Что делать, если нельзя выделить текст в PDF
.jpg)
Введение
Выделение текста в PDF помогает быстро находить важные фразы, экономит время при повторном просмотре и снижает умственное напряжение. Но если инструмент выделения не работает, это мешает работе. В этой статье мы подробно разберём, какие причины могут блокировать выделение и как их исправить: от простых проверок до использования OCR и смены программного обеспечения.
Почему нельзя выделить текст в PDF
Короткий ответ: документ либо не содержит «настоящего» текста, либо ограничен, либо проблема в программе. Вот основные причины:
- PDF — это изображение (скан). Внутри нет текстовых символов, только пиксели.
- Файл защищён паролем или автор установил ограничения (например, запрет на редактирование).
- В PDF‑просмотрщике отключена или некорректно работает функция выделения.
- Файл повреждён или частично скачан.
- Проблемы с самой операционной системой или её настройками.
Ниже — детальная инструкция по диагностике и решению.
6 способов устранить проблему с выделением текста в PDF
Ниже приведён упорядоченный план действий: начните с простых проверок и перейдите к более сложным мерам по надобности.
1. Выполните предварительные проверки
Перед серьёзными правками выполните базовые шаги:
- Убедитесь, что вы используете инструмент выделения именно так, как требует ваша программа. В некоторых приложениях выделение включается отдельной кнопкой или режимом.
- Перезапустите PDF‑просмотрщик — простая перезагрузка часто устраняет временные сбои.
- Не открывайте один и тот же файл в нескольких экземплярах одного и того же приложения. Закройте дубликаты и другие просмотрщики, где открыт тот же файл.
- Перезагрузите компьютер, чтобы исключить системные сбои.
- Проверьте, что файл скачан полностью и не повреждён. Попробуйте скачать документ ещё раз из надёжного источника.
- Откройте другой PDF, в котором вы точно раньше могли выделять текст. Если и там выделение не работает, проблема в ПО или системе.
Если эти шаги не помогли, идите к следующему пункту.
2. Убедитесь, что это не сканированный файл (используйте OCR)
Проблема чаще всего связана с тем, что PDF — это набор изображений страниц, полученных сканером. В таких файлах нет текстовых символов для выделения. Признаки сканированного PDF:
- Текст выглядит одинаково как картинка при сильном увеличении.
- Симметрия и выравнивание строки могут быть нарушены.
- Поиск по документу не находит слова, которые очевидно видны на странице.
Решение: примените OCR (оптическое распознавание символов). OCR анализирует изображение страницы и создаёт текстовый слой поверх изображения. После этого выделение и поиск заработают.
Как выполнить OCR — краткий алгоритм:
- Выберите сервис или приложение с OCR (например, PDF24, Smallpdf, Adobe Acrobat, ABBYY FineReader или другие надёжные инструменты).
- Загрузите сканированный PDF.
- Запустите процесс распознавания (иногда нуждается в выборе языка и уровня точности).
- Сохраните файл в формате PDF с текстовым слоем или экспортируйте в DOCX/RTF при необходимости.
Пример с онлайн‑инструментом:
- Откройте сайт с OCR.
- Нажмите кнопку «Выбрать файлы» и загрузите документ.
