Elastic Stack en CentOS 8: instalación y configuración
Instale Elasticsearch, Logstash y Kibana en un servidor CentOS 8, configure Nginx como proxy inverso con autenticación básica y despliegue Filebeat en clientes CentOS y Ubuntu para enviar logs a Logstash. Esta guía paso a paso incluye configuración recomendada de JVM, módulos Filebeat, filtros Grok básicos y comprobaciones para verificar que los servicios están activos.
Importante: antes de comenzar, confirme que dispone de las máquinas con la memoria indicada y acceso root o sudo en cada nodo.
Objetivo principal y variantes de búsqueda relacionadas
Este artículo explica cómo instalar y configurar Elastic Stack (Elasticsearch, Logstash, Kibana) en CentOS 8 y cómo desplegar Filebeat en clientes. Variantes relacionadas: instalar ELK en CentOS, configurar Filebeat a Logstash, Nginx como proxy para Kibana, ajustes de JVM para Elasticsearch, filtrar syslog con Grok.
Requisitos previos
- Un servidor CentOS 8 de 64 bits con 4 GB RAM — elk-master (nodo central).
- Un servidor CentOS 8 de 64 bits con 1 GB RAM — client01 (cliente Filebeat).
- Un servidor Ubuntu 18.04 de 64 bits con 1 GB RAM — client02 (cliente Filebeat).
- Conexión de red entre clientes y servidor ELK (puerto 5044 TCP abierto hacia Logstash).
- Acceso con privilegios para instalar paquetes y editar archivos de configuración.
Nota: los requisitos de memoria son mínimos para entornos de prueba. Para producción, asignar más RAM al nodo maestro y al heap JVM según el tamaño de los índices y volúmenes de logs.
Índice
- Introducción breve a cada componente
- Paso 1: Añadir repositorio de Elastic
- Paso 2: Instalar y configurar Elasticsearch
- Paso 3: Instalar y configurar Kibana
- Paso 4: Configurar Nginx como proxy inverso para Kibana
- Paso 5: Instalar y configurar Logstash
- Paso 6: Instalar Filebeat en clientes (CentOS y Ubuntu)
- Paso 7: Pruebas y verificación
- Cómo solucionar problemas comunes
- Checklist por rol y playbook de despliegue
- Diagrama de decisión para elegir arquitectura
- Glosario 1 línea
- Resumen y recomendaciones finales
Breve introducción a los componentes
- Elasticsearch: motor de búsqueda y almacenamiento basado en Lucene, accedido por JSON via HTTP. Define índices para documentos y expone puerto 9200.
- Logstash: colector y transformador de eventos. Recibe datos (por ejemplo, Filebeat), aplica filtros (grok, date) y envía a destinos (por ejemplo Elasticsearch).
- Kibana: interfaz web para visualizar datos de Elasticsearch. Normalmente sirve en el puerto 5601 y se protege mediante proxy en entornos de producción.
- Filebeat: agente ligero que lee archivos de log y los envía a Logstash o directamente a Elasticsearch.
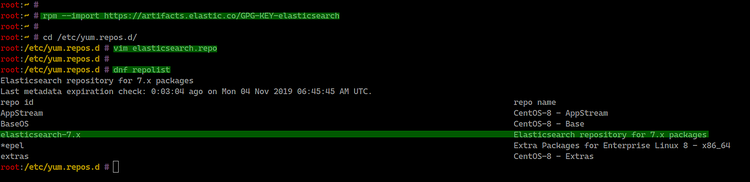
Paso 1 - Añadir el repositorio de Elastic
Primero añadiremos la clave GPG y el repositorio oficial de Elastic al servidor CentOS 8. Esto permite instalar Elasticsearch, Logstash, Kibana y Beats.
