Введение в statsmodels: линейные модели и ANOVA в Python

Statsmodels — это библиотека Python для статистического моделирования, удобная для линейной регрессии и анализа дисперсии (ANOVA). В статье показаны примеры простых и множественных регрессий, квадратичных моделей, одно- и двухфакторного ANOVA, а также рекомендации по диагностике модели, альтернативные подходы и практические чеклисты для ролей в команде.

Что такое statsmodels?

statsmodels — это библиотека Python для выполнения распространённых статистических тестов и построения моделей. Она особенно ориентирована на регрессионный анализ и эконометрику, но пригодна для любой дисциплины, где важна точная оценка параметров и расширенная диагностика модели.
Коротко о характерных особенностях:
- Поддерживает R-подобные формулы через API формул (patsy).
- Даёт удобные табличные сводки (summary) с тестами и диагностикой.
- Совместима по результатам с R, Stata и SAS для проверок воспроизводимости.
Важно: statsmodels не предназначен для продакшен-ML-пайплайнов (векторизованных предикций на миллионах записей) — для этого чаще используют scikit-learn. statsmodels сильна там, где нужны статистические тесты, оценки дисперсий и доверительные интервалы.
Установка и импорт
Установить statsmodels можно через pip или conda:
pip install statsmodels
# либо
conda install statsmodelsТипичный импорт в ноутбуке Jupyter или скрипте:
import statsmodels.formula.api as smf
import statsmodels.api as sm
import numpy as np
import pandas as pd
import seaborn as snsПростая линейная регрессия: пример на данных Seaborn
Мы используем встроенный набор данных tips от Seaborn — это таблица с информацией о счётах и чаевых в ресторане.
sns.set_theme()
tips = sns.load_dataset('tips')Посмотрим начало таблицы:
tips.head()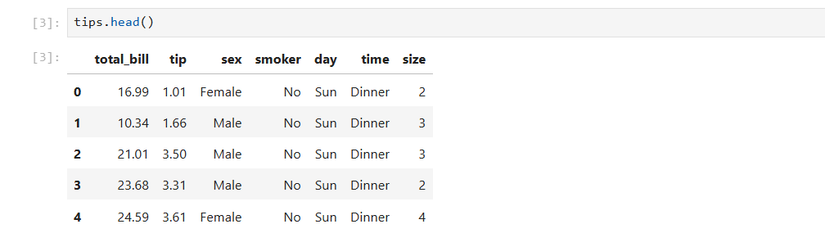
Нарисуем рассеяние (scatterplot) чаевых против полного счёта:
sns.relplot(x='total_bill', y='tip', data=tips)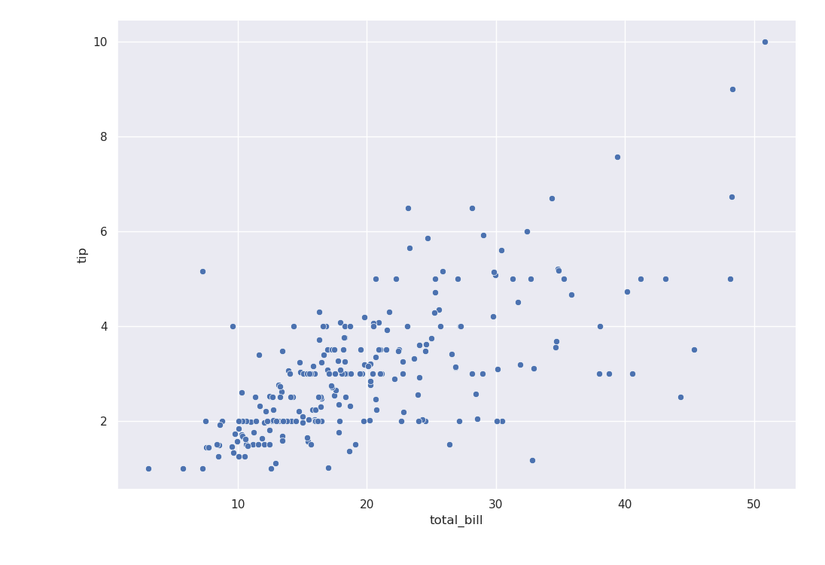