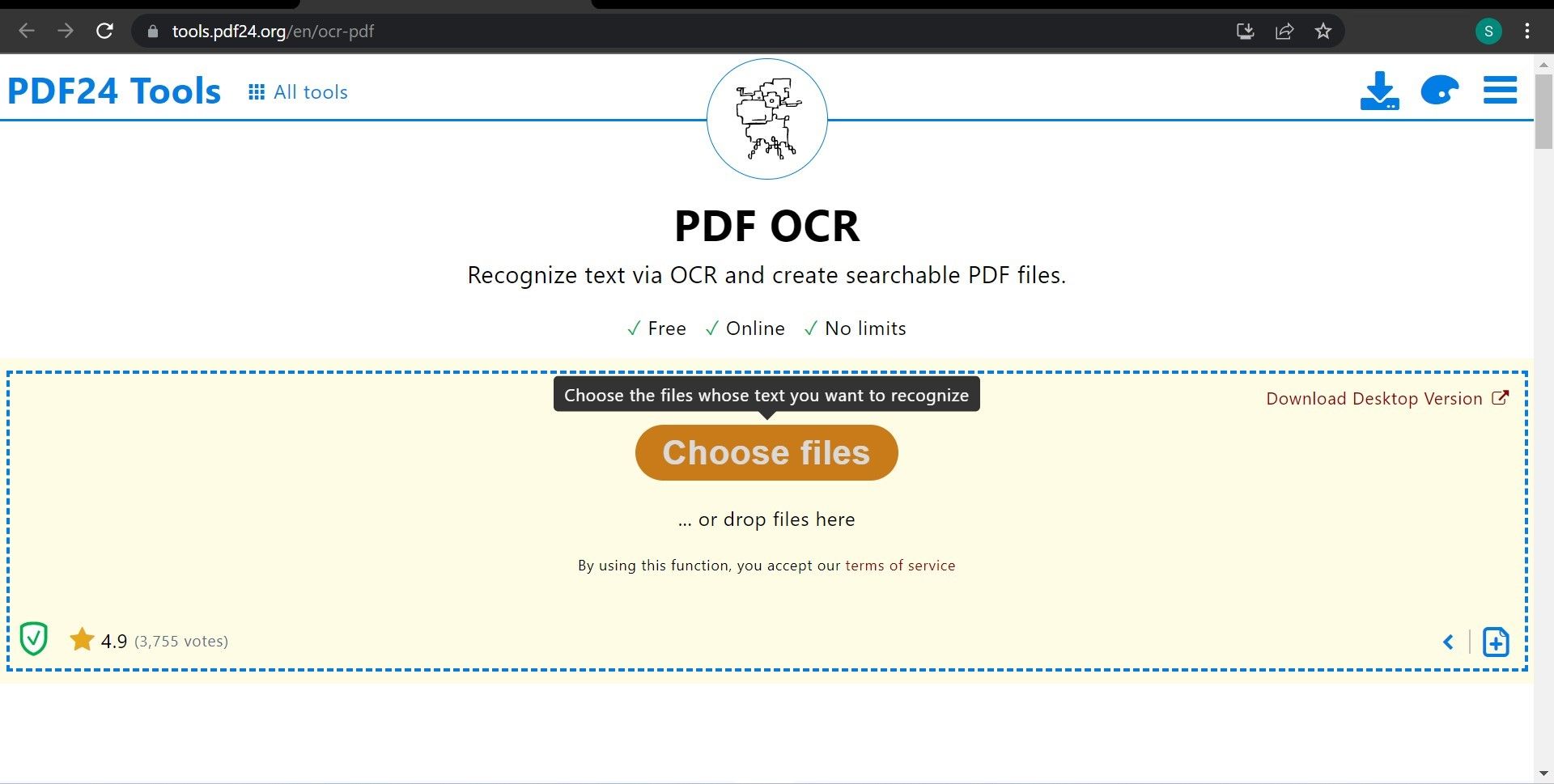
- Дождитесь окончания обработки.
- Скачайте конвертированную версию.
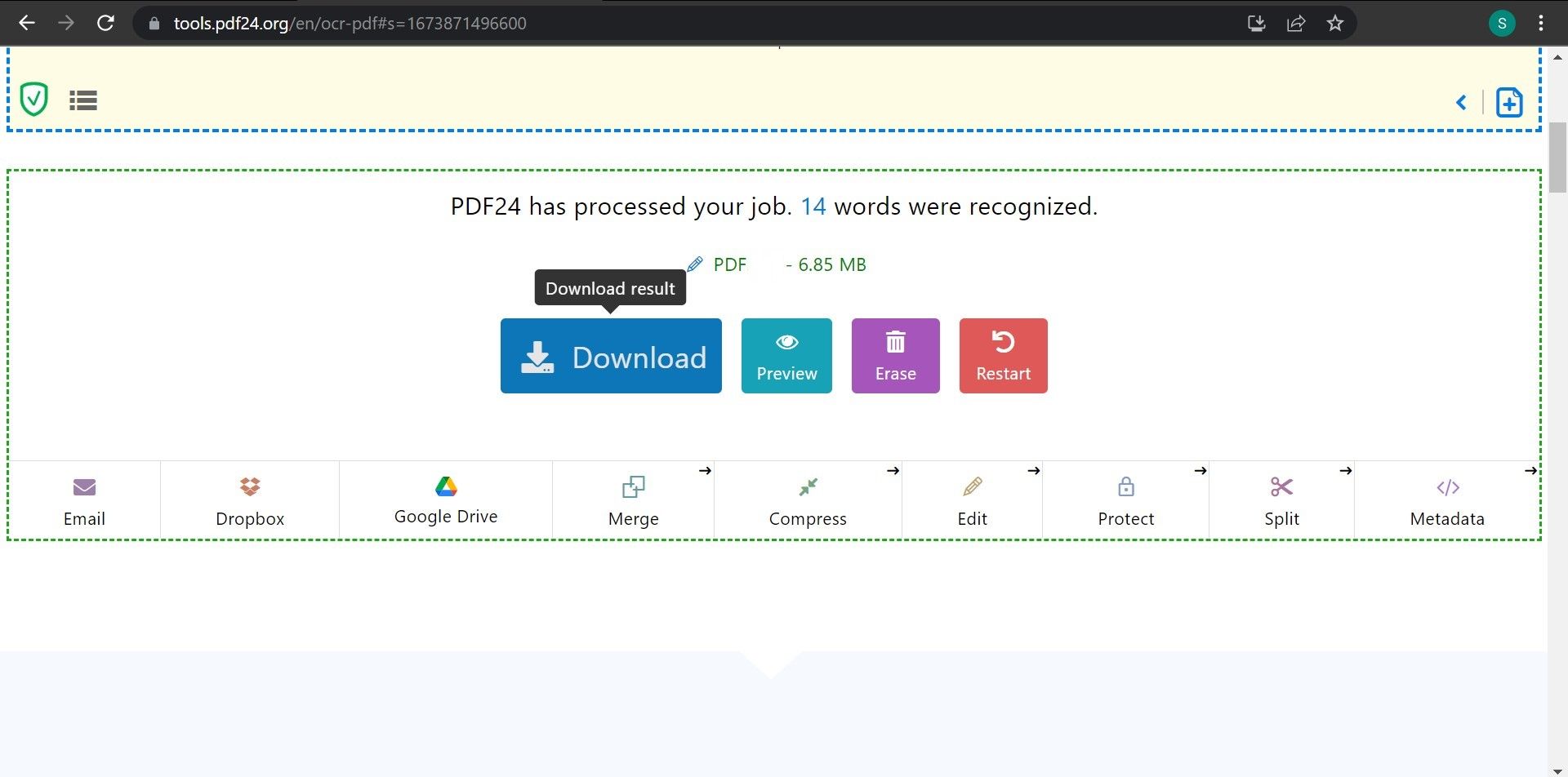
Важно: проверьте качество распознавания, особенно если в документе сложная верстка, таблицы или нестандартные шрифты.
Когда OCR может не помочь:
- Плохое качество скана (размытые, тёмные или искажённые страницы).
- Рукописный текст или декоративные шрифты.
В таких случаях потребуется ручная корректировка распознанного текста.
3. Проверьте, не ограничен ли PDF (зашифрован или в режиме «только для чтения»)
Автор документа может намеренно запретить редактирование и другие операции. Защищённый PDF может блокировать выделение, копирование и печать.
Как проверить и что делать:
- Откройте свойства документа в вашем PDF‑просмотрщике (обычно через меню «Файл» → «Свойства» или «Документ» → «Свойства»).
- Ищите раздел «Ограничения» или «Права»: там указывается, какие действия разрешены.
- Если видите запрет на редактирование или копирование, свяжитесь с автором и попросите версию без ограничений.
- Если автор недоступен и вы имеете законное право менять файл, используйте проверенные инструменты для снятия ограничений. Обратите внимание на юридическую сторону — не удаляйте защиту без разрешения.
Некоторые инструменты для восстановления доступа предоставляют опцию удаления ограничений, но успех зависит от уровня шифрования и наличия пароля.
4. Проверьте проблемы с программным обеспечением (PDF‑просмотрщик)
Иногда причина — в самом приложении. План действий:
- Откройте другой PDF в том же приложении и попытайтесь выделить текст. Если не работает и в другом документе, виноват просмотрщик.
- Попробуйте открыть проблемный файл в альтернативном просмотрщике (например, Adobe Acrobat Reader, Foxit Reader, SumatraPDF, встроенные средства браузера). Если в другом приложении выделение работает, значит, проблема — в исходной программе.
- Обновите приложение до последней версии — возможно, баг уже исправлен.
- Проверьте плагины и расширения, которые могут отключать функции просмотра (особенно в корпоративных сборках).
- Если приложение поддерживает «ремонт» или восстановление установки, воспользуйтесь этой возможностью.
Если ничего не помогает, переходите к полной переустановке (пункт 5).
5. Переустановите PDF‑программу
Если смена приложения помогла, но вы хотите остаться с прежним ПО, сделайте полную переустановку:
- Сохраните настройки и важные шаблоны (если нужно).