Importe la clave GPG:
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearchCree el archivo de repositorio en /etc/yum.repos.d/elasticsearch.repo:
cd /etc/yum.repos.d/
vim elasticsearch.repoPegue lo siguiente en el archivo:
[elasticsearch-7.x]
name=Elasticsearch repository for 7.x packages
baseurl=https://artifacts.elastic.co/packages/7.x/yum
gpgcheck=1
gpgkey=https://artifacts.elastic.co/GPG-KEY-elasticsearch
enabled=1
autorefresh=1
type=rpm-mdGuarde y cierre el editor.
Compruebe los repositorios disponibles:
dnf repolistDebería ver el repositorio de elastic añadido.
Este repositorio permitirá instalar los paquetes oficiales de Elastic.
Paso 2 - Instalar y configurar Elasticsearch
Instale el paquete de Elasticsearch:
sudo dnf install elasticsearch -yEdite el archivo de configuración principal:
cd /etc/elasticsearch/
vim elasticsearch.ymlDescomente y ajuste al menos las siguientes opciones para un entorno de pruebas local:
network.host: 127.0.0.1
http.port: 9200Guard y cierre.
Opcional: ajustar el heap JVM según la RAM disponible. Abra jvm.options:
vim jvm.optionsAjuste min y max heap (Xms y Xmx). Para nodos con 4 GB, un valor inicial razonable es 1–2 GB. En este tutorial usamos 512 MB por simplicidad en entornos de laboratorio:
-Xms512m
-Xmx512mAdvertencia: en producción, asigne aproximadamente la mitad de la RAM al heap JVM, pero nunca más de ~31 GB para usar pointers comprimidos.
Recargue systemd y habilite el servicio para arranque automático:
sudo systemctl daemon-reload
sudo systemctl enable elasticsearch
sudo systemctl start elasticsearch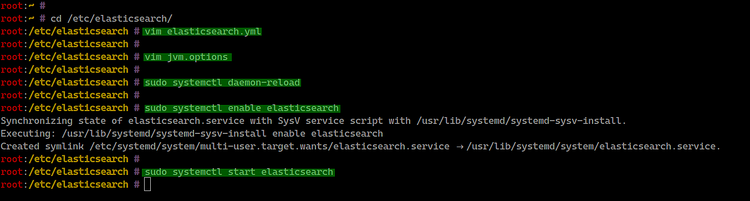
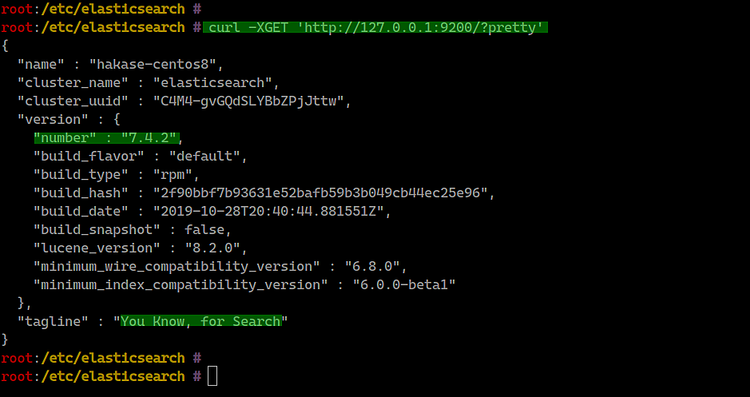
Compruebe que Elasticsearch responde:
curl -XGET 'http://127.0.0.1:9200/?pretty'Debería recibir un JSON con información del clúster.
Consejo: use journalctl -u elasticsearch -f para ver logs y depurar problemas de inicio.