Выглядит как положительная зависимость. Для визуального приближения можно добавить регрессионную линию:
sns.regplot(x='total_bill', y='tip', data=tips)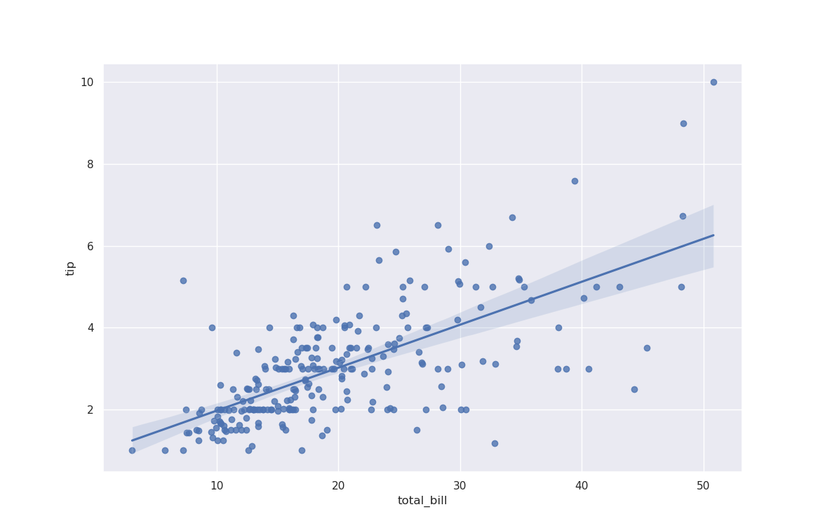
Чтобы получить числовые оценки коэффициентов и статистические тесты, используем statsmodels и R-подобную формулу:
results = smf.ols('tip ~ total_bill', data=tips).fit()- ols — Ordinary Least Squares (метод наименьших квадратов).
- В формуле ‘tip ~ total_bill’ левее тильды — зависимая переменная (эндогенная), правее — независимая (экзогенная).
- .fit() возвращает объект с результатами оценки.
Посмотреть сводку в скрипте:
print(results.summary())В интерактивной сессии достаточно:
results.summary()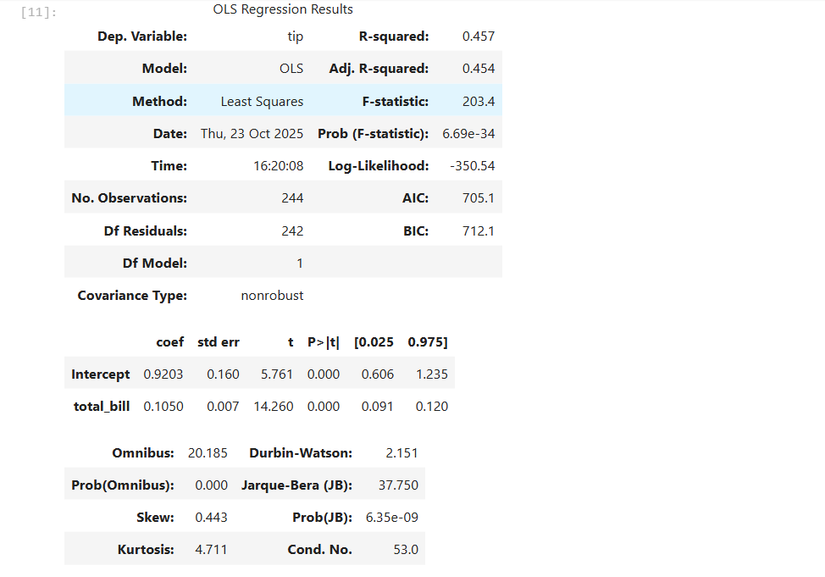
Использование массивов NumPy и матрицы проектирования
Если вы предпочитаете API без формул, можно создавать дизайн-матрицу вручную. Пример с синтетическими данными:
x = np.linspace(-10, 10, 100)
y = 2 * x - 3
X = sm.add_constant(x) # добавляет столбец из единиц (интерсепт)
model = sm.OLS(y, X)
results = model.fit()
print(results.summary())Обратите внимание: в API «без формул» функция называется OLS в верхнем регистре (sm.OLS), и порядок аргументов — (эндоген, экзоген).
Множественная линейная регрессия
Чтобы добавить дополнительные предикторы, просто расширьте формулу через “+”:
results = smf.ols('tip ~ total_bill + size', data=tips).fit()
results.summary()Добавка переменной size (размер компании) показывает, полезна ли она как контролирующая переменная.
Нелинейные зависимости через трансформации
Чтобы моделировать квадратичную зависимость, можно добавить в формулу трансформированную переменную. Пример:
x = np.linspace(-10, 10, 100)
y = 3 * x**2 + 2 * x + 5
import pandas as pd
df = pd.DataFrame({'x': x, 'y': y})Визуализация:
sns.relplot(x='x', y='y', data=df)
Модель с квадратичным членом:
results = smf.ols('y ~ x + I(x2)', data=df).fit()
results.summary()I() сообщает patsy/statsmodels, что выражение внутри — это операция над столбцом, а не новый регрессор с именем ‘x2’.
