Man-in-the-Prompt: cómo detectar y defenderte

Qué es un ataque Man-in-the-Prompt
Un ataque Man-in-the-Prompt es una forma de inyección de prompts: un actor malicioso inserta instrucciones (visibles u ocultas) en la conversación entre tú y un LLM para manipular la respuesta. Imita la analogía del “man-in-the-middle” pero aplicada al contenido del prompt: el atacante altera lo que el modelo recibe o cómo responde.
Definición rápida: un LLM es un modelo de lenguaje grande que genera texto en función de la entrada (prompt). La inyección de prompt es cualquier técnica que introduce instrucciones no deseadas en esa entrada para cambiar la salida.
Importante: no siempre implica acceso directo al modelo; muchas veces basta con modificar el DOM de la página del chatbot (por ejemplo con una extensión) o alterar plantillas de prompts.
Por qué importa ahora
- En entornos empresariales los LLMs pueden acceder a información sensible (API keys, contratos, datos internos). Una inyección eficaz puede exfiltrar esa información o inducir a ejecutar acciones inseguras.
- Las extensiones de navegador, por su diseño, pueden leer y modificar el DOM de la página donde se escribe el prompt.
- Las soluciones personalizadas y las herramientas de “mejorar prompt” agregan complejidad y pueden convertirse en vectores de confianza rotas.
Vectores de ataque comunes
- Extensiones de navegador con permisos para leer/modificar páginas web.
- Herramientas de generación o edición de prompts (servicios online o bibliotecas) que insertan instrucciones ocultas.
- Scripts o bookmarklets compartidos internamente sin revisión.
- Integraciones de terceros en plataformas empresariales (bots, cuadros de texto embebidos).
Señales de que podrías estar bajo ataque
- El LLM responde con información no solicitada o secreta sin que la pidas.
- Respuestas que aparecen en bloques de código, tablas o secciones separadas que no provienen de tu prompt.
- Cambios inesperados en el comportamiento del chatbot después de instalar una extensión o usar una plantilla.
- Actividad de procesos de extensiones cuando la pestaña del chatbot está abierta.
Importante: una anomalía no prueba por sí sola un ataque, pero debería activar verificación manual inmediata.
Policing de extensiones del navegador
- Evita instalar extensiones innecesarias en los navegadores donde trabajas con LLMs.
- Instala sólo extensiones de editores reputados y revisa permisos.
- Usa el Administrador de tareas del navegador (Shift + Esc en Chrome) para detectar procesos activos de extensiones cuando escribes en la caja del chatbot.
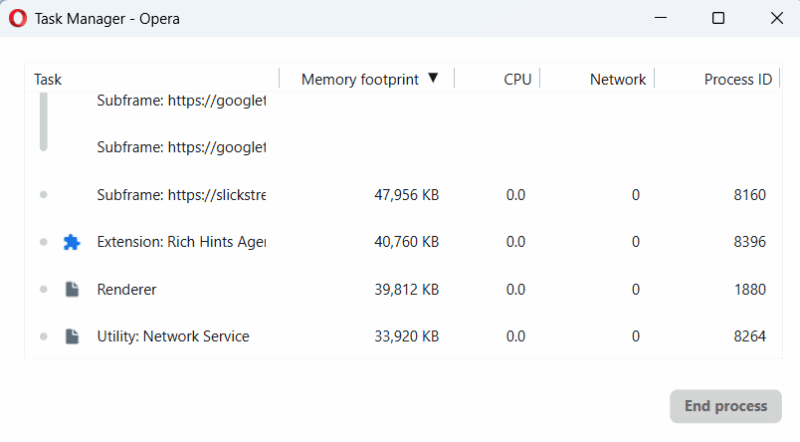
Si una extensión arranca procesos justamente cuando escribes en la caja del chatbot, es sospechosa. Desactívala y prueba de nuevo.
Buenas prácticas al redactar y enviar prompts
- Escribe prompts manualmente cuando la información es sensible.
- Si copias y pegas desde otra fuente, pega primero en un editor de texto plano (Notepad, TextEdit en modo texto plano), revisa y luego copia al chatbot.