Paso 3 - Instalar y configurar Kibana
Instale Kibana en el servidor CentOS 8:
sudo dnf install kibanaEdite la configuración:
cd /etc/kibana/
vim kibana.ymlAjuste estas líneas para que Kibana se comunique con Elasticsearch local:
server.port: 5601
server.host: "127.0.0.1"
elasticsearch.url: "http://127.0.0.1:9200"Habilite y arranque el servicio:
sudo systemctl enable kibana
sudo systemctl start kibana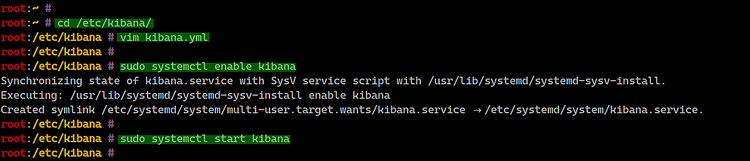
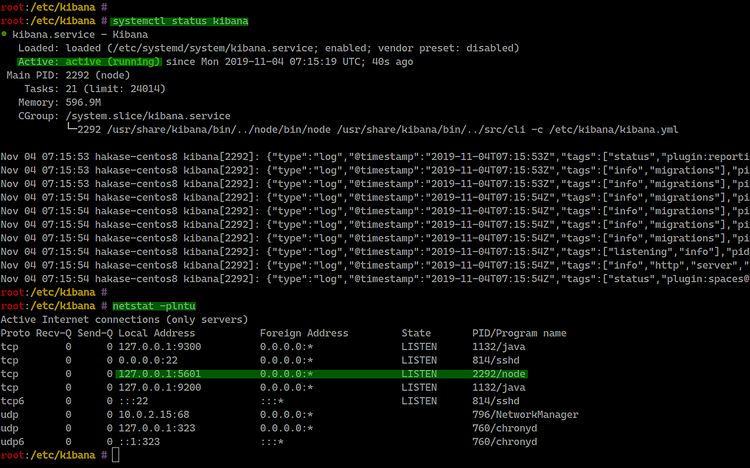
Compruebe estado y puertos:
systemctl status kibana
netstat -plntuKibana escuchará por defecto en el puerto TCP 5601 en la dirección configurada.
Paso 4 - Configurar Nginx como proxy inverso para Kibana
En producción es recomendable proteger Kibana con autenticación y usar un proxy inverso que gestione TLS, cabeceras y límites. Instalaremos Nginx y htpasswd para autenticación básica.
Instale Nginx y herramientas HTTP:
sudo dnf install nginx httpd-toolsCree el archivo de configuración de Nginx:
cd /etc/nginx/conf.d/
vim kibana.confPegue la siguiente configuración y ajuste server_name según su dominio:
server {
listen 80;
server_name elk.hakase-labs.io;
auth_basic "Restricted Access";
auth_basic_user_file /etc/nginx/.kibana-user;
location / {
proxy_pass http://127.0.0.1:5601;
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection 'upgrade';
proxy_set_header Host $host;
proxy_cache_bypass $http_upgrade;
}
}Guarde y cierre.
Cree el archivo de usuarios y contraseña (reemplace hakase por su usuario):
sudo htpasswd -c /etc/nginx/.kibana-user hakaseIntroduzca la contraseña cuando se le solicite.
Pruebe la configuración de Nginx y arranque el servicio:
nginx -t
systemctl enable nginx
systemctl start nginx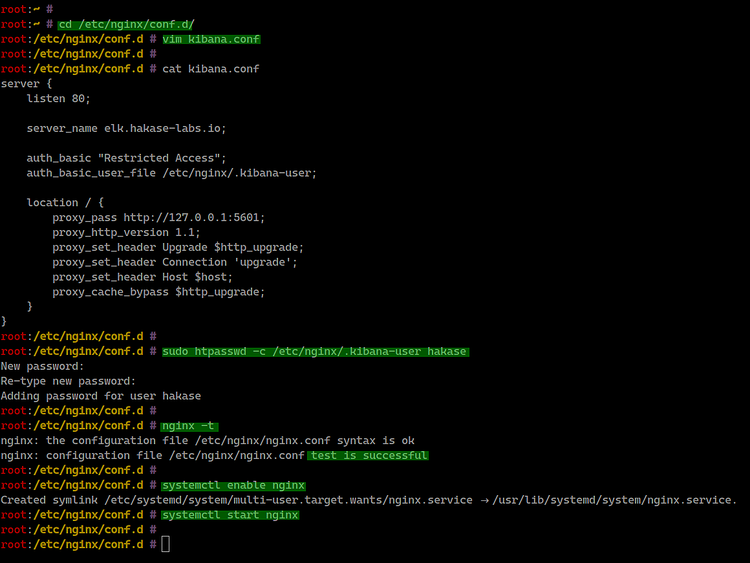
Consejo: para producción, habilite TLS (port 443) con certbot o su CA interna, y limite el acceso por IP si es posible.
