Pandas y DataFrame en Python: Guía esencial


Tabla de contenidos
- ¿Qué es pandas?
- ¿Qué es un DataFrame?
- Cómo crear un DataFrame
- Importar datos a un DataFrame
- Examinar un DataFrame
- Añadir y eliminar columnas
- Operaciones y selección de columnas
- Visualización básica con pandas
- Buenas prácticas y rendimiento
- Modelos mentales y enfoques alternativos
- Mini-metodología: del CSV al informe reproducible
- Chequeos por rol (Analista / Científico de datos / Ingeniero)
- Hoja de referencia rápida (cheat sheet)
- Glosario de una línea
¿Qué es pandas?

pandas es una biblioteca de Python ampliamente utilizada en ciencia de datos y análisis. Proporciona estructuras de datos, sobre todo la Series (unidimensional) y el DataFrame (bidimensional), y múltiples operaciones para limpiar, transformar y analizar datos tabulares. Se integra bien con NumPy, Matplotlib, Seaborn y otras librerías del ecosistema.
Definición rápida: DataFrame es una tabla etiquetada con filas y columnas; piensa en él como una hoja de cálculo o una tabla SQL en memoria.
Instalación (si no lo tienes):
pip install pandasRecomendación: trabaja con Jupyter Notebook o JupyterLab para exploraciones interactivas y registros reproducibles de los pasos de análisis.
¿Qué es un DataFrame?
Un DataFrame organiza datos en filas (observaciones) y columnas (variables). Cada columna tiene un nombre y un tipo de dato (numérico, texto, fecha, booleano). Puedes tratar columnas individualmente, combinarlas, filtrar filas y aplicar funciones vectorizadas a escala.
Concepto clave: las operaciones en pandas están optimizadas para trabajar con columnas completas (operaciones vectorizadas), no con bucles por fila.
Cómo crear un DataFrame
Puedes crear DataFrames a partir de listas, diccionarios, arrays de NumPy o estructuras externas (CSV, Excel, bases de datos). Ejemplo mínimo usando NumPy:
import numpy as np
import pandas as pd
x = np.linspace(-10, 10)
y = 2 * x + 5
df = pd.DataFrame({'x': x, 'y': y})Explicación: np.linspace genera valores del eje x; definimos y como una función lineal. Luego creamos el DataFrame con un diccionario que mapea nombres de columnas a arrays.
Consejo: usa nombres de columnas descriptivos y consistentes (snake_case o camelCase, según tu estilo de proyecto).
Importar datos a un DataFrame
El caso más común es leer datos desde archivos. pandas soporta CSV, Excel, JSON, HTML, SQL y más.
Leer CSV:
df = pd.read_csv('/path/to/data.csv')Leer Excel (hoja por nombre o índice):
df = pd.read_excel('/path/to/spreadsheet.xlsx', sheet_name='Hoja1')Copiar desde el portapapeles (útil para datasets pequeños o rápidos):
df = pd.read_clipboard()Conexiones a bases de datos: utiliza pandas.read_sql_query junto con SQLAlchemy o drivers adecuados.
Nota: siempre revisa encoding y separador (encoding=’utf-8’, sep=’;’) cuando trabajes con archivos de origen diverso.
Examinar un DataFrame
Al crear o importar datos, lo primero es inspeccionarlos.
Primeras filas y últimas filas:
df.head() # primeras 5 filas por defecto
df.head(10) # primeras 10 filas
df.tail() # últimas 5 filas
df.tail(10) # últimas 10 filas
Columnas y tipos:
df.columns # nombres de columnas
df.dtypes # tipo de dato por columnaResumen estadístico (solo numéricos por defecto):
df.describe()
Acceder a una columna:
nombres = df['Name'] # Serie con la columna Name
edad = df['Age']Para evitar truncado al imprimir muchas filas o columnas:
pd.set_option('display.max_rows', None) # mostrar todas las filas
pd.set_option('display.max_columns', None) # mostrar todas las columnasEstadísticas de una columna concreta:
df['Age'].describe()
mean_age = df['Age'].mean()
median_age = df['Age'].median()Añadir y eliminar columnas
Crear columnas nuevas aplicando operaciones vectorizadas:
# elevar al cuadrado la columna x
df['x2'] = df['x'] ** 2
# combinación de columnas
df['x_plus_y'] = df['x'] + df['y']Eliminar columnas (devuelve una copia si no usas inplace):
df = df.drop('x2', axis=1) # axis=1 para columnas
# o
df.drop(columns=['x2', 'x_plus_y'], inplace=True)Importante: evitar asignaciones innecesarias que duplican grandes DataFrames si la memoria es limitada.
Operaciones y selección de columnas
Seleccionar varias columnas:
df[['Name', 'Age']]Filtrado booleano (similar a WHERE en SQL):
mayores_30 = df[df['Age'] > 30]Equivalente conceptual en SQL:
SELECT * FROM df WHERE Age > 30;Uso de .loc y .iloc para selección por etiquetas o por posición:
# por etiquetas (filas y columnas)
df.loc[df['Age'] > 30, ['Name', 'Age']]
# por posición (índices enteros)
df.iloc[0:5, 0:3] # primeras 5 filas, primeras 3 columnasOperaciones más avanzadas: groupby, pivot_table, merge, join y concat. Ejemplo rápido de groupby:
embarked_counts = df.groupby('Embarked').size()Visualización básica con pandas
pandas integra gráficos simples usando Matplotlib como backend.
Contar valores y graficar barras:
embarked = df['Embarked'].value_counts()
embarked = embarked.rename({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'})
embarked.plot(kind='bar')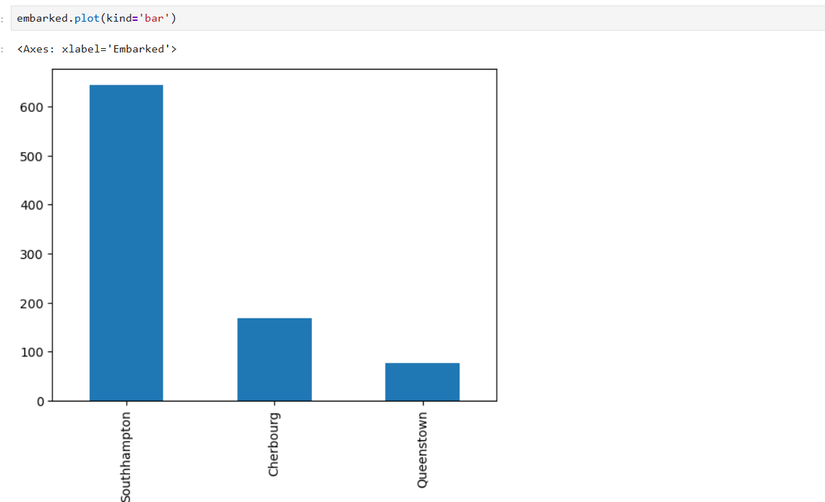
Para visualizaciones más elaboradas, usa Seaborn o Altair, alimentando los DataFrames de pandas.
Buenas prácticas y rendimiento
- Evita bucles explícitos sobre filas; usa operaciones vectorizadas.
- Convierte columnas a tipos eficientes (por ejemplo, category para valores repetidos como códigos de país).
- Usar chunking para archivos muy grandes: pd.read_csv(…, chunksize=100000) y procesar por partes.
- Para joins masivos, asegúrate de tener índices adecuados y considera usar dask o bases de datos si el dataset no cabe en memoria.
- Guarda artefactos intermedios en formatos binarios rápidos como Parquet (parquet es columnar y eficiente):
df.to_parquet('data.parquet')
df = pd.read_parquet('data.parquet')Nota: Parquet preserva tipos y es más rápido que CSV para lecturas repetidas.
Modelos mentales y heurísticos (mental models)
- DataFrame = hoja de cálculo en memoria: filas = registros, columnas = variables.
- Operaciones vectorizadas = pensar en columnas como vectores matemáticos.
- Transformación por pasos: input → limpieza → transformación → análisis → visualización → exportación.
- Evita mutaciones innecesarias: preferir asignaciones claras y etapas con nombres descriptivos (df_raw → df_clean → df_features → df_model).
En qué casos pandas no es la mejor opción (contraejemplos)
- Datasets que no caben en memoria RAM: considera Dask, Vaex o una base de datos.
- Workloads de streaming en tiempo real: usar sistemas diseñados para streaming (Kafka + stream processing).
- Operaciones muy complejas en grafos o estructuras no tabulares: usar librerías específicas (NetworkX, Neo4j).
Enfoques alternativos
- Dask DataFrame: mismo API similar a pandas, escala a múltiples núcleos/nodos.
- Polars: biblioteca en Rust con API inspirada en pandas pero con mejor rendimiento en operaciones out-of-core.
- SQL directo en motores analíticos (DuckDB, SQLite) para consultas puntuales y exploración rápida con SQL.
Decisión práctica: si tu flujo es interactivo y los datos caben en memoria, pandas suele ser la opción más productiva. Si escalas, evalúa Dask o Polars.
Mini-metodología: del CSV al informe reproducible
- Importar metadatos (columnas, tipos esperados).
- Cargar con parámetros explícitos (dtype, parse_dates, na_values).
- Inspeccionar (head, dtypes, describe, missing values).
- Limpiar (normalizar nombres, tratar nulos, convertir tipos).
