Ubuntuで使う3つのLinux監視ツール
重要: 監視ツールは情報を提供しますが、原因特定と対策は運用者の判断が必要です。root権限が必要な操作がある点に注意してください。
概要
システム監視は、パフォーマンス改善、障害原因の特定、的確な対処のために不可欠です。ここではUbuntu上でインストールし、実行する方法を中心に、使い方のコツと運用上のチェックリストを示します。対象はデスクトップとサーバーの両方です。
GNOME System Monitor
GNOMEのシステムモニターは、GUIで主要なリソース使用状況を一目で把握できます。CPU負荷、メモリ使用量、スワップ利用、ディスク使用、ネットワーク送受信が確認できます。
インストールはパッケージマネージャーから選ぶか、端末で以下を実行します。
sudo apt-get install gnome-system-monitor
最初のタブはプロセス管理です。実行中のプロセスを確認し、メモリやCPUで並べ替えられます。右下の「End Process」ボタンで選択プロセスを終了できます。Viewメニューの「Dependencies」を有効にするとツリー表示で子プロセスが見えます。
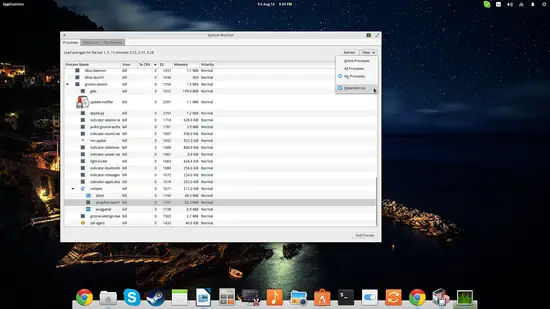
2番目のタブはCPU(各コア別表示)、メモリ、スワップ、ネットワークの使用履歴を描画します。特定の時間帯での負荷を視覚的に探るのに便利です。ただし履歴表示の時間幅を伸ばす設定は標準UIでは限定的です。
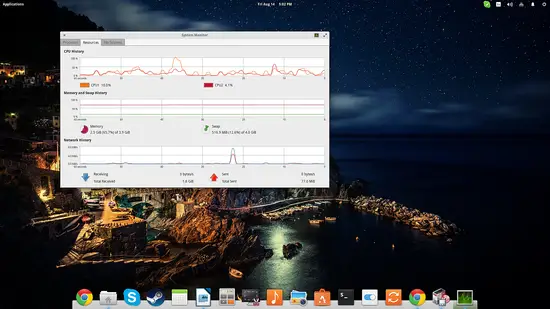
使いどころ:
- デスクトップでの簡易チェックや、新人への説明に最適。
- GUIでプロセスを直感的に操作したい場面。
制限:
- 長期間の履歴収集やアラートには向かない。PrometheusやNetdataの導入を検討してください。
top と htop
ターミナルで即座に確認したい場合はまず “top” を実行します。
toptopは現在動作中のプロセスを一覧表示します。CPU使用率でソートするには “P” を押します。短時間で状況把握するのに最適です。
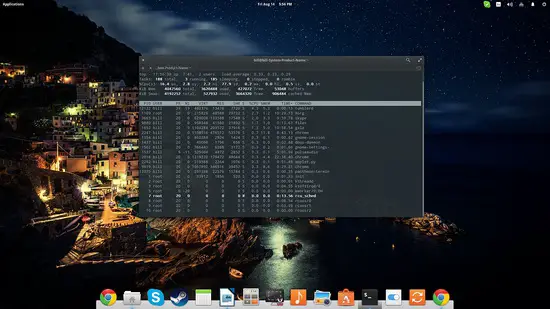
htopはtopの機能拡張版です。インストールは:
sudo apt-get install htop実行:
htophtopは色付きの視覚表示、複数ソート、ファンクションキー(F1〜F10)による操作などを備え、プロセス殺処理やフィルタが簡単です。CPUコアごとの負荷も見やすく、インタラクティブなトラブルシューティング向きです。
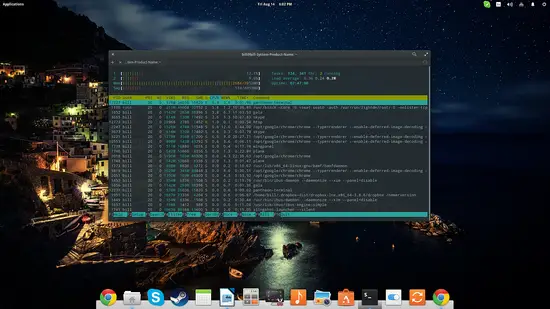
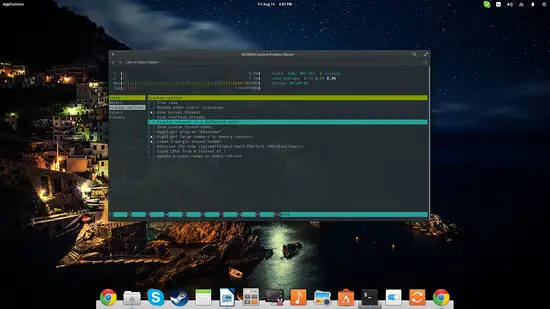
使いどころ:
- SSHでのリモート診断や、短時間でプロセスの問題を切り分ける時。
- スクリプトからの自動化には適さない(非永続的な表示)。
ヒント:
- topはほとんどの環境でプリインストールされています。htopはインストール後に使ってみてください。
lm-sensors
lm-sensorsは温度、ファン回転数、電圧などハードウェアの状態を表示します。ハードウェアの過熱や電源問題の早期発見に有効です。
インストール:
sudo apt-get install lm-sensors初回はセンシング用の検出を行うために sensors-detect を走らせることが推奨されます(対話的に進みます)。その後、以下で表示します。