Paso 5 - Instalar y configurar Logstash
Instale Logstash:
sudo dnf install logstashAjuste la JVM:
cd /etc/logstash/
vim jvm.optionsModifique Xms/Xmx a valores apropiados:
-Xms512m
-Xmx512mCree la configuración de entrada para recibir beats en /etc/logstash/conf.d/input-beat.conf:
cd /etc/logstash/conf.d/
vim input-beat.confContenido:
input {
beats {
port => 5044
}
}Cree un filtro para syslog usando grok en /etc/logstash/conf.d/syslog-filter.conf:
vim syslog-filter.confContenido:
filter {
if [type] == "syslog" {
grok {
match => { "message" => "%{SYSLOGTIMESTAMP:syslog_timestamp} %{SYSLOGHOST:syslog_hostname} %{DATA:syslog_program}(?:\[%{POSINT:syslog_pid}\])?: %{GREEDYDATA:syslog_message}" }
add_field => [ "received_at", "%{@timestamp}" ]
add_field => [ "received_from", "%{host}" ]
}
date {
match => [ "syslog_timestamp", "MMM d HH:mm:ss", "MMM dd HH:mm:ss" ]
}
}
}Notas: la expresión Grok anterior es un punto de partida para syslog clásico; puede necesitar adaptaciones para formatos específicos (journald, rsyslog con etiquetas distintas, etc.).
Cree la salida hacia Elasticsearch en /etc/logstash/conf.d/output-elasticsearch.conf:
vim output-elasticsearch.confContenido:
output {
elasticsearch { hosts => ["127.0.0.1:9200"]
hosts => "127.0.0.1:9200"
manage_template => false
index => "%{[@metadata][beat]}-%{+YYYY.MM.dd}"
document_type => "%{[@metadata][type]}"
}
}Guarde y cierre los archivos.
Habilite y arranque Logstash:
systemctl enable logstash
systemctl start logstash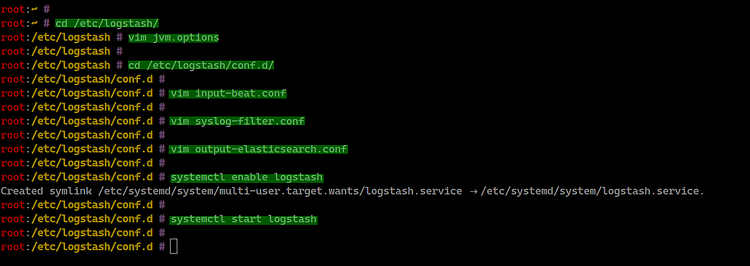
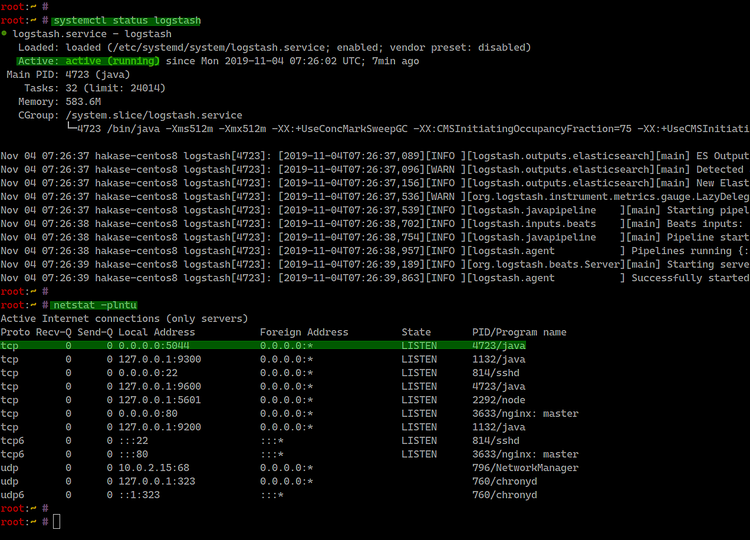
Verifique estado y puertos:
systemctl status logstash
netstat -plntuLogstash escuchará en el puerto 5044 por defecto para Beats.
