Monitoramento de discos com smartmontools e SMART
O que é SMART
SMART é um conjunto de mecanismos internos de dispositivos de armazenamento que reporta atributos de saúde e permite executar autotestes. Definição em uma linha: SMART é um recurso do firmware do disco que mede condições que podem indicar falha iminente.
Importante: SMART não prevê 100% das falhas. Ele aumenta a janela de tempo para backup e substituição, mas não substitui estratégias de redundância e backup regulares.
Objetivos deste artigo
- Mostrar como instalar smartmontools em distribuições Linux comuns.
- Explicar o uso de smartctl para inspeções manuais e autotestes.
- Ensinar a configurar smartd para monitoramento contínuo e alertas.
- Fornecer um playbook de resposta, verificações e melhores práticas.
Palavras-chave principais (intenção)
- Monitorar disco
- smartmontools
- SMART
- smartctl
- smartd
Instalação
smartmontools está disponível na maioria dos repositórios das distribuições Linux.
Debian / Ubuntu:
sudo apt-get update
sudo apt-get install smartmontoolsFedora (yum ou dnf):
# com yum
sudo yum install smartmontools
# com dnf
sudo dnf install smartmontoolsOutras distribuições normalmente possuem um pacote equivalente chamado smartmontools. Em sistemas baseados em BSD ou macOS, verifique o gerenciador de pacotes da plataforma.
Observação: a instalação disponibiliza duas ferramentas principais: smartctl (uso interativo) e smartd (daemon para monitoramento contínuo).
smartctl — inspeções manuais e autotestes
smartctl requer privilégios de root. Ele atua sobre dispositivos inteiros (por ex. /dev/sda), não sobre partições.
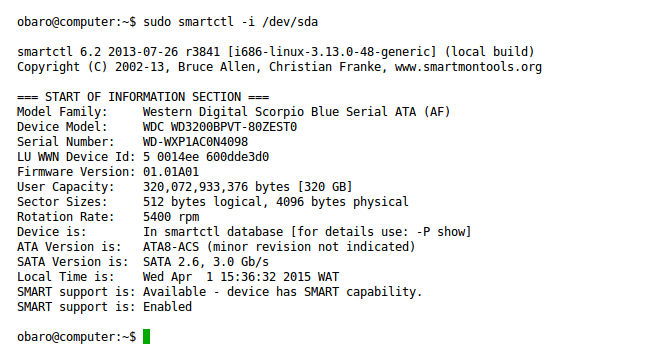
Exemplo: obter informações do dispositivo
sudo smartctl -i /dev/sda
Interpretação rápida:
- Procure por linhas que indiquem “SMART support: Available/Enabled” (disponível/ativado).
- Se SMART estiver disponível, mas desabilitado, ative com:
sudo smartctl -s on /dev/sdaVerificar o estado geral do dispositivo:
sudo smartctl -H /dev/sda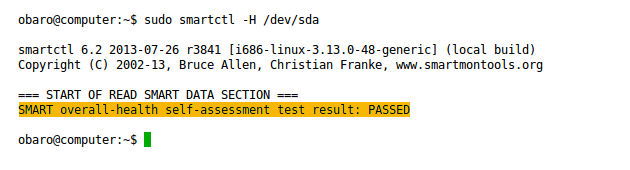
Se a saída não mostrar “PASSED” (ou equivalente), considere o disco em risco e faça backup imediatamente.
Ver capacidades SMART e tempos estimados de autotestes:
sudo smartctl -c /dev/sda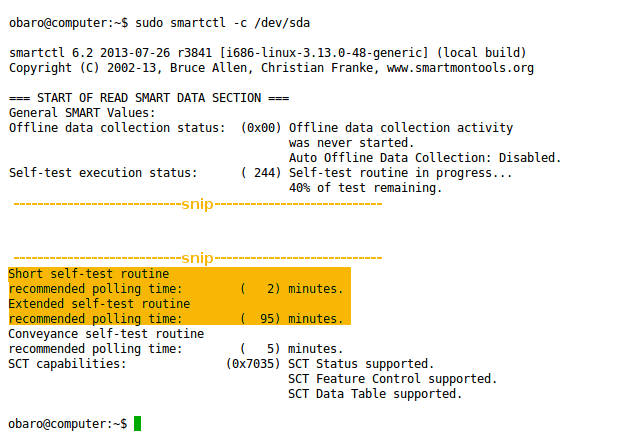
Ex.: tempos estimados podem ser 2 minutos para short e 95 minutos para long. Execute um autoteste curto:
sudo smartctl -t short /dev/sda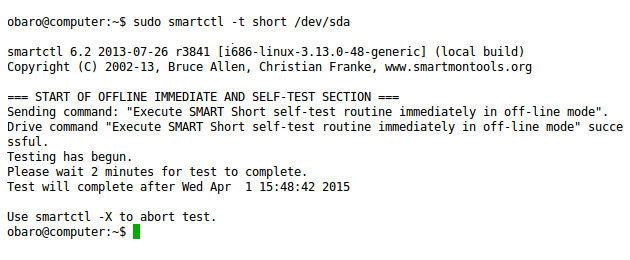
O autoteste roda em background. Para consultar resultados e histórico de selftests:
sudo smartctl -l selftest /dev/sdaPara iniciar um autoteste estendido (mais completo):
sudo smartctl -t long /dev/sdaSe qualquer autoteste retornar falha, faça backup imediato e substitua o dispositivo.
