
Импортируйте библиотеки в скрипте:
import requests
from bs4 import BeautifulSoup
import time
import pandas as pd
import reМодули time и re входят в стандартную библиотеку Python. time пригодится для задержек между запросами, re — для работы с регулярными выражениями.
Создайте функцию для получения HTML и парсинга его в объект BeautifulSoup:
def get_soup(url, params=None, headers=None):
response = requests.get(url, params=params, headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
return soupДалее необходимо понять структуру целевой страницы: откройте страницу в браузере, нажмите правой кнопкой — «Просмотреть код» или «Инспектировать» и найдите HTML-элементы, которые содержат нужные данные.
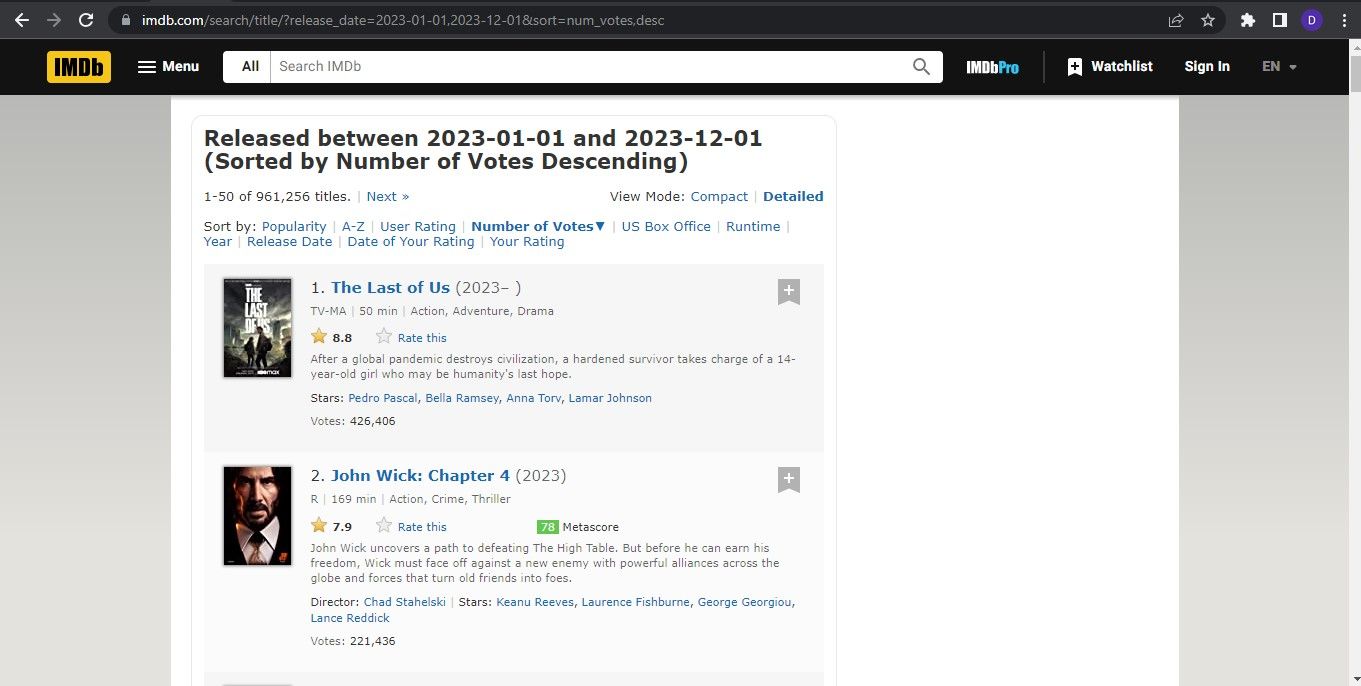
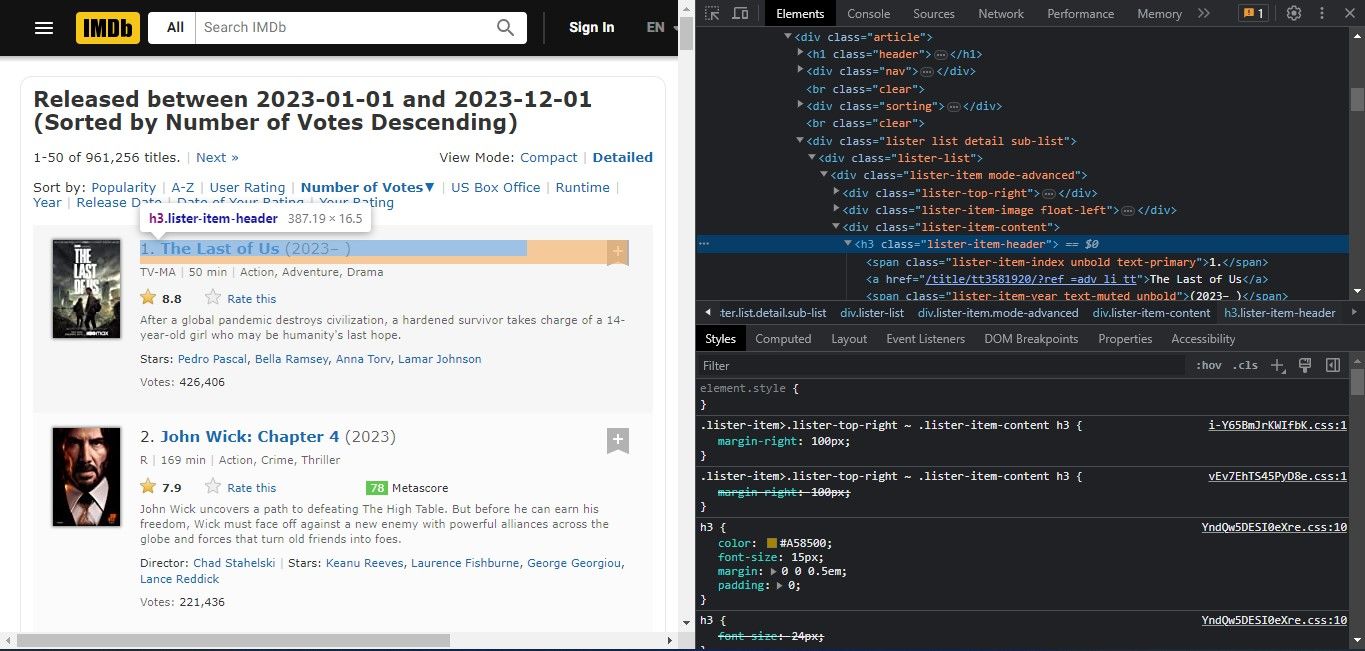
В примере на странице IMDb заголовок фильма находится внутри класса lister-item-header. Для каждого поля (рейтинг, описание, жанр и т.д.) нужно определить подходящий селектор.
Создайте функцию для извлечения данных из блока фильма:
def extract_movie_data(movie):
title = movie.find("h3", class_="lister-item-header").find("a").text
rating = movie.find("div", class_="ratings-imdb-rating").strong.text
description = movie.find("div", class_="lister-item-content").find_all("p")[1].text.strip()
genre_element = movie.find("span", class_="genre")
genre = genre_element.text.strip() if genre_element else None