Paso 6 - Instalar Filebeat en clientes
Filebeat leerá archivos de log locales y enviará los eventos a Logstash en el servidor ELK.
Instalar Filebeat en CentOS 8
Importe la clave GPG y cree el repositorio (si aún no se hizo en el cliente):
rpm --import https://artifacts.elastic.co/GPG-KEY-elasticsearch
cd /etc/yum.repos.d/
vim elasticsearch.repoPegue el contenido del repositorio como en el Paso 1.
Instale Filebeat:
sudo dnf install filebeat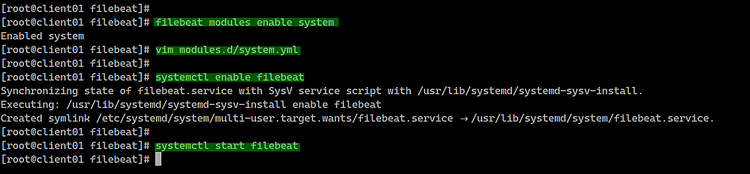
Instalar Filebeat en Ubuntu 18.04
Instale apt-transport-https:
sudo apt install apt-transport-httpsAñada la clave y el repositorio:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo apt-key add -
echo "deb https://artifacts.elastic.co/packages/7.x/apt stable main" | sudo tee -a /etc/apt/sources.list.d/elastic-7.x.listActualice paquetes e instale Filebeat:
sudo apt update
sudo apt install filebeat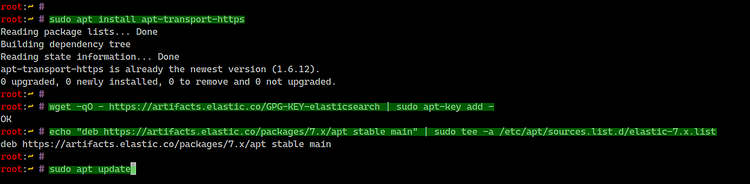
Configurar Filebeat para enviar a Logstash
Edite el archivo principal:
cd /etc/filebeat/
vim filebeat.ymlDesactive la salida directa a Elasticsearch y active la salida a Logstash:
#output.elasticsearch:
# Array of hosts to connect to.
# hosts: ["127.0.0.1:9200"]
output.logstash:
# The Logstash hosts
hosts: ["10.5.5.25:5044"]Ajuste la IP al servidor Logstash real en su red (en este ejemplo 10.5.5.25).
