Автомасштабирование в Google Cloud Platform

Быстрые ссылки
- Что такое авто масштабирование?
- Настройка управляемой группы экземпляров
Что такое авто масштабирование?
Auto Scaling — это механизм автоматического управления количеством серверов в вашем кластере. Он создаёт новые экземпляры при росте нагрузки и удаляет лишние, когда спрос падает.
Определение в одной строке: Auto Scaling — автоматическое изменение числа рабочих экземпляров по метрикам нагрузки.
Представьте, что у вас два сервера за балансировщиком нагрузки. Они делят трафик пополам. Когда нагрузка растёт, вы вручную добавляете сервер. Но пик нагрузки может повторяться циклически — каждый день или час — и управлять этим вручную неудобно.
Auto Scaling делает это автоматически. Вы задаёте шаблон экземпляра (instance template). При достижении порога нагрузки, например 70% загрузки CPU, система автоматически создаст новый экземпляр. Когда пик пройдёт, Auto Scaling сократит количество экземпляров.
Преимущества:
- Высокая доступность: трафик распределяется между работающими экземплярами.
- Экономия: вы не платите постоянно за избыточные ресурсы в периоды простоя.
- Быстрая реакция на всплески трафика.
Важно: шаблон экземпляра должен корректно описывать конфигурацию сервера и процессы запуска (startup script, контейнер или образ). В противном случае новые экземпляры будут некорректны.
Когда авто масштабирование особенно полезно
- Веб‑приложения с переменной дневной/сезонной нагрузкой.
- Пиковые события (распродажи, маркетинговые рассылки, новости).
- Сервисы с требованием высокой доступности.
Когда авто масштабирование может не подойти
- Приложения с долгой и тяжёлой инициализацией состояния (многочасовой запуск). Авто‑масштабирование полезно только если новые экземпляры доходят до рабочего состояния быстро.
- Состояние, привязанное к локальному диску. Если приложение сохраняет критичные данные на локальном диске экземпляра, удаление экземпляра приведёт к потере данных.
- Лицензирование, привязанное к хосту, где резкое увеличение/уменьшение экземпляров нарушит лицензионные условия.
Настройка управляемой группы экземпляров (Managed Instance Group)
- В консоли GCP выберите Compute Engine > Instance Groups.
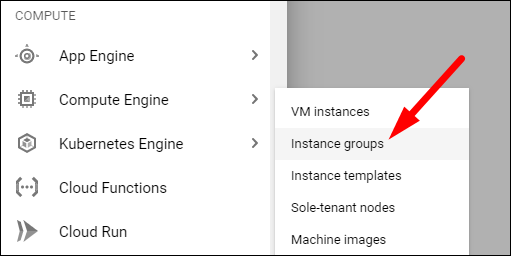
Нажмите «Create» и выберите New Managed Instance Group.
Определите регион и зоны. Рекомендуется распределять экземпляры по нескольким зонам ради отказоустойчивости. Группа привязывается к одному региону; для других регионов создавайте дополнительные группы.
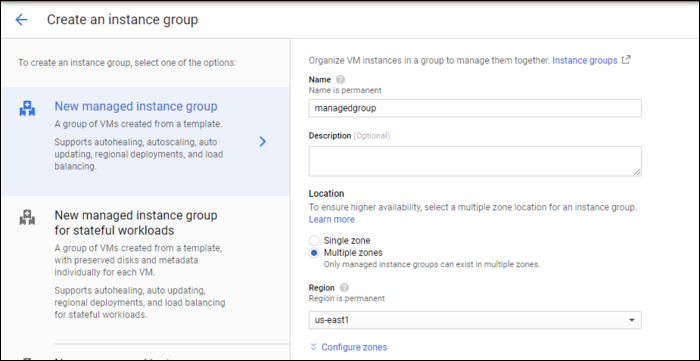
- Выберите или создайте instance template. Шаблон задаёт образ, метаданные, скрипты запуска и т.д. Если у вас нет шаблона, прочитайте руководство «Как создать и использовать шаблоны экземпляров в Google Cloud Platform».
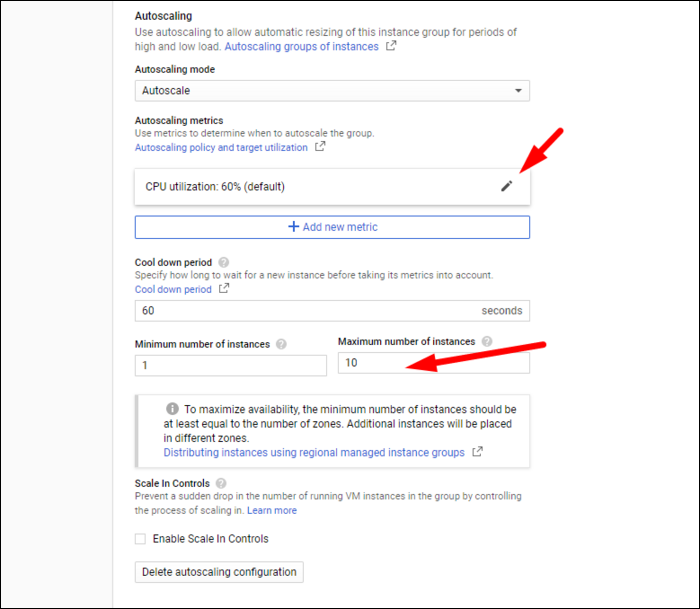
- Настройте параметры авто масштабирования:
- Режим масштабирования: автоматический рост и уменьшение (по умолчанию) или только рост.
- Метрика для масштабирования: по умолчанию CPU (60%). Вы можете выбрать HTTP(S) RPS, custom metrics, load balancing utilization и т.д.
- Интервал охлаждения (cool-down): период, в течение которого новые экземпляры считаются «в процессе запуска» и не учитываются при последующих решениях о масштабировании.
- Минимальное и максимальное число экземпляров: минимизирует влияние отказов и ограничивает расходы.
- Включите Autohealing. Это функция, которая периодически выполняет health check на каждом экземпляре и автоматически перезапускает или заменяет проблемные экземпляры. Если у вас есть балансировщик нагрузки, он перестроит маршрутизацию, но сам экземпляр останется неисправным без Autohealing.
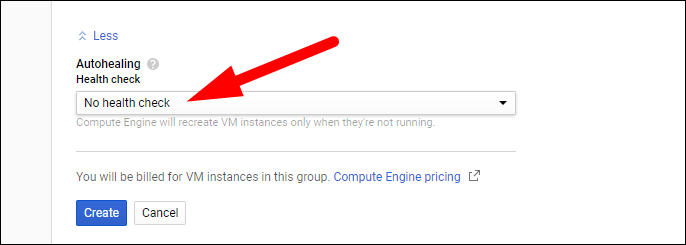
- Нажмите Create. Минимальное число экземпляров будет создано сразу. Управляйте отдельными экземплярами через Compute Engine или изменяйте шаблон, чтобы обновить всю группу.
