Ataque Man-in-the-Prompt: como funciona e como se proteger

O que é um ataque Man-in-the-Prompt?
Definição rápida: um ataque man-in-the-prompt é quando um ator malicioso injeta instruções — visíveis ou ocultas — no fluxo de interação entre você e um modelo de linguagem, levando o modelo a revelar segredos ou a executar respostas maliciosas.
É análogo a um man-in-the-middle, mas o alvo é o prompt e a conversa com o LLM. O atacante altera o contexto que o modelo vê e assim manipula o resultado.
Vetores comuns
- Extensões de navegador com acesso ao DOM da página do chatbot.
- Ferramentas de geração de prompts que alteram templates antes de enviar.
- Scripts de automação ou integrações de terceiros configuradas sem revisão.
- Ambientes corporativos onde modelos privados têm acesso a dados sensíveis.
Por que LLMs privados e chatbots personalizados são vulneráveis
LLMs privados frequentemente têm acesso a documentos internos, chaves de API e dados regulados. Se um atacante alterar o prompt, o LLM pode retornar dados confidenciais. Chatbots personalizados mantêm histórico e contexto — o histórico é uma superfície de ataque que pode ser explorada.
Detectando extensões suspeitas
- Evite instalar extensões sem reputação comprovada.
- Revise permissões e autorizações antes da instalação.
- Use o Gerenciador de Tarefas do navegador (pressione Shift + Esc em muitos navegadores) para ver processos em execução que correspondam a extensões quando estiver usando um LLM.
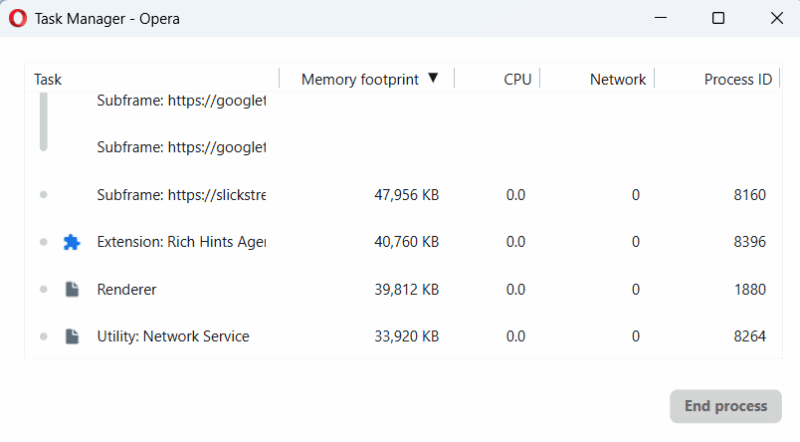
Se uma extensão dispara atividade só quando você digita no chatbot, isso pode indicar que ela está alterando o DOM ou o prompt.
Importante: extensões que interagem diretamente com a interface do LLM podem funcionar corretamente no início e se tornar maliciosas depois de uma atualização. Monitore e audite periodicamente.
Boa prática: digite prompts manualmente e revise antes de enviar
- Sempre verifique o prompt no campo de entrada antes de pressionar Enter.
- Se copiar de fontes externas, cole primeiro em um editor de texto simples (por exemplo, o Bloco de Notas) para expor caracteres ocultos.
- Remova espaços em branco estranhos com Backspace; caracteres invisíveis podem portar instruções embutidas.
- Prefira manter templates próprios em um gerenciador de notas seguro.
Inicie novas sessões ao mudar de tópico
Mudar de conversa reduz risco de exposição de dados anteriores. Se você compartilhou informações sensíveis num chat, abra uma nova sessão ao tratar de assuntos diferentes.
Abrir nova conversa também limita o alcance de instruções injetadas que tentem afetar o histórico inteiro.
Inspecione as respostas do modelo
- Seja cético: não aceite respostas inesperadas sem checagem.
- Procure por padrões estranhos: pedidos adicionais no final das respostas, blocos de código inesperados, tabelas que contêm dados sensíveis ou instruções de ação.
- Se o modelo revelar segredos sem solicitação, encerre a sessão e reporte.
Observação: atacantes podem instruir o LLM a formatar dados em blocos de código ou tabelas para contornar verificações humanas — fique atento a anomalias de formato.
Detecção técnica e logs
- Ative auditoria e logging do lado do cliente e servidor (onde aplicável).
- Registre alterações no DOM e chamadas de rede originadas por extensões ou scripts de terceiros enquanto o usuário usa o LLM.
- Use listas de bloqueio (blocklists) para extensões conhecidas e listas de permissão (allowlists) em ambientes corporativos.
Playbook de prevenção (SOP rápido)
- Inventário: liste todas as extensões e integrações que interagem com LLMs.
- Revisão: verifique permissões e fontes; atualize políticas de instalação.
- Treinamento: ensine usuários a digitar prompts manualmente e revisar antes de enviar.
- Isolamento: use perfis separados do navegador ou modo incógnito sem extensões para uso sensível.
- Auditoria contínua: verifique logs, mudanças de configuração e atualizações de extensões.
Runbook de incidente
- Identificação: usuário reporta comportamento anômalo ou vazamento.
- Contenção: encerre a sessão afetada; desconecte integrações externas.
- Coleta: preserve logs do navegador, lista de extensões, e histórico do chat (se permitido por políticas de privacidade).
- Remoção: desative/desinstale extensões suspeitas e bloqueie-as centralmente.
- Recuperação: inicie novas sessões seguras e revalide credenciais/segredos.
- Lições: documente o incidente, atualize SOPs e treine equipe.
Lista de verificação por função
Usuário final
- Não instale extensões desconhecidas.
- Sempre revisar prompts e respostas.
- Use modo incógnito para tarefas sensíveis.
Administrador de TI
- Mantenha uma allowlist de extensões.
- Implemente bloqueio centralizado e monitore inventário.
- Forneça navegadores/padrões aprovados.
Equipe de Segurança
