Guia prático de pandas e DataFrame em Python
Links rápidos
- O que é pandas?
- O que é um DataFrame?
- Como criar um DataFrame
- Importar um DataFrame
- Examinar um DataFrame
- Adicionar e excluir colunas
- Operações em colunas
O que é pandas?

pandas é uma biblioteca Python amplamente utilizada em ciência de dados e análise de dados. Em uma linha: pandas fornece estruturas (como DataFrame) e funções para organizar, filtrar, agregar e transformar dados tabulares. Foi inicialmente desenvolvido em contexto financeiro e posteriormente publicado como código aberto no final da década de 2000.
Por que usar pandas?
- Sintaxe expressiva para seleção e transformação de colunas.
- Integração com NumPy, Matplotlib e bibliotecas estatísticas.
- Suporte a leitura/escrita de CSV, Excel, SQL e mais.
Instalação (via PyPI):
pip install pandasRecomendação: use um ambiente virtual (venv, conda) e prefira executar código interativamente em Jupyter Notebook / JupyterLab para documentar e reexecutar análises.
Nota rápida: DataFrame é uma estrutura em memória. Para conjuntos de dados muito grandes, considere soluções out-of-core (Dask, Modin) ou bancos de dados.
O que é um DataFrame?
Um DataFrame organiza dados em linhas e colunas — semelhante a uma planilha ou tabela SQL. Cada coluna tem um rótulo (nome) e pode conter tipos diferentes: strings, inteiros, floats, datas. Pense no DataFrame como um dicionário de séries indexadas pelo mesmo eixo de linhas.
Termo definido: Série — uma coluna única dentro de um DataFrame; comporta-se como um array rotulado.
Quando usar um DataFrame
- Você precisa manipular tabelas com colunas heterogêneas.
- Quer aplicar filtros, agregações e junções rapidamente.
Quando não usar um DataFrame
- Dados muito grandes para memória (use Dask, Spark, bancos de dados).
- Quando deseja apenas cálculos numéricos vetoriais puros — NumPy pode ser mais simples.
Como criar um DataFrame
Exemplo passo a passo. Primeiro, crie um vetor x com NumPy e a função linear y = 2*x + 5.
import numpy as np
x = np.linspace(-10, 10)
y = 2 * x + 5Importe pandas e construa o DataFrame:
import pandas as pd
df = pd.DataFrame({'x': x, 'y': y})Boas práticas de nomes
- Use nomes de colunas descritivos (camel_case ou snake_case). Ex.: ‘idade’, ‘data_compra’.
- Evite espaços em nomes; prefira ‘Nome’ -> ‘nome’ ou ‘Nome_Completo’ -> ‘nome_completo’.
Alternativas para criação
- A partir de uma lista de dicionários: pd.DataFrame([{‘a’:1,’b’:2}, {‘a’:3,’b’:4}])
- A partir de um dicionário de listas (exemplo acima).
- A partir de uma série temporal: pd.DataFrame({‘valor’: series}, index=dates)
Importar um DataFrame
Arquivos tabulares são a fonte mais comum. Exemplos:
CSV:
df = pd.read_csv('/path/to/data.csv')Excel:
df = pd.read_excel('/path/to/spreadsheet.xlsx')Área de transferência (útil para copiar e colar pequenas tabelas):
df = pd.read_clipboard()Dicas de importação
- Sempre inspecione as primeiras linhas para confirmar separador e codificação.
- Se houver colunas de data, passe parse_dates=[‘col_data’] para converter ao importar.
- Para arquivos muito grandes, use iterator/chunksize ou ferramentas fora da memória.
Examinar um DataFrame
Comece sempre com inspeção rápida para entender tamanho, tipos e valores ausentes.
Exemplos básicos:
df.head() # primeiras 5 linhas
df.tail() # últimas 5 linhas
df.shape # (linhas, colunas)
df.columns # rótulos das colunas
df.info() # resumo dos tipos e contagem de não nulosVisualizar um subconjunto (fatiamento):
df[1:3] # linhas 1 e 2 (python slicing)
df.head(10) # primeiras 10 linhas
df.tail(10) # últimas 10Exemplo com dataset de exemplo (Titanic):
titanic = pd.read_csv('data/Titanic-Dataset.csv')
print(titanic.head())Estatísticas descritivas para colunas numéricas:
titanic.describe()O método describe() retorna: count, mean, std, min, 25%, 50%, 75%, max — o famoso resumo em cinco números (mínimo, Q1, mediana, Q3, máximo) complementado por contagem, média e desvio padrão.
