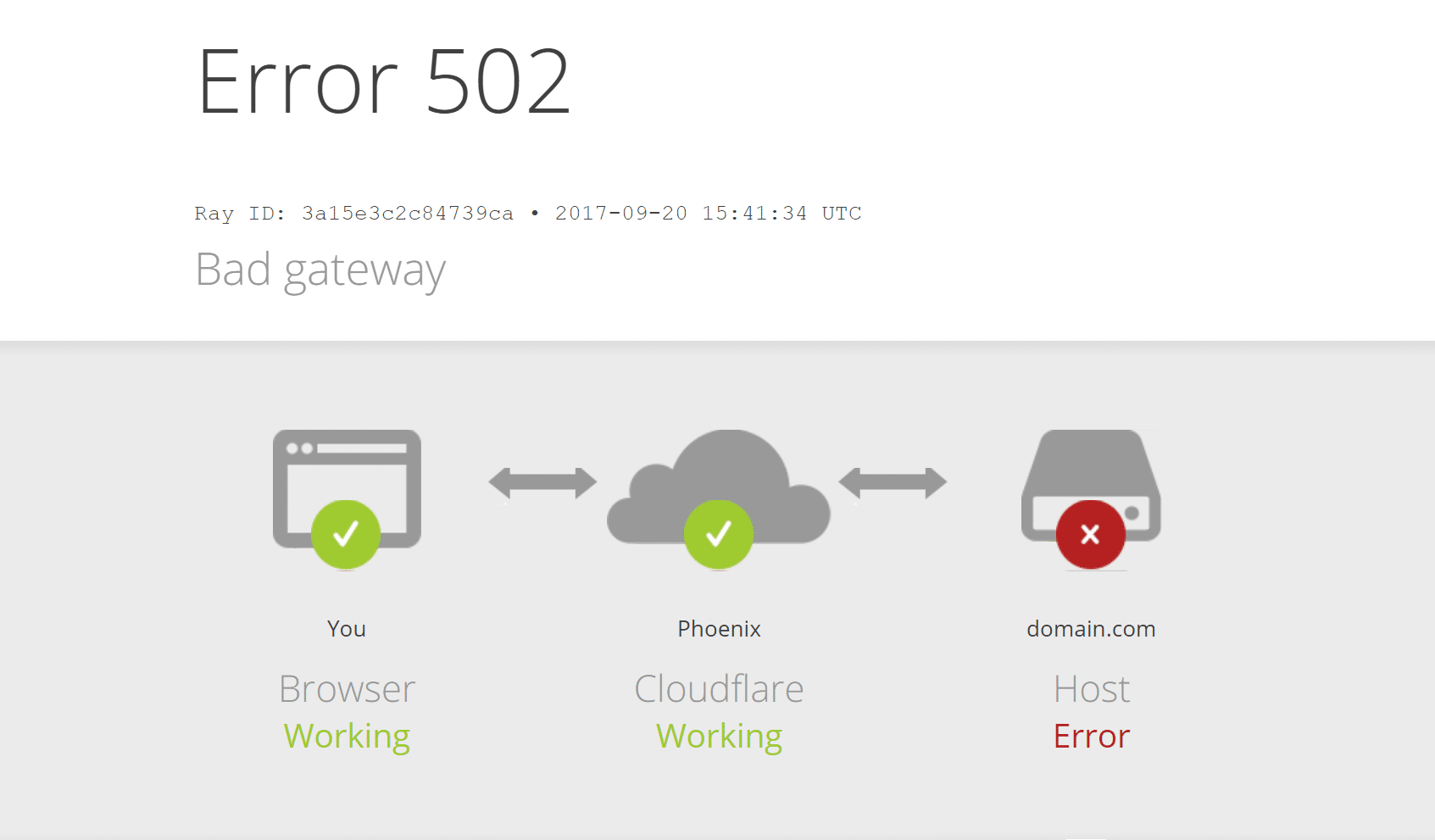
502 Bad Gatewayエラーとは — 原因と完全対処ガイド

数日前、私のお気に入りのサイトを開こうとしたところ、通常のトップページの代わりに “502 Bad Gateway” というメッセージが表示されました。最初は一時的な不具合かと思い、ページを更新したり、ブラウザを変えたり、Wi‑Fiを再起動したりしました。それでも同じエラーが返ってきました。502の意味は分からなかったものの、サイトにアクセスする必要があり焦りました。
他のサイトは問題なく読み込めていたので、ネットワーク全体の障害ではなさそうでした。調べるうちに、このエラーが非常に一般的で、どんなサイトでも起こり得ることが分かりました。本記事では、502 Bad Gatewayエラーの仕組み、ユーザーとしてできること、サイト管理者として行うべき詳細な対処法、予防策、及び現場で使えるチェックリストやランブックをまとめます。
502 Bad Gatewayエラーとは
502 Bad Gatewayは、HTTPステータスコードの一つで、基本的に「中継サーバー(ゲートウェイまたはプロキシ)が、他のサーバー(アップストリーム)から有効な応答を受け取れなかった」ことを示します。中継役はロードバランサー、リバースプロキシ(nginx, HAProxy, Apache mod_proxy など)、CDN、クラウドフロントなどが該当します。
定義(1行):中継サーバーが上流サーバーから期待する応答を受け取れないときに発生するHTTPエラーです。
重要点:クライアント(あなた)のブラウザが直接最終バックエンドと通信できていない場合でも、このエラーは発生します。つまり原因は必ずしもブラウザ側ではなく、サーバー側の通信経路や設定にあることが多いです。
主な原因
- アップストリームサーバーがダウンしている、応答が遅い、あるいは過負荷状態である。
- タイムアウト設定が短すぎる(プロキシやロードバランサのproxy_read_timeout等)。
- DNS解決の誤り(中継サーバーが誤ったIPに向けている)。
- CDNやプロキシの設定ミス(オリジン設定、ホストヘッダ不一致)。
- ファイアウォールやWAFによるブロック。
- アプリケーション層(PHP-FPM等)のクラッシュやスレッド枯渇。
- TLS/SSLハンドシェイクの失敗(証明書やプロトコル不整合)。
- ネットワークの断絶やルーティング障害。
次に、ユーザー向けの簡単な対処から、管理者向けの詳細トラブルシューティングまで順に説明します。
ユーザー向けの優先対処手順(簡潔)
- ページを再読み込みする(F5 またはブラウザの更新ボタン)。
- 別のブラウザで試す(Chrome / Firefox / Edge 等)。
- 別のデバイスや別ネットワークで開いてみる(スマホのモバイル回線など)。
- ブラウザのキャッシュとクッキーをクリアする。
- DNSキャッシュをフラッシュする(OSごとのコマンドを下に示します)。
- 5~10分待って再試行する(多くは一時的)。
- サイトがダウン検知サービス(DownDetector 等)で広く報告されているか確認する。
ブラウザキャッシュのクリア手順(共通)
- Chrome / Edge / Firefox の履歴メニューから「閲覧履歴データの削除」を選び、キャッシュされた画像とファイルをクリアします。
DNSキャッシュのフラッシュ(主要OS)
- Windows(コマンドプロンプトを管理者で起動)