- Elimina caracteres invisibles y líneas en blanco antes de enviar: usa retroceso/backspace, no sólo suprimir selección.
- Prefiere plantillas que controles y guardes localmente. No dependas de plantillas de terceros sin revisión.
Sesiones y aislamiento
- Cambia a una nueva conversación cuando cambie el tema, especialmente si compartiste secretos en la sesión anterior.
- Para tareas críticas, usa una sesión dedicada y evita reusar contexto de otras sesiones.
Inspecciona las respuestas del modelo
- No aceptes automáticamente respuestas que incluyan información sensible o instrucciones para realizar acciones externas.
- Si la respuesta contiene información secreta sin que la pidieras: cierra la sesión y empieza una nueva.
- Si la salida adopta un formato inusual (bloque de código, tabla anidada, secciones ocultas), asume riesgo y revisa cuidadosamente.
Estrategias técnicas para mitigar riesgos
- Deshabilita extensiones en sesiones críticas o usa un perfil de navegador sin extensiones para trabajo con LLMs.
- Usa navegadores que muestren claramente qué extensiones tienen permisos sobre qué sitios.
- En entornos empresariales, aplique políticas de whitelisting de extensiones y revisión periódica.
- Adopta modelos privados o gateways con control de entrada donde el prompt pasa por un validador antes de enviarse al LLM.
Validación y saneamiento de prompts (mini-metodología)
- Inventario: lista de fuentes que generan o modifican prompts (plugins, plantillas, scripts).
- Clasificación: asigna sensibilidad (baja/media/alta) a cada uso del LLM.
- Saneamiento: para usos sensibles, bloquea HTML/JS, elimina metadatos y caracteres invisibles.
- Prueba: simula inyecciones para ver si las defensas detectan cambios.
- Monitorización: registra y alerta sobre modificaciones en el DOM o en la cadena de entrada.
Heurísticas mentales útiles
- “Trust-but-verify” (Confía pero verifica): revisa prompts y salidas antes de aceptar.
- Principio de menor privilegio: usa cuentas/entornos con acceso limitado cuando trabajes con LLMs.
- Sesión única para tareas sensibles: separa contextos y no reutilices sesiones que alojaron secretos.
Checklist por rol
Usuario final
- Evitar extensiones no revisadas.
- Escribir prompts manualmente para consultas sensibles.
- Pegar texto a través de un editor de texto plano si procede.
- Cambiar a nueva conversación ante la menor anomalía.
Administrador TI
- Aplicar políticas de whitelisting/blacklisting de extensiones.
- Forzar perfiles corporativos sin extensiones en estaciones que usan LLMs.
- Monitorizar procesos y actividad del navegador.
- Implementar gateways de validación de prompts.
Equipo de seguridad
- Simular ataques de inyección de prompts como parte del pentesting.
- Establecer playbooks de respuesta y retención de logs.
- Revisar integraciones de terceros que tocan cuadros de texto.
Desarrolladores/DevOps
- Saneamiento de entradas del usuario antes de reenviar a un LLM.
- Trazabilidad de prompts: registrar hashes/firmas para detectar modificaciones.
- Implementar límites de contexto y filtros de salida en la capa de aplicación.
Playbook de incidente: detección de Man-in-the-Prompt
Paso a paso para un incidente sospechoso:
- Contención inmediata: cierra la sesión y bloquea el perfil/navegador afectado.
- Recolecta evidencia: captura pantalla, exporta la conversación, anota extensiones instaladas y procesos activos.
- Aislamiento: fuerza cambio de credenciales si se sospecha exfiltración de secretos.
- Análisis: reproduce el comportamiento en un entorno controlado; prueba con y sin extensiones.
- Erradicación: desinstala o bloquea la extensión o herramienta responsable; revoca claves si fue posible su exposición.
- Recuperación: restaura perfiles limpios, reevalúa permisos y reabre el servicio.
- Postmortem: actualizar políticas, comunicar lecciones a usuarios y añadir controles técnicos.
Criterios de detección (qué validar antes de declarar incidente)
- Existencia de instrucciones no solicitadas en la conversación.
- Correlación temporal con instalación o actividad de una extensión.