release_date = movie.find("span", class_="lister-item-year text-muted unbold").text.strip()
director_stars = movie.find("p", class_="text-muted").find_all("a")
directors = [person.text for person in director_stars[:-1]]
stars = [person.text for person in director_stars[-1:]]
movie_data = {
"Title": title,
"Rating": rating,
"Description": description,
"Genre": genre,
"Release Date": release_date,
"Directors": directors,
"Stars": stars
}
return movie_dataСоздайте основную функцию, которая итерирует страницы и собирает данные:
def scrape_imdb_movies(year, limit):
base_url = "https://www.imdb.com/search/title"
headers = {"Accept-Language": "en-US,en;q=0.9"}
movies = []
start = 1
while len(movies) < limit:
params = {
"release_date": year,
"sort": "num_votes,desc",
"start": start
}
soup = get_soup(base_url, params=params, headers=headers)
movie_list = soup.find_all("div", class_="lister-item mode-advanced")
if len(movie_list) == 0:
break
for movie in movie_list:
movie_data = extract_movie_data(movie)
movies.append(movie_data)
if len(movies) >= limit:
break
start += 50# IMDb displays 50 movies per page
time.sleep(1) # Add a delay to avoid overwhelming the server
return moviesЗапустите сбор данных:
# Scrape 1000 movies released in 2023 (or as many as available)
movies = scrape_imdb_movies(2023, 1000)
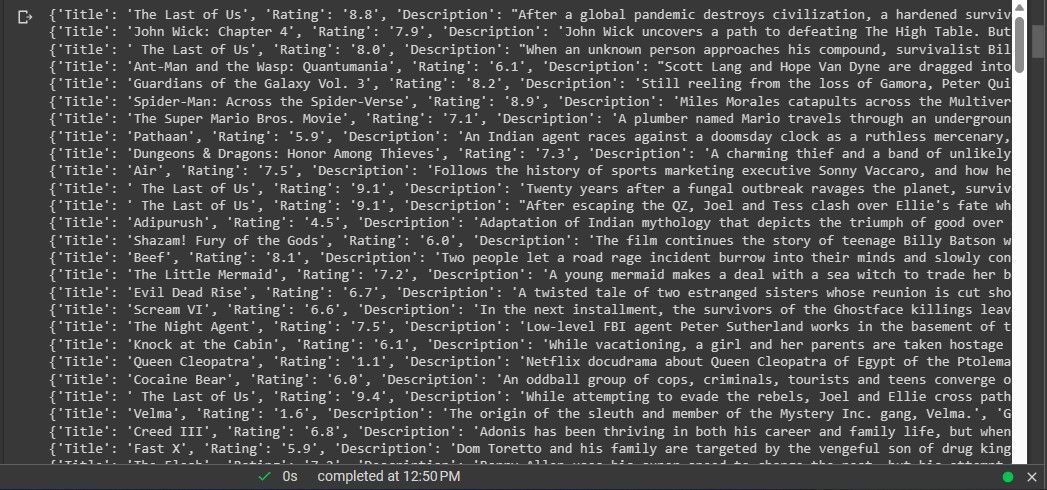