sensors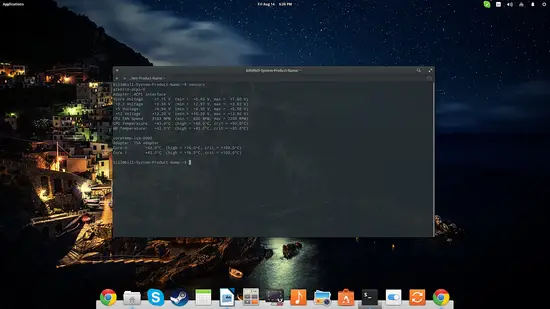
サーバー管理者はGUIで遠隔監視できる psensors パッケージも検討できます。
注意:
- sensors-detect 実行にはroot権限が必要です。
- 一部のハードウェアはセンサー情報を提供しない場合があります。
小さな運用手順(ミニ手順)
- まずGUIで全体を把握:GNOME System Monitorを起動。
- 異常があれば端末で詳細確認:htopでプロセスを絞る。
- 高温や電源の疑いがあるなら lm-sensors をチェック。
- 継続監視とアラートが必要ならPrometheus/Netdata/Zabbix等を導入。
役割別チェックリスト
システム管理者:
- htopでCPU・メモリのスパイク原因を特定する。
- lm-sensorsで温度・ファン回転を確認する。
- ログ(/var/log)と組み合わせて根本原因を探る。
デスクトップユーザー:
- GNOME System Monitorで重いアプリを特定する。
- 一時的な負荷ならアプリ終了で対応。
サーバー運用者:
- 長期データとアラートが必要ならPrometheusやZabbixを検討。
- psensorsなどGUIの遠隔監視は管理用途に便利。
代替アプローチと限界
- 長期の履歴保存やアラートが必要な場合: Prometheus + Grafana、Zabbix、Netdataなどを使ってください。
- 高頻度の短時間スパイク解析には perf や eBPFベースのツールが有効です。
- これらのGUI/CLIツールは原因の候補を示しますが、自動修復は行いません。
トラブル時の簡易フローチャート
flowchart TD
A[異常検知] --> B{CPU高負荷?}
B -- はい --> C[htopでプロセス特定]
B -- いいえ --> D{高温?}
D -- はい --> E[lm-sensorsで温度確認]
D -- いいえ --> F[ネットワーク負荷を確認]
C --> G[プロセス終了 or 再起動]
E --> H[冷却対策 or ハードウェア確認]
F --> I[ss/iftopでトラフィック分析]受け入れ基準
- 監視を導入したら、最低1週間は毎日ダッシュボードやログを見て異常が再現するか確認すること。
- 重要プロセスのCPU/メモリ使用率とハードウェア温度が通常値に戻ること。
1行用語集
- プロセス: 実行中のプログラム単位。
- スワップ: RAMが不足したときに使われるディスク領域。
- センサー: 温度や電圧を測定するハードウェア要素。
チートシート(よく使うコマンド)
sudo apt-get install gnome-system-monitor
sudo apt-get install htop
htop
sudo apt-get install lm-sensors
sudo sensors-detect
sensors
topまとめ
本稿ではUbuntuで手早く始められる3つの監視ツールを紹介しました。GUIで全体を掴み、ターミナルで詳細を追い、ハードウェアの問題はlm-sensorsで確認する。これらを組み合わせると日常のトラブル対応が早くなります。長期監視やアラートが必要ならPrometheusやNetdataへの移行を検討してください。