- Pruebas reproducibles en un entorno controlado.
Escenarios donde las defensas fallan o son insuficientes
- Extensiones maliciosas firmadas o publicadas por actores que aparentan ser legítimos.
- Integraciones servidor-side que inyectan prompts en nombre del cliente sin revisión.
- Usuarios que autorizan extensiones corporativas sin entender permisos.
Alternativas cuando las defensas estándar no bastan
- Usar un gateway corporativo que firme y valide prompts antes de enviarlos al LLM.
- Implementar un proxy que destruya cualquier HTML/JS y normalice texto plano.
- Requerir confirmación humana adicional para cualquier respuesta que incluya datos sensibles.
Seguridad y endurecimiento para equipos y arquitecturas
- Registro (logging): guardar metadatos de cada prompt (usuario, timestamp, hash) para detectar manipulación.
- Filtrado saliente: bloquear respuestas que incluyan patrones de secretos (API keys, tokens) mediante DLP.
- Contención de contexto: limitar memoria del modelo por sesión y evitar acumulación indefinida de contexto.
- Aislamiento de entornos: usar perfiles de navegador sin extensiones y estaciones dedicadas para LLMs sensibles.
Notas de privacidad y cumplimiento
- Si el LLM maneja datos personales, revisa obligaciones bajo la normativa aplicable (p. ej., GDPR).
- Minimiza datos personales en prompts y evita enviar identificadores directos cuando no son necesarios.
- Registra acceso y retención de conversaciones para poder auditar en caso de fuga.
Pequeña guía de pruebas (test cases)
- Inyección visible: editar el prompt con texto claramente malicioso y verificar que el sistema la bloquea.
- Inyección oculta: añadir caracteres invisibles o HTML y comprobar saneamiento.
- Extensión intermitente: simular extensión que activa modificaciones solo cuando detecta campo de texto.
Glosario de 1 línea
- LLM: modelo de lenguaje grande que genera texto a partir de prompts.
- Inyección de prompt: inserción de instrucciones maliciosas en la entrada del modelo.
- DOM: estructura de objetos que compone una página web; las extensiones pueden leer/modificarlo.
- Whitelisting: permitir sólo un conjunto aprobado de extensiones o aplicaciones.
Hecho clave
- El riesgo principal no es solo que el modelo “equivoca” una respuesta: es que un actor externo pueda instruirlo para revelar o manipular información que no debía.
Flujo de decisión rápido
flowchart TD
A[Detectas una respuesta inesperada] --> B{¿Contiene datos sensibles o instrucciones externas?}
B -- Sí --> C[Detener sesión y recopilar evidencia]
B -- No --> D[Inspeccionar formato y origen del prompt]
D --> E{¿Hubo extensión o fuente externa?}
E -- Sí --> C
E -- No --> F[Marcar para monitoreo y revisar plantillas]
C --> G[Aplicar playbook de incidente]
F --> H[Mejorar controles y educar usuarios]Resumen y próximos pasos
- Revisa y reduce extensiones del navegador; evita extensiones en sesiones críticas.
- Valida y sanea todos los prompts para usos sensibles.
- Implementa controles técnicos (whitelisting, gateways, DLP) y procedimientos humanos (playbook, checklists).
- Practica simulaciones de ataque y mantén un plan de respuesta claro.
Notas finales
La amenaza Man-in-the-Prompt explota la confianza que depositamos en los interfaces de LLM. La defensa requiere una combinación de higiene del usuario, controles técnicos y procesos organizativos. Adoptar una postura de “confía pero verifica” y segregar contextos de conversación reduce considerablemente la superficie de ataque.
Notas importantes
- Si sospechas exposición de claves o datos sensibles: revoca y rota credenciales inmediatamente.
- Educa a los usuarios clave con ejercicios prácticos: la mayor parte de estas intrusiones se evita con hábitos correctos.
Materiales similares

Podman en Debian 11: instalación y uso
Apt-pinning en Debian: guía práctica

OptiScaler: inyectar FSR 4 en casi cualquier juego
Dansguardian + Squid NTLM en Debian Etch

Arreglar error de instalación Android en SD
