Docker Desktop: CPU und Speicher überwachen
TL;DR
Docker Desktop bietet mehrere einfache Wege, CPU- und Speicherverbrauch Ihrer Container in Echtzeit zu beobachten: das Dashboard, die Resource Usage‑Erweiterung und das Terminal‑Kommando docker stats. Verwenden Sie das Dashboard für schnellen Überblick, die Erweiterung für detaillierte Graphen und docker stats für skriptbare Terminal‑Überwachung. Ergänzen Sie diese Werkzeuge mit Regeln zur Ressourcenbegrenzung, regelmäßigen Aufräumarbeiten und optionalen externen Monitoring‑Tools.
Warum Ressourcen in Docker Desktop verwaltet werden müssen
Docker Desktop betreibt Container innerhalb einer virtualisierten Umgebung. Unter Windows sind das etwa Hyper‑V oder WSL2, auf macOS wird HyperKit verwendet. Diese VM‑Schicht macht Containerverhalten auf verschiedenen Systemen konsistent, erzeugt aber auch Overhead. Docker Desktop selbst führt Hintergrundprozesse aus, die zusätzlich Ressourcen beanspruchen.
Kurz gesagt: Die Summe aus Container‑Workloads und Docker‑Diensten kann erhebliche CPU‑ und RAM‑Last erzeugen. Ohne Limits drohen ein langsamer Rechner, erhöhte Swap‑Nutzung oder instabile Container. Daher ist Monitoring nicht nur ein „nice to have“, sondern wichtig für Performance, Stabilität und Fehlersuche.