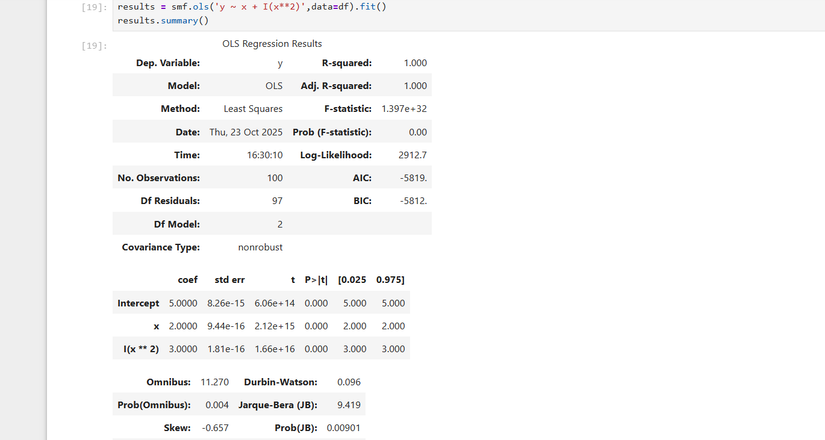
Интерпретация результатов регрессии
В выводе results.summary() ключевые элементы:
- R-squared — доля объяснённой дисперсии (чем ближе к 1, тем лучше объяснение). Для множественной регрессии смотрите также adjusted R-squared, который корректирует рост R^2 при добавлении переменных.
- Коэффициенты регрессоров и их стандартные ошибки (std err).
- t-статистика и p-value для проверки нулевой гипотезы, что коэффициент равен нулю. Часто используют порог 0.05.
- Доверительные интервалы для коэффициентов (обычно 95%).
- Диагностика остатков: распределение, skew, kurtosis — помогают оценить нормальность остатков.
Примерные пояснения:
- Интерсепт (const) — значение y при всех x=0 (интерпретация зависит от центрирования переменных).
- Коэффициент при total_bill показывает, на сколько в среднем изменяется tip при единичном изменении total_bill, при прочих равных.
- std err измеряет разброс оценок коэффициента: меньше — надёжнее оценка.
Важно: статистическая значимость не означает практической значимости. Всегда смотрите на размер эффекта и контекст.
Диагностика модели и распространённые проверки
Основные допущения классической линейной регрессии, которые стоит проверить:
- Линейность отношения между зависимой и независимыми переменными.
- Независимость ошибок (остатков).
- Гомоскедастичность (одинаковая дисперсия ошибок при разных предикторах).
- Нормальность распределения ошибок (для корректных p-value и доверительных интервалов при малых выборках).
- Отсутствие сильной мультиколлинеарности между регрессорами.
Практические тесты и инструменты в statsmodels:
- Проверка гетероскедастичности: sm.stats.diagnostic.het_breuschpagan
- Проверка нормальности остатков: sm.stats.shapiro (или scipy) / график Q-Q: sm.qqplot
- Влиятельные наблюдения: модель.get_influence().summary_frame()
- VIF (variance inflation factor) для мультиколлинеарности (через statsmodels или вручную)
Пример: тест на гетероскедастичность (Breusch–Pagan):
from statsmodels.stats.diagnostic import het_breuschpagan
bp_test = het_breuschpagan(results.resid, results.model.exog)Если предположения нарушены, возможные действия:
- Варианты трансформации переменных (логарифмирование, полиномиальные члены).
- Робастные стандартные ошибки (HC0–HC3): results.get_robustcov_results(cov_type=’HC3’)
- Взвешенные МНК (WLS) при известной различной дисперсии ошибок.