Habilite módulos de Filebeat (por ejemplo system) y configure rutas de logs según SO:
Listado de módulos:
filebeat modules listHabilitar módulo system:
filebeat modules enable systemEdite modules.d/system.yml y habilite / indique las rutas correspondientes:
Para CentOS (var.paths apunta a /var/log/messages y /var/log/secure):
# Syslog
syslog:
enabled: true
var.paths: ["/var/log/messages"]
# Authorization logs
auth:
enabled: true
var.paths: ["/var/log/secure"]Para Ubuntu (var.paths apunta a /var/log/syslog y /var/log/auth.log):
# Syslog
syslog:
enabled: true
var.paths: ["/var/log/syslog"]
# Authorization logs
auth:
enabled: true
var.paths: ["/var/log/auth.log"]Habilite y arranque Filebeat:
systemctl enable filebeat
systemctl start filebeatCompruebe el estado:
systemctl status filebeatEjemplos de salida desde clientes:
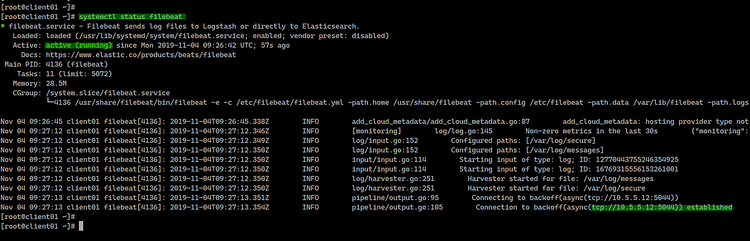
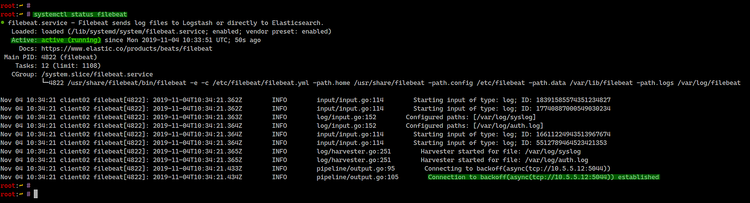
Si Filebeat está correctamente conectado, los eventos llegarán a Logstash y, luego, a Elasticsearch.
Paso 7 - Pruebas y verificación
Abra un navegador e ingrese el dominio configurado para Kibana:
Autentíquese con la cuenta creada en Nginx.
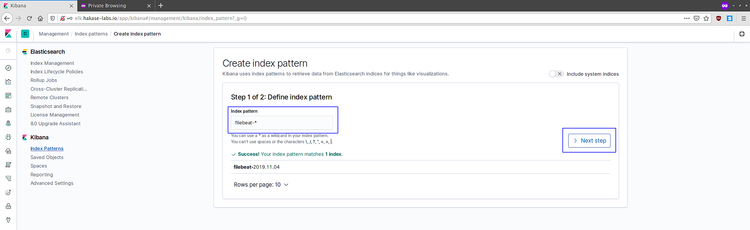
Kibana mostrará el panel principal. Vaya a gestionar índices y cree un patrón para Filebeat:
- Haga clic en “Connect to your Elasticsearch index”.
- Cree el patrón filebeat-* y elija @timestamp como campo de tiempo.
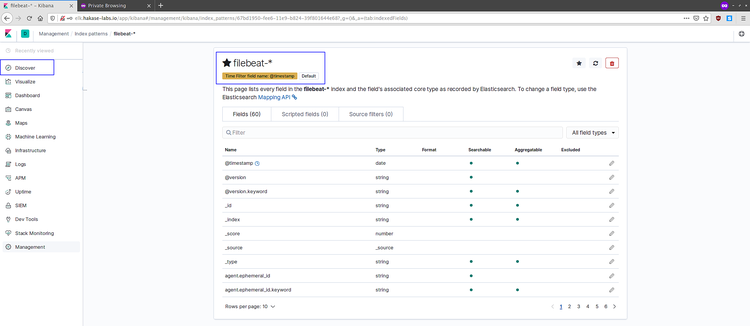
Una vez creado, vaya a Discover para ver eventos entrantes:
Ejemplos de logs recibidos:
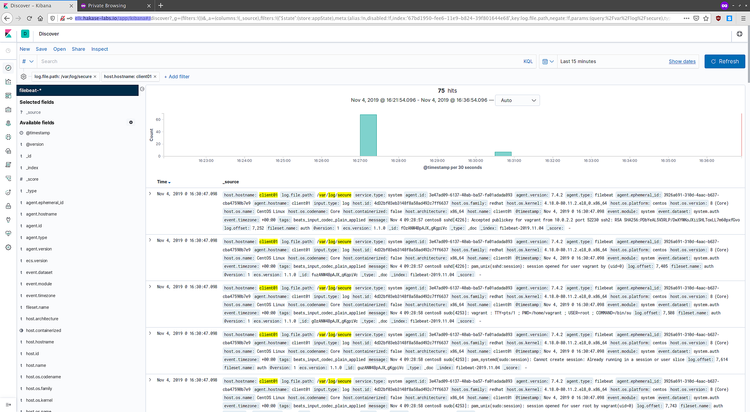
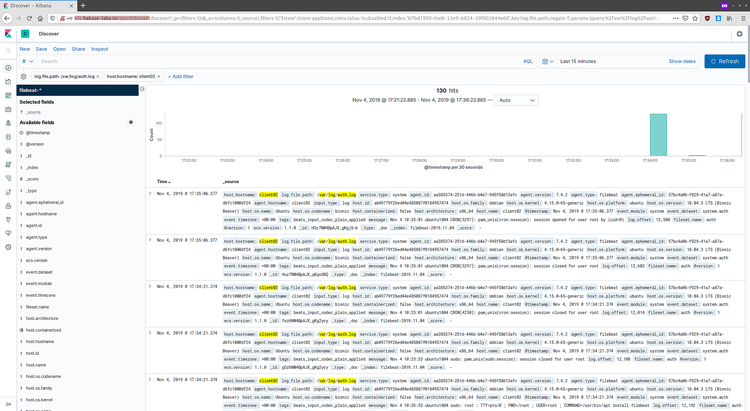
Si ve eventos, la tubería Filebeat -> Logstash -> Elasticsearch -> Kibana está funcionando.
Cómo solucionar problemas comunes
- Elasticsearch no arranca: revise memoria y permisos; vea logs con
journalctl -u elasticsearch -b. - Kibana no responde en 5601: confirme