Dica: em sistemas com discos NVMe, use nvme-cli (nvme smart-log) em vez de smartctl para métricas específicas de NVMe.
Interpretando atributos SMART (resumo rápido)
- Reallocated_Sector_Ct: setores remapeados — aumento indica degradação.
- Current_Pending_Sector: setores pendentes de realocação — risco imediato.
- UDMA_CRC_Error_Count: erros de comunicação — verifique cabos/firmware.
- Power_On_Hours: horas de operação — útil para histórico de uso.
Regra prática: aumento contínuo de setores realocados ou pendentes requer ação imediata.
smartd — monitoramento contínuo e alertas
smartd é um daemon que consulta SMART periodicamente e envia alertas quando há problemas. Arquivo de configuração padrão: /etc/smartd.conf.
Passos básicos:
- Edite /etc/smartd.conf.
- Comente (ou remova) linhas genéricas como DEVICESCAN para evitar monitorar dispositivos não desejados.
- Liste explicitamente os dispositivos a monitorar.
Exemplo de entrada recomendada (ajuste conforme necessário):
/dev/sda -a -o on -S on -s (S/../.././02|L/../../6/03) -m root -M exec /usr/share/smartmontools/smartd-runnerExplanação das opções principais:
- /dev/sda: arquivo do dispositivo.
- -a: ativa um conjunto comum de opções úteis.
- -o on: ativa testes offline automáticos.
- -S on: ativa salvamento automático de atributos SMART.
- -s (S/../.././02|L/../../6/03): agenda autotestes. Neste exemplo, short diário às 02:00 e long semanal aos sábados às 03:00 (formato HH:MM em 24h).
- -m root: envia alertas por email para root (pode listar múltiplos endereços separados por vírgulas).
- -M exec /usr/share/smartmontools/smartd-runner: invoca um script adicional que permite ações extras além do envio de e-mail (padrão em Debian/Ubuntu).
Nota sobre tipo de dispositivo: se smartctl exige um parâmetro -d TYPE (ex.: -d sat, -d ata), smartd também pode precisar desse parâmetro na mesma linha.
Após editar, habilite o serviço para iniciar automaticamente.
Em sistemas System V / SysVinit (ou compatíveis):
# habilitar no arquivo /etc/default/smartmontools removendo #start_smartd=yes
sudo /etc/init.d/smartmontools startEm sistemas systemd:
sudo systemctl enable --now smartd.servicePara reiniciar e aplicar mudanças:
sudo systemctl restart smartd.service
# ou, em distribuições sem systemd
sudo /etc/init.d/smartmontools restartPara testar a notificação por email, você pode adicionar a opção -M test à linha do dispositivo e reiniciar o daemon; isso força o envio de um teste.
Exemplo prático de /etc/smartd.conf (trecho)
# Exemplo: monitorar dois discos, enviar alertas para admin@example.com
/dev/sda -a -o on -S on -s (S/../.././02|L/../../6/03) -m admin@example.com -M exec /usr/share/smartmontools/smartd-runner
/dev/sdb -a -d sat -o on -S on -s (S/../.././02|L/../../6/03) -m admin@example.comCertifique-se de que o sistema pode realmente enviar emails (ex.: postfix, ssmtp ou um relay SMTP configurado).
Playbook de resposta a alerta SMART (incidente)
- Recebeu alerta por email sobre atributo crítico ou autoteste falho.
- Verifique rapidamente o estado com:
sudo smartctl -a /dev/sdX- Execute um autoteste curto e / ou long conforme tempo disponível:
sudo smartctl -t short /dev/sdX
# ou
sudo smartctl -t long /dev/sdX- Agende imediatamente backup de dados críticos (priorize volumes mais importantes).
- Planeje substituição do dispositivo e, se aplicável, reconstrução de RAID/espelhamento.
- Depois de substituir, documente tempo de falha, atributos críticos e ações tomadas.
Critérios de gravidade (heurística):
- Alta: Current_Pending_Sector > 0 ou falha em autoteste → backup imediato e substituição.
- Média: crescimento constante de Reallocated_Sector_Ct → monitorar em 24–72 h e preparar substituição.
- Baixa: UDMA_CRC_Error_Count isolado → verificar cabos e logs de I/O.
Testes e critérios de aceitação para monitoramento
- smartd envia email de teste com -M test.
- smartd realiza autoteste short conforme agendamento (verificar syslog para entrada de início).