Практическая мини‑методология внедрения Auto Scaling
Шаги (быстро):
- Проанализируйте рабочие нагрузки и выявите пиковые периоды.
- Подготовьте бездисковый/контейнерный образ или корректный startup script.
- Создайте instance template с мониторингом и метриками.
- Создайте Managed Instance Group, включите Autohealing.
- Настройте метрики и пороги (начните с CPU 50–70%).
- Протестируйте на нагрузке: искусственные пики и ожидания cooldown.
- Настройте лимиты (min/max) и алерты на бюджет/ошибки.
Чек‑лист по ролям
DevOps / SRE:
- Подготовить instance template.
- Настроить health checks и Autohealing.
- Провести нагрузочное тестирование.
Архитектор:
- Определить зоны и политику распределения.
- Оценить влияние на хранилище и согласовать backup/репликацию.
Разработчик:
- Обеспечить идемпотентный startup script.
- Проверить корректность миграции состояния при добавлении/удалении экземпляров.
Критерии приёмки
- Новые экземпляры успешно стартуют и проходят health check.
- Балансировщик распределяет трафик равномерно.
- Система масштабируется при достижении порога и уменьшается при падении нагрузки.
- Нет потерь данных при масштабировании (или есть надёжная репликация).
- Стоимость в рамках ожидаемых лимитов.
Альтернативные подходы
- Ручное масштабирование — подходит для небольших систем или когда автоматизация невозможна.
- Предсказуемое (scheduled) масштабирование — увеличивать/уменьшать число экземпляров по расписанию при известной нагрузке.
- Kubernetes + Horizontal Pod Autoscaler — если приложение контейнеризовано и управляется GKE, масштабируйте контейнеры, а не VM.
Когда авто масштабирование может ошибаться (случаи отказа)
- Неправильный или отсутствующий health check: Autohealing не сработает.
- Длинный startup: экземпляры ещё не готовы, но система считает их проблемными.
- Неподходящая метрика: CPU может не отражать узкое место в I/O или базе данных.
- Неполная идемпотентность скриптов инициализации → некорректные или конфликтующие экземпляры.
Факт‑бокс: важные числа и понятия
- Метрика по умолчанию: CPU 60% (в интерфейсе GCP часто 60% как стартовая настройка).
- Cool‑down: зависит от времени старта приложения; типично — 60–300 секунд.
- Минимум/максимум: задавайте в зависимости от SLA и бюджета.
Рекомендации по безопасности и приватности
- Не храните секреты в шаблоне без шифрования. Используйте Secret Manager или IAM.
- Ограничьте права сервисных аккаунтов экземпляров по принципу наименьших привилегий.
- Логируйте события масштабирования для аудита и отладки.
Тестовые сценарии и приёмка
- Нагрузочный тест: синтетический рост запросов до 2–3× базового уровня. Оцените время на масштабирование и восстановление SLA.
- Failover test: выключите экземпляр и проверьте, что Autohealing заменяет его.
- Регрессионный тест: обновите шаблон и проверьте стратегию обновления (rolling update).
Итог
Автомасштабирование в GCP даёт гибкость и устойчивость. Оно помогает справляться с пиковыми нагрузками, оптимизировать расходы и поддерживать высокую доступность. Ключевые элементы — корректный шаблон экземпляра, разумные метрики и включённый Autohealing. Начинайте с минимальной рабочей конфигурации, тестируйте под нагрузкой и постепенно улучшайте пороги и политики.
Важно: перед запуском в продакшен прогоните тесты и убедитесь, что всё состояние приложения хранятся вне локальных дисков экземпляров.
Краткое резюме:
- Настройте instance template и Managed Instance Group.
- Выберите подходящую метрику и значения min/max.
- Включите Autohealing и выполните нагрузочное тестирование.
Похожие материалы

Троян Herodotus: как он работает и как защититься
Включить новое меню «Пуск» в Windows 11

Панель полей PivotTable в Excel — руководство

Включить новый Пуск в Windows 11 — инструкция
Как убрать дубликаты Диспетчера задач Windows 11