server.hosty que Kibana está activo (systemctl status kibana). - Nginx devuelve 502/504: asegúrese de que Kibana está escuchando en 127.0.0.1:5601 y que
proxy_passapunta correctamente. - Filebeat no conecta a Logstash: verifique el puerto 5044 en el servidor (
ss -tulpn | grep 5044) y que no haya firewall bloqueando. - Grok falla en algunos mensajes: pruebe
grokdebuggeren Kibana o simplifique la expresión para identificar la parte problemática.
Consejos de depuración:
- Use
tcpdump -nn -s0 -A hostpara ver tráfico entre Filebeat y Logstash.and port 5044 - Active
logging.level: debugen Filebeat para más detalles. - Compruebe la cola de Logstash y los patrones de plantilla cuando los índices no se crean correctamente.
Checklist por rol
Administrador de sistemas (antes del despliegue):
- Confirmar requisitos de hardware y red.
- Abrir puertos: 9200 (Elasticsearch internamente), 5601 (Kibana local), 5044 (Logstash), 80/443 (Nginx).
- Crear cuentas y claves GPG necesarias.
Administrador ELK (despliegue central):
- Instalar Elasticsearch y ajustar JVM.
- Instalar Logstash y validar pipeline.
- Instalar Kibana y configurar proxy/restricciones.
- Implementar plantillas de índices y políticas ILM según la retención requerida.
Ingeniero de seguridad:
- Configurar autenticación y TLS para Elasticsearch y Kibana.
- Desplegar reglas de firewall y control de acceso por IP.
- Habilitar auditoría y rotación de credenciales.
Operaciones/Soporte:
- Configurar alertas básicas (SLI/SLO) sobre ingestión o estado del clúster.
- Documentar playbooks de rollback.
Playbook: despliegue mínimo en un servidor CentOS 8 (resumen rápido)
- Añadir clave GPG y repositorio.
- Instalar Elasticsearch y ajustar jvm.options.
- Iniciar Elasticsearch y verificar con curl.
- Instalar Kibana, configurar server.host y elasticsearch.url.
- Instalar Nginx; configurar proxy e htpasswd.
- Instalar Logstash y desplegar conf.d con input, filter y output.