Однофакторный ANOVA (one-way ANOVA)
ANOVA позволяет сравнить средние значения числовой переменной между категориями. Пример с набором penguins:
penguins = sns.load_dataset('penguins')
penguins.head()Проверим, зависит ли длина клюва (bill_length_mm) от вида (species):
penguin_lm = smf.ols('bill_length_mm ~ species', data=penguins).fit()
results = sm.stats.anova_lm(penguin_lm)
print(results)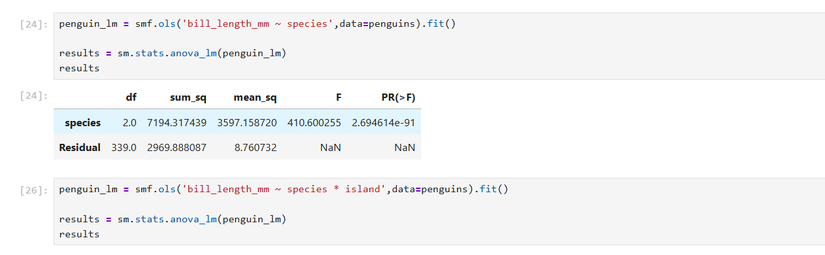
Интерпретация: в таблице ANOVA ключевой показатель — p-value для фактора. Низкое p-value (значимо ниже 0.05) указывает, что хотя бы одна группа отличается по среднему.
Двухфакторный ANOVA и взаимодействия
Можно добавить ещё один категориальный фактор и взаимодействие между ними:
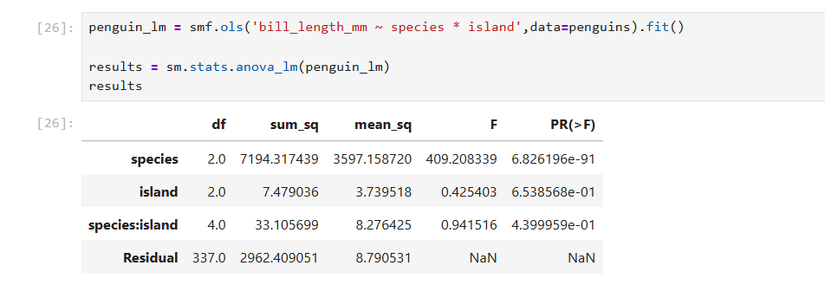
penguin_multi_lm = smf.ols('bill_length_mm ~ species * island', data=penguins).fit()
results = sm.stats.anova_lm(penguin_multi_lm)
print(results)Оператор “*” в формуле добавляет оба основных эффекта и их взаимодействие (species, island, species:island).
Когда statsmodels не лучший выбор или где нужно быть осторожным
- Масштабирование и продакшен: для больших пайплайнов и непрерывных предсказаний чаще выбирают scikit-learn.
- Нелинейные модели ML (деревья, бустинг, нейросети): statsmodels заточен под статистическую оценку, но не под современные ансамбли и нейронные сети.
- Time series с высокой сложностью — используйте специализированные пакеты (statsmodels содержит подсистему для ARIMA/tsa, но для сложных задач могут требоваться дополнительные библиотеки).
Альтернативы и когда применять какую библиотеку
- scikit-learn — хорошо для машинного обучения, кросс-валидации и пайплайнов, но даёт меньше статистических тестов.
- R (lm, aov) — богатая статистическая экосистема, удобны готовые диагностические визуализации.
- patsy — используется внутри statsmodels для формул; полезно знать синтаксис формул.
Практическое руководство: шаги от данных до доверия в модели
- Оценка данных: пропуски, типы, распределения.
- Визуализация зависимостей (scatter, boxplot, pairplot).
- Выбор модели (простая линейная, множественная, полиномиальная, ANOVA).
- Оценка модели (fit, summary).
- Диагностика остатков и тесты допущений.
- При необходимости: трансформации, удаление выбросов, робастные оценки.
- Интерпретация коэффициентов, доверительных интервалов и p-value.
- Документация результатов и воспроизводимость (код + версия пакетов).
Чек-лист по ролям
Далее — краткие контрольные списки для разных ролей. Они помогут быстро проходить базовые шаги.
Data Scientist / Исследователь:
- Провёл разведывательный анализ данных (EDA).
- Выбрал подходящую спецификацию модели и проверил альтернативы.
- Провёл тесты на гетероскедастичность и нормальность остатков.
- Оценил мультиколлинеарность (VIF) и влияние наблюдений.
- Сформулировал выводы и описал практическую значимость.
Аналитик / BI:
- Построил визуализации для стейкхолдеров (scatter, residuals, coef plot).
- Проверил, что метки и единицы измерения понятны и корректны.
- Представил интерпретацию в понятных единицах: вклад предиктора в реальные величины.
Исследователь методов / академик:
- Проверил согласованность результатов с альтернативными пакетами (R, Stata).
- Документировал настройки оценки (cov_type, robust SE).
- Привёл реплицируемый скрипт и набор данных (или seed для генерации).