Wichtig: Monitoring zeigt, wo die Last entsteht (Container vs. Docker‑Systemprozesse). Nur so können Sie gezielt Limits setzen oder Container optimieren.
Übersicht: Was Docker Desktop überwacht
- CPU‑Auslastung pro Container und der VM.
- RAM‑Verbrauch (inkl. Swap‑Nutzung in der VM/WSL2).
- Festplatten‑I/O und belegter Speicher durch Images/Volumes.
- Netzwerkaktivität einzelner Container.
Begriff in einer Zeile:
- Container: isolierter Prozess mit eigener Laufzeitumgebung.
- VM/Host: die Maschine, in der Docker Desktop Container ausführt (HyperKit/WSL2/Hyper‑V).
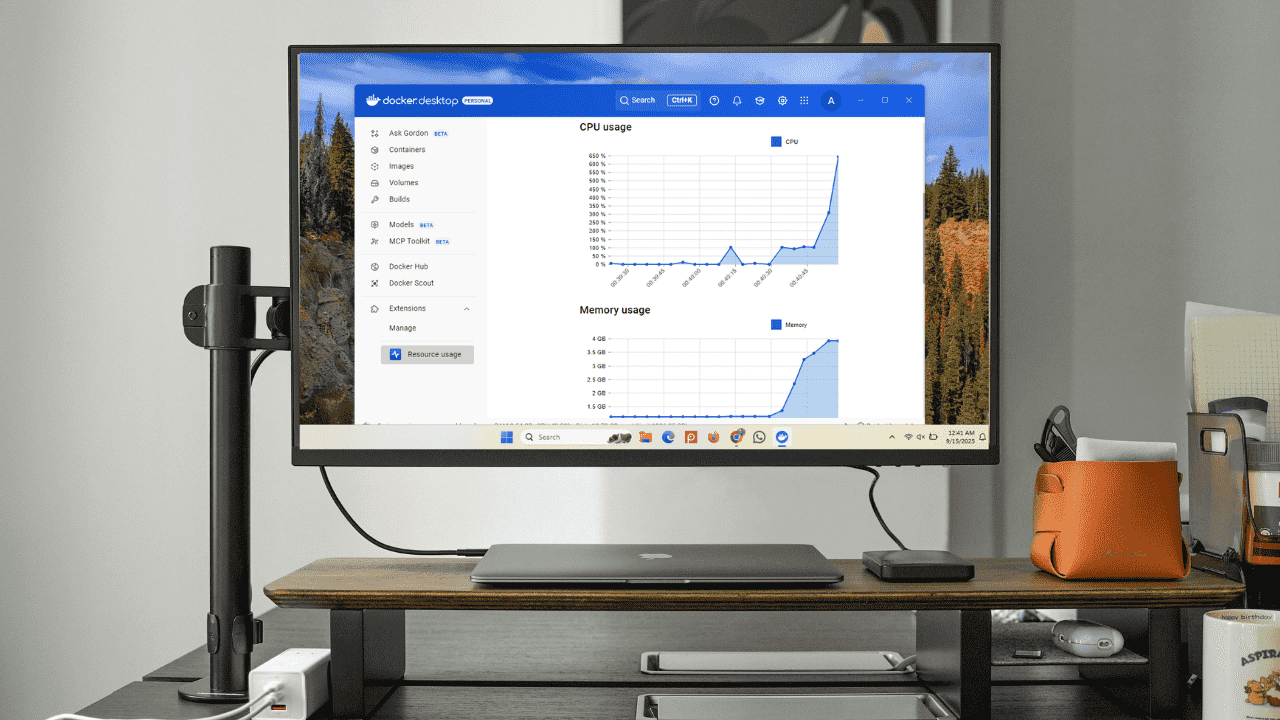
Docker Dashboard: Schnellüberblick im GUI
Das Docker Desktop Dashboard ist die einfachste Möglichkeit, Containers in Echtzeit zu überwachen. Es zeigt laufende Container mit CPU‑ und Speichernutzung direkt in der Oberfläche.
Anleitung kurz:
- Docker Desktop öffnen.
- Links «Containers» auswählen.
- Die Liste zeigt CPU‑ und RAM‑Werte für jeden Container.
Klicken Sie auf einen Container, um Logs, Umgebungsvariablen und laufende Prozesse einzusehen. Dort erscheinen detaillierte Metriken zu CPU, Speicher, Festplatte und Netzwerk in Echtzeit.
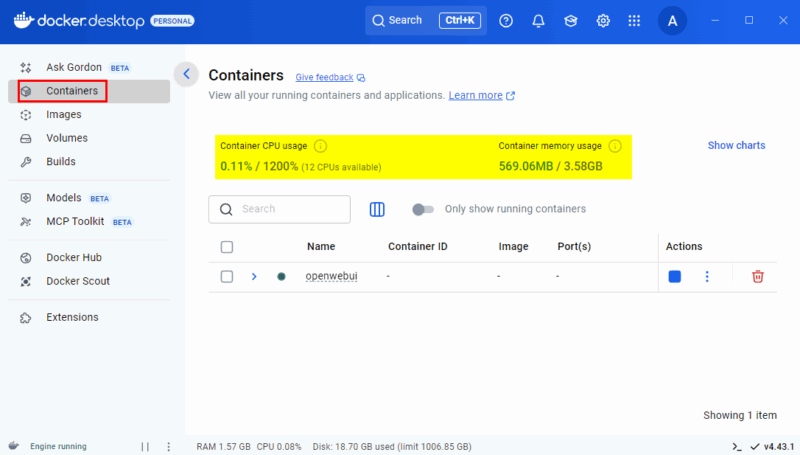
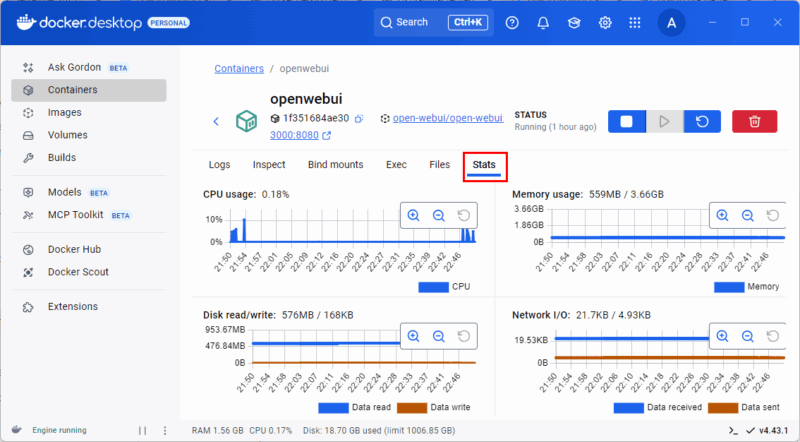
Hinweis: Das Dashboard eignet sich hervorragend für schnelle Inspektionen. Für Langzeittrends sind externe Tools besser geeignet.