- Enriquecer (crear features relevantes, parseo de fechas).
- Guardar versión intermedia (parquet) para reproducibilidad.
- Visualizar y documentar las decisiones en Jupyter Notebook.
Ejemplo de carga segura:
dtypes = {'PassengerId': 'int64', 'Survived': 'int8', 'Pclass': 'int8', 'Name': 'string'}
parse_dates = ['DateColumnIfAny']
titanic = pd.read_csv('data/Titanic-Dataset.csv', dtype=dtypes, parse_dates=parse_dates, na_values=['', 'NA'])Chequeos por rol: listas de verificación rápidas
Analista:
- ¿Entendí las columnas clave y su tipo?
- ¿He visto head() y describe()?
- ¿Hay valores faltantes relevantes?
- ¿Guardé una copia limpia del dataset?
Científico de datos:
- ¿Las columnas están en el tipo correcto para modelado?
- ¿Existe leakage (fuga) en las features?
- ¿Dividí train/validation/test de forma reproducible?
- ¿Documenté las transformaciones en el notebook?
Ingeniero de datos:
- ¿Este pipeline escala con tamaños mayores de datos?
- ¿Hay checkpoints (Parquet, tablas intermedias)?
- ¿Automatizo la ingestión y validación de esquemas?
- ¿Monitorizo la latencia/memoria del proceso?
Hoja de referencia rápida (cheat sheet)
Selección y filtrado:
# seleccionar columna
s = df['col']
# varias columnas
df[['colA', 'colB']]
# filtrar
df[df['col'] > 0]
# loc e iloc
df.loc[mask, ['colA', 'colB']]
df.iloc[0:5, 0:3]Agrupación y agregación:
df.groupby('category').agg({'value': ['mean', 'sum', 'count']})Merge/Join:
merged = df1.merge(df2, on='key', how='left')Pivot table básica:
pd.pivot_table(df, index='colA', columns='colB', values='value', aggfunc='sum')Manejo de nulos:
# eliminar filas con nulos
df.dropna()
# rellenar nulos
df['col'] = df['col'].fillna(df['col'].median())Exportar:
df.to_csv('out.csv', index=False)
df.to_parquet('out.parquet')Pruebas y criterios de aceptación básicos (test cases)
- Lectura: el archivo se carga sin errores y las columnas esperadas están presentes.
- Tipos: columnas numéricas no deben interpretarse como strings.
- Valores nulos: contar y documentar las columnas con más del X% de nulos (decisión del equipo).
- Agregaciones: los totales por grupo coinciden con la suma esperada.
Seguridad, privacidad y consideraciones legales
- Evita compartir columnas con datos personales (PII) sin anonimizar o sin base legal.
- Para datos de la UE, aplica principios de minimización y considera retención y acceso conforme a GDPR.
- Almacenar versiones en Parquet o en sistemas con control de acceso para limitar exposición.
Plantilla rápida de notebook reproducible
- Encabezado con objetivo y descripción del dataset.
- Carga de librerías y configuración (pd.options, paths).
- Carga de datos con parámetros explícitos.
- Inspección y limpieza (con celdas separadas y comentarios).
- Generación de features y validación.
- Guardado de artefactos.
- Visualizaciones y conclusiones.
Glosario de una línea
- DataFrame: estructura tabular etiquetada (filas y columnas).
- Series: columna individual de un DataFrame.
- Vectorizado: operación aplicada a toda la columna sin bucles explícitos.
- Chunking: procesar datos por partes cuando no caben en memoria.
Importante: pandas es extremadamente productivo para exploración y análisis interactivo, pero requiere disciplina en la gestión de memoria y tipos cuando se usa en producción.
Resumen final:
- pandas facilita manipular datos tabulares con una API expresiva.
- Familiarízate con head(), describe(), loc/iloc, groupby y merge.
- Usa formatos binarios como Parquet y considera alternativas (Dask, Polars) para escalar.
Materiales similares

Podman en Debian 11: instalación y uso
Apt-pinning en Debian: guía práctica

OptiScaler: inyectar FSR 4 en casi cualquier juego
Dansguardian + Squid NTLM en Debian Etch

Arreglar error de instalación Android en SD