- Удалите программу через панель управления или «Приложения и возможности».
- Перезагрузите компьютер.
- Установите последнюю версию с официального сайта.
Переустановка устраняет повреждённые компоненты, сбросит битые плагины и вернёт стандартное поведение. Учтите: некоторые кастомные настройки придётся настроить заново.
6. Используйте альтернативные подходы и обходные пути
Если предыдущие пункты не помогли, примените альтернативы:
- Откройте PDF в веб‑браузере — современные браузеры поддерживают выделение и поиск.
- Экспортируйте PDF в DOCX или TXT через онлайн‑конвертер и выделяйте уже в текстовом редакторе.
- Сделайте снимки экранов и примените локальный OCR для конкретных фрагментов.
- Если вы работаете в корпоративной среде, обратитесь к ИТ‑администратору: возможно, политика безопасности блокирует функции.
Эти обходные пути помогут временно восстановить работоспособность, пока вы ищете долгосрочное решение.
Мини‑методология диагностики (быстрый план)
- Проверка простых вещей: перезагрузка, другой файл, обновление.
- Определение типа PDF: текстовый или скан (по поиску и увеличению).
- Проверка ограничений и прав доступа.
- Тест в другом просмотрщике и на другом устройстве.
- OCR или конвертация при необходимости.
Этот подход помогает быстро локализовать причину и сократить время на исправление.
Чек‑лист для ролей: пользователь и администратор
Чек‑лист для пользователя:
- Перезагрузил просмотрщик и компьютер
- Проверил, открывается ли другой PDF
- Убедился, что PDF не скан
- Пробовал открыть файл в браузере
- Попробовал онлайн‑OCR
Чек‑лист для администратора/ИТ:
- Проверил групповые политики и ограничения приложений
- Посмотрел логи установки/обновлений PDF‑ПО
- Убедился, что нет контроля целостности, блокирующего плагины
- Проверил наличие корпоративных плагинов, изменяющих поведение
Критерии приёмки
Чтобы считать проблему решённой, выполните проверку:
- Можно выделять текст в исходном PDF без ошибок.
- Поиск находит фразы и слова в документе.
- Копирование выделенного текста вставляется корректно (без лишанных символов).
- PDF открывается и выделение работает в целевом рабочем окружении пользователя.
Когда советы не помогут — контрпримеры
- Документ содержит рукописный текст. OCR даст низкое качество.
- Шифрование использует надёжный пароль и автор отказывается предоставить доступ.
- Документ очень повреждён: страницы частично отсутствуют или содержат артефакты сканирования.
В таких случаях возможно только частичное восстановление или ручная расшифровка/переввод текста.
Схема принятия решения (Mermaid)
flowchart TD
A[Начать диагностику] --> B{Работает выделение в другом PDF?}
B -- Да --> C{PDF — скан?}
B -- Нет --> D[Переустановить/сменить просмотрщик]
C -- Да --> E[Применить OCR]
C -- Нет --> F{Есть ограничения/шифрование?}
F -- Да --> G[Запросить неограниченную версию или снять защиту]
F -- Нет --> H[Проверить целостность файла и скачать заново]
D --> H
E --> I[Проверить результат: выделение доступно]
G --> I
H --> I
I --> J[Готово]Рекомендации по безопасности и конфиденциальности
- Не используйте сомнительные онлайн‑сервисы для конфиденциальных документов. Для чувствительных данных отдавайте предпочтение локальному ПО или корпоративным решениям.
- При снятии защиты с PDF убедитесь, что у вас есть на это право. Неправомерное снятие защиты может нарушать закон или политику компании.
Краткое резюме
Если выделение текста в PDF не работает, начинайте с простых проверок: перезапуск, открытие в другом просмотрщике, проверка типа файла. Если документ — скан, примените OCR; если файл защищён, запросите версию без ограничений или снимите защиту при наличии права. Переустановка или смена ПО часто решают программные проблемы. Для корпоративных пользователей обращайтесь к ИТ‑отделу.
Важно: всегда сохраняйте резервные копии оригинальных файлов перед любыми преобразованиями или снятием защиты.
Короткий чек‑лист действий для быстрого старта:
- Перезапустите приложение и компьютер.
- Откройте другой PDF — подтвердите проблему в ПО.
- Проверьте, скан или текстовый PDF.
- Если скан — примените OCR.
- Если защищён — запросите доступ или снимите защиту по правилам.
Желаем удачи — выделение текста вернётся, и вы снова сможете работать быстрее.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