ipconfig /flushdns- macOS(ターミナル)
sudo dscacheutil -flushcache; sudo killall -HUP mDNSResponder- Linux(systemd-resolved 利用時)
sudo systemd-resolve --flush-caches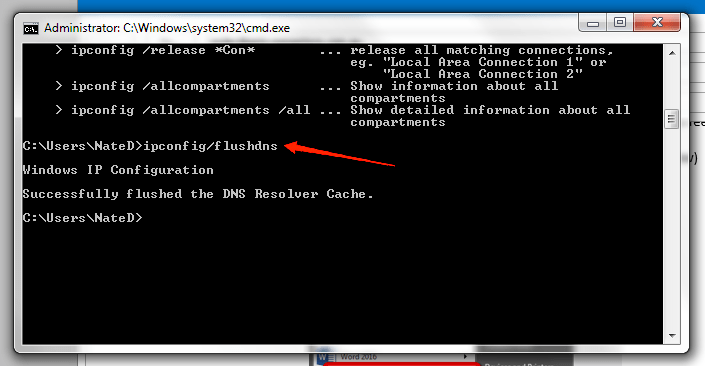
注意:VPNやプロキシ、会社/学校ネットワークの制限が原因で特定サイトがブロックされ、結果として502に見えるケースもあります。可能なら家庭の回線やモバイル回線で確認してください。
サイト管理者向けトラブルシューティング(詳細)
この節は運用担当者・DevOps・ウェブ開発者向けです。網羅的に確認項目を並べます。
1) 最初に行うべき確認
- サイト全体の障害か特定パスのみかを切り分ける(静的ファイルはOKで動的ルートだけNGか)。
- 監視(監視ツール、ALERT)の有無と直近のアラートを確認する。
- 他のユーザー/地域からのアクセス可否の確認(curlや外部のHTTPチェッカーで検証)。
コマンド例(外部からの応答確認):
curl -I https://example.com/ # HTTPヘッダのみ取得
curl -v https://example.com/ # 詳細(接続・TLS)を確認2) リバースプロキシ / ロードバランサのログを確認
- nginx の場合:
# エラーログの確認
tail -n 200 /var/log/nginx/error.log
# もしあればプロキシタイムアウトや接続拒否の痕跡を探す- HAProxy や AWS ELB / ALB を使っている場合は、それぞれのヘルスチェック結果とアクセスログを確認。
よくある兆候:
- Upstream timeout
- Connection refused
- No live upstreams
3) アップストリーム(バックエンド)を確認
- アプリケーションサーバー(例:PHP-FPM, Gunicorn, Unicorn, Node.js)のプロセス数やメモリ、CPU、スレッドの枯渇を確認。
- 直近のデプロイや設定変更が原因である可能性が高い場合はロールバックを検討。
コマンド例:
systemctl status php7.4-fpm
journalctl -u php7.4-fpm -n 200
ps aux --sort=-%mem | head -n 204) タイムアウトとバッファ設定を検証
- nginx のproxy_read_timeout / proxy_connect_timeout / proxy_send_timeout が短すぎると、長い処理で502が出ることがあります。
- proxy_buffer_size や proxy_buffers が不適切だと大きな応答を扱えずエラーになる場合があります。
nginxの設定例(参考):
proxy_connect_timeout 5s;
proxy_send_timeout 60s;
proxy_read_timeout 60s;
proxy_buffer_size 128k;
proxy_buffers 4 256k;5) CDNとDNSをチェック
- CDN(例:Cloudflare)を利用しているなら、オリジン(実サーバー)への接続状態をCDN管理コンソールで確認。
- CDNのオリジン設定でホストヘッダやポートが正しいか。
- DNSのA/AAAAレコードが期待通りのIPを指しているか。TTL短縮後のロールアウトやミスで一部ユーザーが誤ったIPへ飛ぶことがある。