- Instalar Filebeat en clientes y apuntar a Logstash.
- Verificar creación de índices filebeat-* y habilitar dashboards si procede.
Runbook de incidente: pérdida de ingestión de logs
- Verificar estado de Filebeat en clientes:
systemctl status filebeat. - Revisar logs de Filebeat:
journalctl -u filebeat -n 200. - Comprobar conectividad hacia Logstash:
curl 10.5.5.25:5044(es posible que no responda, pero probar conectividad TCP connc -vz). - En el servidor ELK, comprobar Logstash:
systemctl status logstashyjournalctl -u logstash -f. - Revisar si Logstash puede escribir a Elasticsearch: ver
templatey salud del clustercurl 'http://127.0.0.1:9200/_cluster/health?pretty'. - Si Elasticsearch está saturado, reducir ingestión o aplicar backpressure en Filebeat (rate limiting) hasta estabilizar.
- Documentar el incidente y aplicar acciones correctivas: ajustar heap, aumentar nodos, o aplicar políticas ILM.
Diagrama de decisión (Mermaid) para elegir arquitectura de ingestión
flowchart TD
A[¿Pequeño volumen de logs '<10GB/día'?] -->|Sí| B[Enviar Filebeat -> Elasticsearch]
A -->|No| C[Enviar Filebeat -> Logstash -> Elasticsearch]
C --> D{¿Necesita transformaciones complejas?}
D -->|Sí| E[Usar Logstash y filtros Grok]
D -->|No| F[Usar ingest pipelines de Elasticsearch o Logstash ligeros]
B --> G[Beneficio: menos latencia y menos CPU]
E --> H[Beneficio: mayor flexibilidad de parsing]Cuándo esta guía puede fallar (limitaciones)
- Volumen de datos en producción: aquí se usan configuraciones de heap y servicios mínimas; para producción necesita pruebas de carga y dimensionamiento.
- Seguridad: la guía usa autenticación básica en Nginx y no habilita TLS para Elasticsearch/Logstash; en entornos reales se debe cifrar todo el tráfico.
- Versiones: esta guía parte del repositorio 7.x; los parámetros y caminos cambian entre versiones mayores (por ejemplo 8.x).
Buenas prácticas de seguridad y privacidad
- Habilite TLS entre Filebeat, Logstash y Elasticsearch para cifrar datos en tránsito.
- No deje Elasticsearch abierto en interfaces públicas sin autenticación.
- Use cuentas con privilegios mínimos y cambie contraseñas por defecto.
- Revise políticas de retención y borrado para cumplir con requisitos de privacidad (GDPR) si procesa datos personales.
Pequeño glosario (1 línea por término)
- Índice: colección lógica de documentos en Elasticsearch.
- Pipeline de ingestión: flujo que transforma eventos antes de indexarlos.
- Grok: plugin de Logstash para parsear texto mediante patrones.
- Filebeat: agente ligero para enviar logs.
- ILM: Lifecycle Management de índices en Elasticsearch.
Recursos y referencias
- Documentación oficial de Elastic: https://www.elastic.co/guide/index.html
Resumen final
- Esta guía cubre un despliegue básico de Elastic Stack en CentOS 8 con Filebeat en clientes CentOS y Ubuntu.
- Para producción, planifique escalado de nodos, seguridad (TLS y autenticación), y políticas de retención.
- Pruebe cada componente (Elasticsearch, Logstash, Kibana, Filebeat) y valide la canalización completa antes de poner en producción.
Gracias por seguir esta guía. Si necesita ayuda con TLS, plantillas de índices, o adaptar Grok a logs concretos, incluya un ejemplo de línea de log y le ayudaré a construir la expresión adecuada.
Materiales similares

Podman en Debian 11: instalación y uso
Apt-pinning en Debian: guía práctica

OptiScaler: inyectar FSR 4 en casi cualquier juego
Dansguardian + Squid NTLM en Debian Etch

Arreglar error de instalación Android en SD