Resource Usage Erweiterung: Detaillierte Insights
Die Resource Usage‑Erweiterung bietet ein dediziertes Dashboard mit erweiterten Visualisierungen: CPU‑Heatmaps, Memory‑Trends, Disk‑I/O und Netzwerkdiagramme.
Schritte zur Installation:
- In Docker Desktop links «Extensions» wählen.
- Nach “Resource Usage” suchen.
- Auf Install klicken.
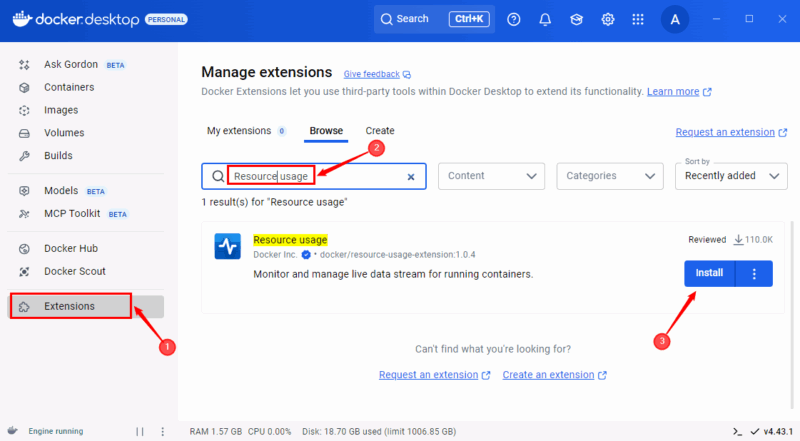
Nach der Installation finden Sie die Erweiterung in der linken Seitenleiste. Sie bietet Filter, Sortierung und eine Chart‑Ansicht für historische Trends und Spitzenwerte.
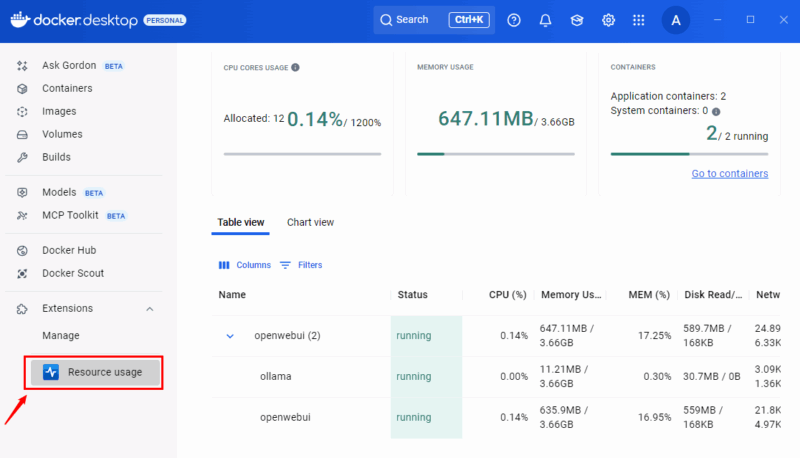
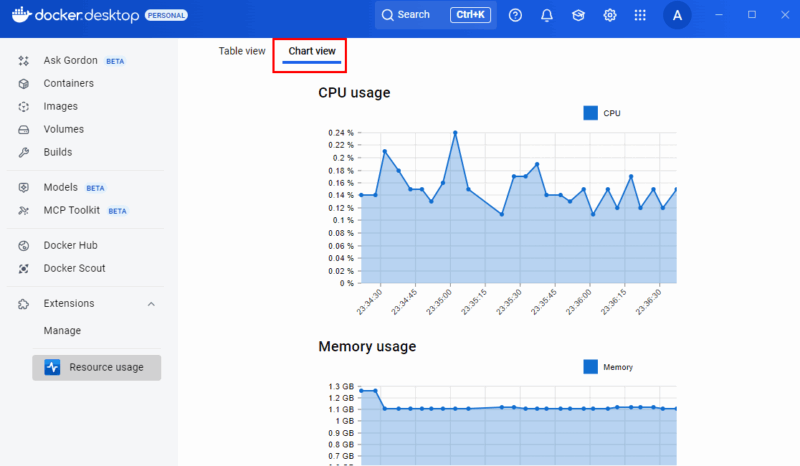
Vorteile:
- Bessere Visualisierung von kurzfristigen Spitzen.