Краткая методология тестирования модели (мини-SOP)
- Разбить данные на train/test (если цель — предсказание). Для научного вывода можно использовать всю выборку, но проводить устойчивую проверку устойчивости (robustness checks).
- Подогнать модель на train.
- Проверить остатки и стабильность коэффициентов.
- Оценить качество на test (если есть) и сравнить предсказания с простыми базовыми моделями (mean, median).
- Прописать критерии приёмки (см. ниже).
Критерии приёмки
- Коэффициенты интерпретируемы и имеют ожидаемые знаки.
- Остатки не показывают структурированной автокорреляции.
- Для inferential задач p-value и доверительные интервалы подтверждают гипотезы.
- В production-предсказаниях точность/MAE/RMSE находятся в пределах допустимых значений для задачи.
Примерный набор тест-кейсов и приёмочных критериев
- Отсутствие NaN в ключевых переменных → модель обучена успешно.
- При изменении семплинга (bootstrap) значения коэффициентов остаются близкими.
- При удалении явных выбросов структура коэффициентов не меняется радикально.
Примеры кода: робастные стандартные ошибки и влияние наблюдений
Робастные стандартные ошибки (HC3):
robust_res = results.get_robustcov_results(cov_type='HC3')
print(robust_res.summary())Инфлюэнс (влияние наблюдений):
influence = results.get_influence()
summary_frame = influence.summary_frame()
# summary_frame содержит: cooks_d, student_resid, hat_diag и др.Визуальные диагностические графики
- Q-Q plot для остатков: sm.qqplot(results.resid, line=’s’)
- Scatter остатков vs. предсказанных: plt.scatter(results.fittedvalues, results.resid)
- Cook’s distance для выявления влияющих наблюдений.
Mermaid-диаграмма принятия решения (алгоритм выбора модели):
flowchart TD
A[Начало: данные] --> B{Цель: предсказание или инференс?}
B -->|Предсказание| C[scikit-learn: пайплайн, CV]
B -->|Инференс| D[statsmodels: OLS / WLS / GLS]
D --> E{Категориальные предикторы?}
E -->|Да| F[Использовать формулы с категориальными переменными]
E -->|Нет| G[Стандартная регрессия]
F --> H{Есть взаимодействия?}
H -->|Да| I[Добавить interaction term с *]
H -->|Нет| J[Оценить модель и диагностировать]Общие ошибки и пути их устранения
- Ошибка: неправильный порядок аргументов в sm.OLS → помните порядок (эндоген, экзоген).
- Ошибка: забыли добавить константу → используйте sm.add_constant или включите implicit intercept в формуле.
- Ошибка: категориальные переменные представлены числами без явной кодировки → используйте C(variable) в формуле или pd.get_dummies.
- Ошибка: интерпретация взаимодействий без центрирования → центрируйте переменные, чтобы упростить интерпретацию.
Глоссарий (одно предложение на термин)
- эндоген (endogenous): зависимая переменная, которую пытаемся объяснить.
- экзоген (exogenous): независимые переменные, объясняющие изменения зависимой.
- R-squared: доля объяснённой вариации зависимой переменной.
- p-value: вероятность получить наблюдаемый эффект, если нулевая гипотеза верна.
- гетероскедастичность: неоднородность дисперсии ошибок по значениям предикторов.
Когда результаты следует проверять дополнительно
- Если p-values крайне близки к порогу 0.05 — выполняйте дополнительные тесты устойчивости.
- Если имеются сильные выбросы или высокие значения Cook’s distance — оцените влияние каждого наблюдения.
- Если признаки коррелируют между собой (высокие VIF) — рассмотрите удаление или комбинацию предикторов.
Краткое резюме
Statsmodels — мощный инструмент для статистического моделирования в Python. Он хорош для научных и прикладных задач, где важна детальная интерпретация коэффициентов, доверительные интервалы и диагностические тесты. Для задач предсказания в продакшн стоит дополнительно рассматривать scikit-learn и библиотечные решения для масштабирования.
Важные шаги практической работы: подготовка данных, выбор модели, оценка и диагностика, интерпретация и проверка альтернативных спецификаций. Используйте робастные ошибки и проверки устойчивости, когда допущения модели нарушены.
Ключевые ссылки и дальнейшие шаги:
- Документация statsmodels: https://www.statsmodels.org (ознакомьтесь с API, diagnostics и примерами)
- Руководства по эконометрике и практической регрессии для глубокого понимания допущений и интерпретации
Важно
Если вы готовите доклад или статью, прикладывайте скрипт и версию пакетов, чтобы обеспечить воспроизводимость результатов.
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