Теперь у вас есть сырые данные — следующий шаг их структурировать.
Создание набора данных и очистка
Сформируйте DataFrame с помощью pandas:
df = pd.DataFrame(movies)
Примерный набор шагов по очистке и предобработке:
- Удалить строки с явно отсутствующими критическими полями.
- Извлечь год из поля даты релиза и привести к числовому типу.
- Преобразовать рейтинг в числовой формат.
- Удалить колонки, которые не нужны для анализа.
- Нормализовать названия (убрать спецсимволы).
В коде это выглядит так:
df = df.dropna()
df['Release Year'] = df['Release Date'].str.extract(r'(\d{4})')
df['Release Year'] = pd.to_numeric(df['Release Year'],
errors='coerce').astype('Int64')
df = df.drop(['Release Date'], axis=1)
df['Rating'] = pd.to_numeric(df['Rating'], errors='coerce')
df['Title'] = df['Title'].apply(lambda x: re.sub(r'\W+', ' ', x))
Сохраните результирующий набор:
df.to_csv("imdb_movies_dataset.csv", index=False)
И просмотрите первые строки:
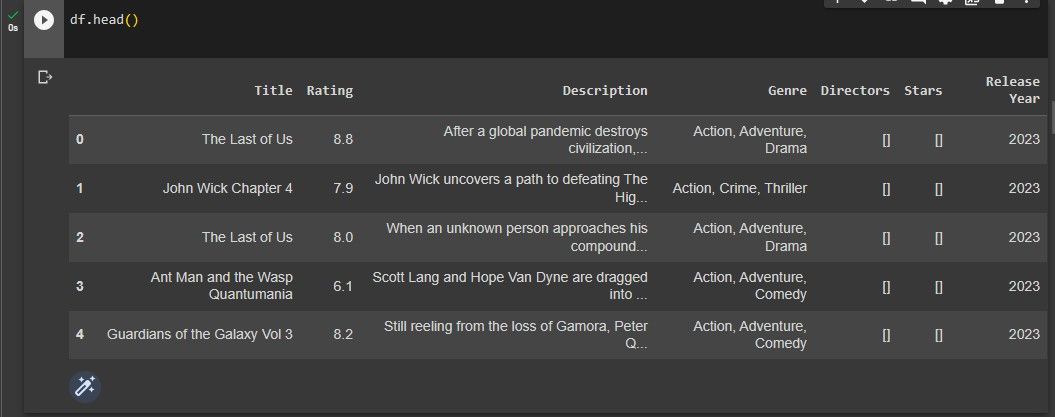
df.head()
Когда веб-скрейпинг не подходит
- Если сайт предоставляет полноценный и бесплатный API с нужными данными — лучше использовать API.
- Если данные конфиденциальны или защищены правами доступа — скрейпинг может нарушать закон.
- Для реального времени и транзакционных данных, где важна задержка — API обычно надёжнее.
Альтернативные библиотеки и подходы
- Scrapy — фреймворк для масштабируемого скрейпинга и построения пауков.