- Einfacheres Auffinden ressourcenintensiver Container.
- Filter für Labels, Status und Namen.
Einschränkung: Diese Erweiterung bleibt lokal und ist nicht für groß angelegte, verteilte Überwachung gedacht.
Terminal: docker stats für Live‑Metriken
Für Terminal‑Fans liefert das Kommando docker stats Echtzeitmetriken für Container. Es ist skriptbar und einfach zu automatisieren.
Beispiel: Gesamte Live‑Metriken anzeigen
docker statsMit Ctrl + C stoppen Sie den Stream. Um nur einen Container zu beobachten, geben Sie dessen Namen oder ID an:
docker stats openwebui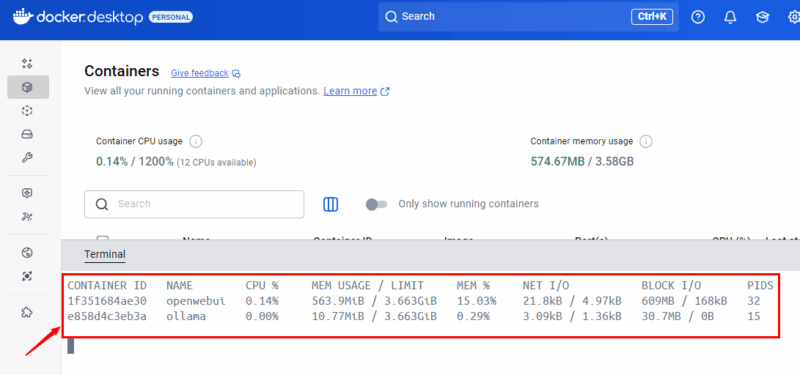
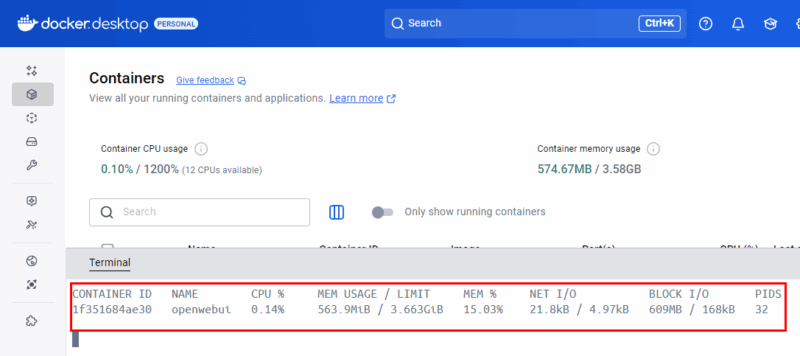
Tipp: docker stats gibt rohe Zahlen. Für historische Auswertung leiten Sie die Ausgabe in Logs oder verarbeiten sie mit Tools wie awk/jq.
Mini‑Methodik: Standard‑Vorgehen zur Fehleranalyse
- Überblick verschaffen: Dashboard öffnen, Resource Usage prüfen.
- Engpass identifizieren: Spitzen in CPU/RAM oder hoher I/O.
- Konkreten Container isolieren: docker stats
oder Dashboard‑Detail. - Prozesse innerhalb des Containers prüfen: docker exec -it
top. - Temporäre Limits setzen: CPU‑Shares oder memory limits anpassen.
- Langfristig: Image optimieren, Caching prüfen, unnötige Dienste deaktivieren.
Kriterien zur Akzeptanz (wann ist ein Problem gelöst):
- Die beobachtete CPU‑Spitze sinkt deutlich nach Optimierung.
- Der Container hält sich innerhalb der konfigurierten Memory‑Limits ohne OOM.
- System‑Swap wird reduziert und die Reaktionszeit des Hosts verbessert.
Rolle‑basierte Checklisten
Entwickler
- Überwachung im lokalen Dashboard prüfen.
- Container‑Logs nach Ausnahmen filtern.
- Memory‑Lecks auf Anwendungsebene debuggen.
SRE / Betreiber
- Limits und Reservierungen prüfen (CPU, Memory).