Selecionar uma coluna e operações básicas:
titanic['Name'] # Série com nomes
titanic['Age'].mean()
# Para ver os valores sem truncamento
pd.set_option('display.max_rows', None)Aviso: ajustar pd.set_option pode gerar muita saída; use com cuidado.
Adicionar e excluir colunas
Você pode criar novas colunas a partir de operações entre colunas existentes.
Exemplo: elevar ao quadrado a coluna ‘x’ e atribuir a uma nova coluna ‘x2’.
df['x2'] = df['x'] ** 2
# remover coluna x2 (retorna cópia por padrão; use inplace=True para modificar o DataFrame original em versões que ainda suportem)
df = df.drop('x2', axis=1)Observações:
- axis=1 indica operação por coluna. axis=0 ou omitido refere-se a linhas.
- drop sem atribuição retorna uma cópia; use df.drop(…, inplace=True) com cuidado.
Operações em colunas
Você pode aplicar operações aritméticas, funções numpy e funções customizadas em colunas.
df['soma'] = df['x'] + df['y']
# aplicar função customizada
df['y_log'] = df['y'].apply(lambda v: np.log(abs(v) + 1))Selecionar várias colunas:
titanic[['Name', 'Age']]Filtro booleano (similar a WHERE no SQL):
titanic[titanic['Age'] > 30]Equivalente SQL:
SELECT * FROM titanic WHERE Age > 30Uso de loc e iloc:
titanic.loc[titanic['Age'] > 30, ['Name', 'Age']] # por rótulos
titanic.iloc[0:5, 0:3] # por posiçãoContagem de valores e visualização simples:
embarked = titanic['Embarked'].value_counts()
# renomear índices
embarked = embarked.rename({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'})
embarked.plot(kind='bar')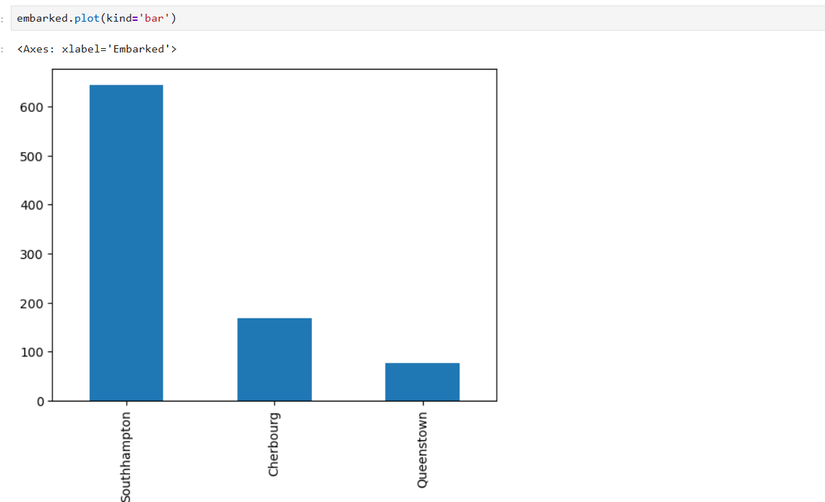
Limpeza e preparação de dados — mini metodologia
- Entenda as colunas: df.info() e df.describe().
- Identifique valores ausentes: df.isna().sum().
- Trate tipos: pd.to_datetime, astype().
- Trate duplicatas: df.drop_duplicates().
- Normalize rótulos: df[‘col’] = df[‘col’].str.strip().str.lower().
- Transforme/engenheire features conforme necessário.
Exemplo de limpeza rápida:
# remover duplicatas
df = df.drop_duplicates()
# preencher idades ausentes com a mediana
median_age = titanic['Age'].median()
titanic['Age'] = titanic['Age'].fillna(median_age)Quando pandas não é suficiente — alternativas
- Grandes volumes em memória: Dask, Modin, PySpark.
- Processamento em tempo real: bancos de dados, stream processing.
- Operações fortemente tipadas ou em coluna única: NumPy, SQL ou Arrow.
Heurísticas e modelos mentais
- Se precisar combinar várias tabelas, trate-as como tabelas SQL e prefira joins claros.
- Pensar por colunas: vectorize operações em vez de iterações com for.
- Na dúvida, explore com head() e value_counts() antes de aplicar transformações em massa.