- smartd reporta falha detectada via email e via syslog.
- smartctl -l selftest mostra histórico atualizado.
Limitações e quando SMART falha
- Nem todos os problemas físicos são representados por atributos SMART.
- Falhas eletrônicas súbitas ou problemas de controlador podem ocorrer sem sinais prévios.
- SSDs têm atributos SMART diferentes dos HDDs; para NVMe use nvme-cli.
Counterexample rápido: um disco pode falhar de forma cataclísmica por causa de um curto no controlador sem aumento prévio em setores realocados — nesse caso SMART não alertou antes.
Abordagens alternativas e complementares
- RAID com monitoramento do controlador (RAID hardware/firmware).
- Sistemas de arquivos/backup com versionamento e testes de restauração periódicos.
- Ferramentas de monitoramento (Prometheus + node_exporter com exportadores SMART) para métricas históricas e alertas avançados.
- Serviços de saúde de disco do fabricante (ex.: SeaTools, WD Data Lifeguard) para diagnósticos proprietários.
Maturidade de uma estratégia de monitoramento SMART
- Nível 1 (Básico): smartctl manual + autotestes ocasionais.
- Nível 2 (Operacional): smartd com emails e testes agendados.
- Nível 3 (Avançado): integração com sistema de monitoramento centralizado (alertas, histórico, dashboards) e playbooks automatizados.
Segurança, privacidade e considerações locais
- Alertas por email podem expor nomes de host e caminhos de dispositivo; garanta envio seguro (STARTTLS/TLS) para servidores de e-mail.
- Em ambientes regulamentados (ex.: dados pessoais), registre eventos de falha e mantenha cadeia de custódia para auditoria.
- Para administradores em países com restrições, verifique políticas internas de transmissão de logs e dados.
Checklist por função
Administrador de Sistemas:
- Habilitar smartd e garantir envio de email.
- Verificar agenda de autotestes e logs no syslog/journal.
- Testar playbook de substituição de disco.
SRE/Operações:
- Integrar métricas SMART ao monitoramento central.
- Definir SLO/alertas e manter runbooks atualizados.
Usuário doméstico / power user:
- Executar smartctl -a regularmente.
- Ter backups off-site ou em nuvem.
Migração e substituição de disco — passos práticos
- Validar backup íntegro (testar restauração mínima).
- Substituir disco com procedimento seguro (power-down se necessário ou hot-swap se suportado).
- Reconstruir volumes lógicos/RAID e verificar integridade dos dados.
- Documentar o incidente e atualizar monitoramento (ex.: marcar disco substituído em inventário).
Testes recomendados (casos de aceitação)
- Caso: notificação por erro SMART. Aceitação: email recebido em menos de 5 minutos, entrada no syslog com identificação do bloco afetado.
- Caso: autoteste agendado. Aceitação: execução confirmada no horário e log com duração estimada.
Perguntas frequentes rápidas
- Posso usar smartmontools com SSDs? Sim; porém alguns atributos e comportamentos mudam. Para NVMe, use ferramentas nvme-cli.
- SMART substitui backups? Não. SMART reduz risco, mas não garante prevenção de perda de dados.
Resumo final
SMART e smartmontools fornecem camadas valiosas de proteção proativa. smartctl é ótimo para diagnósticos ad-hoc; smartd garante vigilância contínua com alertas. Combine com backups regulares, monitoramento centralizado e procedimentos claros de substituição para reduzir tempo de indisponibilidade.
Principais recomendações:
- Habilite SMART e verifique com smartctl -i.
- Configure smartd para alertas e autotestes agendados.
- Tenha sempre backups testados; prepare substituição quando atributos críticos aumentarem.
Social preview (sugestão curta): Monitoramento proativo de discos com smartmontools: configure smartctl e smartd, agende autotestes e garanta alertas para proteger seus dados.
Anúncio curto (120–160 palavras): smartmontools permite transformar sinais internos do disco em avisos úteis. Ao combinar verificações manuais com smartctl e monitoramento contínuo via smartd, administradores ganham tempo para executar backups e trocar unidades antes da falha. Este guia explica instalação, comandos essenciais, configuração de smartd, cronograma de autotestes e um playbook de resposta a incidentes. Inclui também dicas para SSD/NVMe, integração com sistemas de monitoramento e considerações de segurança. Ideal para administradores de servidores, SREs e usuários avançados que querem reduzir risco de perda de dados.
Observações finais
Mantenha registros de incidentes e revise políticas de substituição periodicamente. SMART dá uma vantagem operacional — use-a como parte de uma estratégia mais ampla de confiabilidade.
Materiais semelhantes

Instalar e usar Podman no Debian 11
Apt‑pinning no Debian: guia prático
Injete FSR 4 com OptiScaler em qualquer jogo
DansGuardian e Squid com NTLM no Debian Etch

Corrigir erro de instalação no Android