- Unbenutzte Images und Volumes regelmäßig löschen.
- Alerts für Persistenz‑Spitzen einrichten (bei externem Monitoring).
QA / Tester
- Lasttests auf Container‑Skalierung durchführen.
- Funktions‑ und Leistungstests mit Limits wiederholen.
Alternative Ansätze und wann sie sinnvoll sind
- Portainer: gut für visuelle Verwaltung mehrerer Hosts, wenn mehrere Docker‑Instanzen parallel betrieben werden.
- Prometheus + Grafana: ideal für langfristige Metriken, Alerting und Dashboards in Produktionsumgebungen.
- cAdvisor / node‑exporter: ergänzen Prometheus durch hostnahe Metriken.
Wann die lokalen Tools nicht ausreichen:
- Sie benötigen Langzeit‑Retention von Metriken.
- Sie betreiben verteilte Cluster über mehrere Hosts.
- Sie wollen komplexe Alert‑Regeln mit Eskalationen.
Entscheidungshilfe (Mermaid‑Flowchart)
flowchart TD
A[Start: Performance‑Problem bemerkt] --> B{Schnelle Sicht nötig?}
B -- Ja --> C[Dashboard öffnen]
C --> D{Problem sichtbar?}
D -- Ja --> E[Container isolieren und docker stats]
D -- Nein --> F[Resource Usage Erweiterung für Graphs]
B -- Nein --> G[Langfristige Lösung: Prometheus + Grafana]
E --> H[Limits setzen oder Image optimieren]
F --> H
G --> H
H --> I[Monitoring erneut prüfen]
I --> J[Problem gelöst]Playbook: Kurzmaßnahmen bei plötzlicher hoher Last
- Öffnen Sie das Dashboard und identifizieren Sie den Spitzenverursacher.
- Starten Sie docker stats für den Container und prüfen Sie CPU/Memory.
- Falls möglich, skalieren Sie die betroffene Dienstinstanz horizontal hoch oder setzen Sie temporär CPU‑Limits.
- Prüfen Sie Logs auf Fehler oder Endlosschleifen.
- Löschen Sie ungenutzte Images: docker system prune –volumes (VORSICHT: entfernt Volumes).
- Planen Sie Nacharbeiten: Profiling, Image‑Optimierung, persistent Monitoring.
Wichtig: Vor automatischem Löschen prüfen, ob Volumes benötigt werden. Backups machen.
Security‑ und Datenschutzhinweise
- Lokales Monitoring sammelt keine externen Nutzerdaten per se. Achten Sie aber auf Log‑Inhalte: sensible Daten in Logs vermeiden.
- Wenn Sie Metriken an externe Systeme senden, prüfen Sie Verschlüsselung und Zugangskontrolle.
- Beachten Sie lokale Richtlinien zur Aufbewahrung von Logs und Telemetrie‑Daten.
Kurze Glossarliste
- VM: Virtuelle Maschine, die Docker Desktop für Container nutzt.
- OOM: Out Of Memory, wenn der Kernel Prozesse beendet.
- I/O: Input/Output, z. B. Festplattenzugriff.
Zusammenfassung und Empfehlungen
Monitoring in Docker Desktop ist mehrstufig: GUI‑Dashboard für schnellen Überblick, Resource Usage‑Erweiterung für detaillierte Graphen und docker stats für Terminal‑Nutzer und Automatisierung. Verwenden Sie Limits, regelmäßiges Aufräumen und bei Bedarf externe Tools für Langzeit‑Trends. Beginnen Sie mit dem Dashboard, reproduzieren Sie Probleme lokal mit docker stats und planen Sie langfristig eine Metrik‑Pipeline (Prometheus/Grafana) für produktive Umgebungen.
Wichtig: Ohne Monitoring bleiben Ursachen von Performance‑Problemen oft verborgen. Kurze Analysezyklen und einfache Regeln (Limits, Cleanup, Alerts) reduzieren Ausfallrisiken deutlich.
Ähnliche Materialien

Podman auf Debian 11 installieren und nutzen
Apt-Pinning: Kurze Einführung für Debian

FSR 4 in jedem Spiel mit OptiScaler
DansGuardian + Squid (NTLM) auf Debian Etch installieren

App-Installationsfehler auf SD-Karte (Error -18) beheben