Exemplos práticos e cheatsheet de seleções
Seleção e filtragem:
# coluna única
col = df['col']
# várias colunas
subset = df[['colA', 'colB']]
# filtro booleano
result = df[(df['a'] > 0) & (df['b'] == 'X')]
# loc por rótulo e iloc por posição
rows = df.loc[10:20, ['a', 'b']]Transformações comuns:
# renomear colunas
df = df.rename(columns={'old': 'new'})
# preencher valores nulos
df['col'] = df['col'].fillna('indefinido')
# converter tipo
df['data'] = pd.to_datetime(df['data'])Visualização rápida
pandas integra com Matplotlib. Exemplo:
df.plot(kind='line', x='x', y='y')Para gráficos mais sofisticados, exporte para Seaborn:
import seaborn as sns
sns.scatterplot(data=df, x='x', y='y')
Testes rápidos e critérios de aceitação
Para um DataFrame pronto para análise mínima:
- Deve existir >= 1 linha e >= 1 coluna.
- Todas as colunas necessárias devem ter o tipo esperado.
- Valores ausentes essenciais (chaves) devem ser imputados ou sinalizados.
Exemplo de checagem automatizada:
assert df.shape[0] > 0
assert 'id' in df.columns
assert df['data'].dtype == 'datetime64[ns]'Papel e checklist (por função)
Analista de dados
- Inspecionar dados (head, info, describe).
- Identificar missing values.
- Aplicar validações básicas.
- Documentar decisões de limpeza.
Cientista de dados
- Avaliar engenharia de features.
- Padronizar pipeline de transformação.
- Validar com amostras e testes unitários.
Engenheiro de dados
- Garantir ingestão confiável.
- Automatizar jobs e monitorar falhas.
- Gerenciar escalabilidade (chunksize, stream).
Playbook rápido para uma análise exploratória
- Carregar dados e salvar uma cópia bruta.
- rodar df.info(), df.describe(), df.isna().sum().
- Tratar colunas de data e tipos.
- Remover duplicatas e preencher nulos.
- Gerar estatísticas por grupo (groupby + agg).
- Visualizar distribuições e relações.
- Exportar resultados limpos.
Segurança, privacidade e conformidade
- Trate dados pessoais com cautela: remova ou pseudonimize nomes, e-mails e identificadores únicos antes de compartilhar.
- Para datasets com dados sensíveis, restrinja acesso e registre processamento.
- Em contexto GDPR: minimize dados, documente finalidade e aplique medidas técnicas e administrativas.
Matriz de riscos e mitigação (qualitativa)
- Perda de dados durante limpeza: manter cópia bruta.
- Exposição de PII: anonimizar e limitar logs.
- Processamento incorreto por tipos: validar tipos e limites.
Mitigações: versionar dados, criar testes automatizados e aplicar revisão por pares.
Exemplos de uso real e limites
- pandas é ideal para EDA (exploração de dados), preparação para modelagem e análises ad-hoc.
- Não é ideal para processamento distribuído em grandes clusters sem ferramentas complementares.
Fluxograma de decisão (Mermaid)
flowchart TD
A[Tenho dados tabulares?] -->|Sim| B{Caberão na memória?}
A -->|Não| Z[Outro formato: JSON/Texto]
B -->|Sim| C[Usar pandas]
B -->|Não| D[Usar Dask/Modin/Spark ou BD]
C --> E[Limpeza e EDA]
E --> F[Modelagem/Visualização]Glossário (uma linha cada)
- DataFrame: estrutura tabular com linhas e colunas.
- Série: coluna única rotulada dentro de um DataFrame.
- EDA: exploração de dados (Exploratory Data Analysis).
Compatibilidade e migração
- Antes de atualizar pandas, confira notas de versão da biblioteca e test suite do seu projeto.
- Scripts antigos podem depender de comportamento obsoleto (ex.: inplace) — revise e normalize código.
Resumo
Este guia mostrou os conceitos básicos e práticas recomendadas para começar com pandas e DataFrame: criação, importação, inspeção, transformação e visualização. Inclui playbook, checklist por função, dicas de privacidade e alternativas quando os dados não cabem em memória.
Importante: documente as transformações aplicadas ao DataFrame para que você (ou sua equipe) possa reproduzir a análise no futuro.
Se quiser, posso gerar um notebook Jupyter de exemplo com todo este fluxo, pronto para executar passo a passo.
Materiais semelhantes

Instalar e usar Podman no Debian 11
Apt‑pinning no Debian: guia prático
Injete FSR 4 com OptiScaler em qualquer jogo
DansGuardian e Squid com NTLM no Debian Etch

Corrigir erro de instalação no Android