DNS確認コマンド例:
dig +short A example.com
nslookup example.com6) ネットワークとファイアウォール
- サーバー間通信をブロックするファイアウォールルール(iptables, security groups, cloud ACL)を確認。
- WAFやレートリミットが正当なアップストリーム要求を拒否していないか精査。
7) TLS/SSLの問題
- オリジンとプロキシ間のTLS設定が合っていない(プロトコル/暗号スイート)とハンドシェイクで失敗する場合がある。
- 証明書の期限切れやチェーン不整合も要チェック。
8) アプリケーション層の例外とデプロイ
- アプリケーションの例外やメモリリークでワーカが落ちると、プロキシが接続先を見つけられなくなり502になります。
- 直近のリリースや設定変更を疑う場合は、一時的に旧バージョンに戻して様子を見るのが安全です。
9) ログの粒度を上げて再現試験
- 一時的にログレベルを上げ、失敗時のヘッダやステータス、応答時間を記録。
- 再現性があるなら、負荷試験で上流の耐久性を検証する。
nginx と Apache の典型的な502原因と対処例
- nginxが「upstream prematurely closed connection」や「no live upstreams」などを出す場合、バックエンドが落ちているか、ソケット数の上限に到達していることが多い。
- Apache + mod_proxy で「502 Proxy Error」が出たら、ProxyPass先が到達不能か応答ヘッダが壊れている可能性がある。
nginxでの応急設定例:
# upstream 指定とヘルスチェック(簡易)
upstream backend {
server 10.0.0.10:8080 max_fails=3 fail_timeout=30s;
server 10.0.0.11:8080 max_fails=3 fail_timeout=30s;
}
server {
location / {
proxy_pass http://backend;
proxy_connect_timeout 5s;
proxy_read_timeout 60s;
}
}注意:設定変更は段階的に適用し、監視を維持したまま行ってください。
予防策と運用上のベストプラクティス
- 健全なヘルスチェックを入れて、異常なバックエンドを自動的に切り離す。
- 適切なタイムアウト値とバッファサイズを設定する。
- オートスケーリングやキューイング(例:メッセージキュー)でスパイクを吸収する。
- CDNやロードバランサの設定変更はステージングで検証し、本番に段階的に反映する。
- ログとメトリクス(レスポンスタイム、エラー率、キュー長)を常時監視する。
役割別チェックリスト
エンドユーザー
- ページ更新、別ブラウザ、別ネットワーク、キャッシュ・DNSのクリア、待機。
ウェブ開発者
- 最近のデプロイ確認、アプリケーションログの例外確認、長時間処理の分離。
インフラ/DevOps
- プロキシ/ロードバランサログ、バックエンドのプロセス・リソース確認、ネットワークおよびDNS設定の検証。
サポート/ホスティング
- サーバーステータス、ハードウェア問題、ネットワーク障害、オペレータミスの履歴確認。
インシデント時の簡易ランブック
- 検知:監視で502エラー急増を検知。
- 切り分け:静的ファイルやヘルスチェックURLに応答があるか確認。