- Selenium — для страниц с динамической загрузкой через JavaScript (использует браузер). Минус — медленнее.
- Playwright — современная альтернатива Selenium с поддержкой headless и автотестов.
- Requests + lxml — для быстрого парсинга с использованием XPath.
Выбор зависит от объёма данных, сложности рендеринга страницы и требований к скорости.
Практические рекомендации и эвристики
- Указывайте корректный User-Agent в заголовках, чтобы сервер не блокировал ваш бот.
- Не отправляйте запросы быстрее, чем 0.5–2 секунды между ними (в зависимости от сайта).
- Логируйте прогресс и ошибки — это упрощает повторный запуск.
- Используйте персистентный кеш (filesystem или Redis) для уже обработанных URL.
- При парсинге полей, которые могут отсутствовать, всегда проверяйте None и используйте fallback.
Мини‑методология — шаги от идеи до готового набора данных
- Определите требования: какие поля, формат, объём и частота обновлений.
- Проверьте доступность данных: API, публичные датасеты, robots.txt и условия сайта.
- Спроектируйте структуру хранения: CSV, Parquet, база данных.
- Напишите и протестируйте скрипт на небольшом количестве страниц.
- Запустите сбор с логированием и ограничением скорости.
- Очистите данные и добавьте метаданные (дата сбора, версия скрипта).
- Проведите контроль качества и тесты приёмки.
Чек-листы по ролям
Data Scientist:
- Проверил полноту ключевых полей (название, год, рейтинг).
- Убедился, что типы столбцов корректны.
- Прогнал базовый EDA (распределение рейтингов, частоты жанров).
Data Engineer:
- Настроил повторяемый пайплайн (cron/CI) и хранение данных.
- Добавил обработку ошибок, retries и мониторинг.
- Обеспечил резервное копирование собранных файлов.
Product Manager:
- Оценил соответствие набора требованиям продукта.
- Утвердил политику обновлений и допустимую частоту сбора.
- Проверил юридическую сторону и риски использования данных.
Риск‑матрица и mitigations
- Блокировка IP — Использовать медленные запросы, прокси, или согласовать доступ с владельцем сайта.
- Изменение HTML — Поддерживать тесты на стабильность селекторов, использовать CSS/XPath альтернативы.
- Неполные данные — Логировать пропуски и строить fallback-источники (например, другой сайт).
- Юридические риски — Согласование с юридическим отделом, запрос официального доступа.
Критерии приёмки
- Набор содержит по крайней мере N записей (по требованию проекта).
- Поля Title, Release Year и Rating заполнены в ≥ 95% записей.
- Данные валидны: Release Year в разумном диапазоне, Rating в 0–10.
- Скрипт завершается без критических ошибок и логирует пропуски.
Тестовые случаи и проверки
- Unit-тесты для функций extract_movie_data и get_soup с HTML-фрагментами.
- Интеграционный тест: запустить скрейпинг на 10 страницах и проверить размер и формат csv.
- Проверка регрессий: при изменении сайта селекторы должны быть протестированы.
Безопасность и приватность
Не храните или не собирайте персональные данные актёров/пользователей без основания. Держите секреты (если используются API-ключи и прокси) в защищённом хранилище (например, секреты CI/CD), а не в репозитории.
Локальные альтернативы и отклонения
Если вы работаете на территории, где доступ к IMDb ограничен или API недоступен, рассмотрите локальные базы данных фильмов или лицензированные поставщики данных. Учтите локальные ограничения по хранению и публикации контента.
Короткое руководство по миграции и масштабированию
- Для масштаба переходите на Scrapy или распределённые очереди (Celery/Kafka).
- Используйте Parquet/columnar storage для экономии места и ускорения аналитики.
- Вводите версионирование набора данных — versioning с датой и хешем скрипта.
Глоссарий (1‑строчно)
- Парсинг: извлечение структурированных данных из неструктурированного HTML.
- User-Agent: строка в HTTP-заголовке, идентифицирующая клиента.
- robots.txt: файл на сервере, указывающий правила для ботов.
Итог
Веб-скрейпинг — мощный инструмент для создания кастомных наборов данных, когда другие источники недоступны или не удовлетворяют требованиям. Правильная архитектура скрейпера, продуманная очистка данных и соблюдение этики/правил — ключ к качественному и воспроизводимому набору данных.
Важно: поддерживайте код и тесты, логируйте ошибки и документируйте метаданные набора. Удачи в сборе данных!
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