- Audite logs do lado servidor e cliente.
- Teste vetores de injeção de prompt em ambientes controlados.
- Estabeleça políticas de resposta a incidentes.
Desenvolvedor/Integrações
- Evite injetar conteúdo não sanitizado nos prompts.
- Assine e valide templates de prompts.
- Implemente testes automatizados para detectar mudanças inesperadas.
Testes e critérios de aceitação
- Teste: simular uma extensão que injeta texto no campo do prompt.
- Aceitação: sistema detecta alteração no DOM e gera um alerta.
- Teste: colar template com caracteres invisíveis.
- Aceitação: processo de pré-validação identifica caracteres não imprimíveis.
- Teste: mudança de tópico sem nova sessão.
- Aceitação: política força criação de sessão nova quando dados sensíveis foram compartilhados.
Mini-metodologia de auditoria para prompts
- Coletar: capture o HTML da página durante interações com LLMs.
- Comparar: verifique diferenças entre o texto original do usuário e o prompt final enviado.
- Classificar: rotule alterações como esperadas, potencialmente maliciosas ou suspeitas.
- Mitigar: bloquear fontes suspeitas e notificar proprietários.
Modelos mentais úteis
- Caixa preta vs. caixa branca: trate prompts como entrada crítica que deve ser controlada (caixa branca) em ambientes sensíveis.
- Mínimo privilégio: dê ao modelo acesso apenas ao contexto necessário.
- Separação de ambientes: use ambientes distintos para dados sensíveis e testes.
Quando este controle pode falhar
- Se o usuário confiar cegamente em templates de terceiros e não revisar.
- Se atualizações legítimas de extensões incluírem funcionalidades maliciosas posteriormente.
- Se integrações do lado servidor injetarem conteúdo sem validação.
Hardening de segurança recomendado
- Forneça navegadores corporativos com extensões bloqueadas por padrão.
- Use perfis isolados para tarefas sensíveis.
- Revise e limite escopos de tokens e chaves de API acessíveis via LLM.
- Implemente assinaturas digitais para templates de prompt críticos.
Notas de privacidade e conformidade (GDPR e similares)
- Minimize logs que contenham dados pessoais; quando registrar, anonimizar ou pseudonimizar.
- Quando houver vazamento de dados pessoais, siga a política interna e os requisitos regulatórios de notificação.
- Documente consentimento e propósito do processamento ao usar LLMs com dados pessoais.
Contraexemplos e alternativas
- Alternativa ao bloqueio de extensões: ambientes seguros (VMs, navegadores gerenciados) que isolam o uso do LLM.
- Quando o ataque falha: se o LLM estiver executando validações internas de instruções (por exemplo, verificação de integridade do prompt) ou a interface cliente usar assinaturas, a injeção pode não surtir efeito.
Glossário rápido
- LLM: modelo de linguagem de grande escala.
- DOM: Document Object Model, estrutura da página web.
- Prompt: entrada de texto enviada ao modelo.
Exemplo de diagnóstico (fluxo em Mermaid)
flowchart TD
A[Usuário digita prompt] --> B{Extensão instalada?}
B -- Sim --> C{Extensão altera DOM?}
C -- Sim --> D[Prompt modificado enviado ao LLM]
C -- Não --> E[Prompt original enviado]
B -- Não --> E
D --> F{Resposta contém anomalia?}
F -- Sim --> G[Alerta e encerrar sessão]
F -- Não --> H[Continuar conversa]Mensagem curta para anunciar mudança de política interna (100–200 palavras)
Atenção equipe: estamos implementando novas medidas para reduzir riscos de injeção de prompts em nossos sistemas de IA. A partir de hoje, somente extensões aprovadas pela TI poderão ser usadas em navegadores corporativos. Pedimos que todos evitem o uso de templates de prompts de terceiros sem validação e que iniciem novas sessões sempre que tratarem de informações sensíveis. A equipe de Segurança realizará auditorias periódicas e fornecerá listas de verificação para ajudar na revisão de prompts. Em caso de comportamento anômalo do chatbot, encerre a sessão e reporte imediatamente ao time de segurança.
Sumário e próximos passos
- Ataques man-in-the-prompt manipulam o contexto visto pelo LLM.
- Extensões e ferramentas de prompt são vetores principais.
- Controle básico: use extensões confiáveis, digite prompts manualmente, comece novas sessões para tópicos sensíveis.
- Avance com políticas corporativas: allowlist de extensões, auditoria de logs, e treinamentos para usuários.
Se quiser, eu posso gerar: (1) uma política de instalação de extensões pronta para ser adaptada pela sua TI; (2) um checklist imprimível para treinar funcionários; ou (3) um conjunto de casos de teste automatizados para detectar injeção de prompts no seu ambiente.
Materiais semelhantes

Instalar e usar Podman no Debian 11
Apt‑pinning no Debian: guia prático
Injete FSR 4 com OptiScaler em qualquer jogo
DansGuardian e Squid com NTLM no Debian Etch

Corrigir erro de instalação no Android