- ログ確認:プロキシとバックエンド両方の直近ログを確認。
- 一時対応:問題のあるバックエンドをプールから外す(Drain/Disable)。
- ロールバック:直近のデプロイが原因ならロールバック。
- 復旧:サービスが安定することを確認後、段階的に処理を戻す。
- 事後対応:ポストモーテムを書き、原因と改善策を記録。
失敗しやすい例と回避策
- ただ単にプロキシを再起動して問題を先送りするだけでは、根本原因(メモリリークや外部APIの遅延)を見逃すことがあります。
- CDNのオン/オフ切り替えでDNSが混乱し、部分的に障害が発生する例。事前にTTLを短くして段階展開してください。
コマンド/チェックのチートシート
- 接続確認: curl -I https://example.com/
- DNS確認: dig +short A example.com
- nginxログ: tail -n 200 /var/log/nginx/error.log
- プロセス確認: ps aux | grep java/python/node
- サービス再起動: sudo systemctl restart php7.4-fpm
よくある質問
502と504の違いは何ですか?
502は「無効な応答」を意味し、504は「ゲートウェイのタイムアウト(上流が応答しない)」を意味します。504は明確にタイムアウト、502はプロトコルや接続の失敗など幅広い原因を含みます。
一般ユーザーは何をすれば良いですか?
まずはページ再読み込み、別ブラウザ/別ネットワークでの確認、キャッシュとDNSのフラッシュを試してください。それでも直らなければ時間を置いて再試行するか、サイト運営に連絡してください。
CDNを無効化すれば直りますか?
場合によります。CDN設定が原因なら一時的にオフにすることで切り分けできますが、DNS伝播やキャッシュの問題で更に混乱する可能性もあります。運用環境では段階的な切り分けを推奨します。
決定ツリー(簡易)
flowchart TD
A[ユーザーが502を確認] --> B{他のサイトは動くか}
B -->|いいえ| C[ローカル接続の問題を疑う]
B -->|はい| D{デバイス/ネットワークを変えたか}
D -->|いいえ| E[別デバイス/別ネットワークで確認]
D -->|はい| F{管理者に報告済みか}
F -->|いいえ| G[運営に障害報告]
F -->|はい| H[運営の指示待ちまたは運営が対応中]用語集(1行ずつ)
- プロキシ:中継役としてHTTPリクエスト/レスポンスを中継するサーバー。
- アップストリーム:プロキシが接続しようとする元のサーバー(バックエンド)。
- CDN:コンテンツ配信ネットワーク。オリジンサーバーと訪問者の間に入る。
まとめ
- 502 Bad Gatewayは中継サーバーが上流から有効な応答を得られない時に発生する。
- ユーザー側はまず再読み込み、別ブラウザ・別ネットワーク、キャッシュとDNSのクリアを行う。
- サイト管理者はログ、アップストリームの健全性、タイムアウトやバッファ設定、CDN/DNS設定、ファイアウォールを重点的に確認する。
- インシデント発生時は切り分け→隔離→ロールバック→復旧→ポストモーテムの順で対応する。
もしこの記事や手順で不明点があれば、下のコメント欄で質問してください。以下は追加の参考画像です。
コメントや追加の状況(使用中のサーバーソフト、CDN名、最近のデプロイ有無)を教えていただければ、より具体的な診断手順を提示します。 Cheers!



