Как оставаться онлайн при сбоях облака

Введение: почему этот материал важен
Сбои крупных облачных провайдеров перестали быть редкостью и теперь идут вразрез с ожиданиями пользователей о круглосуточной доступности сервисов. Последний крупный инцидент в US‑EAST‑1 показал, что даже огромные, технически мощные инфраструктуры уязвимы: отказ мониторинга сети привёл к нарушению DNS‑разрешения в DynamoDB и каскадным сбоям в EC2, Lambda и SQS, что отразилось на тысячах сервисов.
Понимание того, какие элементы вашего стека зависят от централизованных облаков, и внедрение нескольких простых мер защиты позволяет свести риски к приемлемому уровню.
Что случилось на практике (факты)
- Инцидент произошёл 20 октября 2025 г. в регионе US‑EAST‑1.
- Из‑за проблемы в сетевом мониторинге пострадали DNS‑запросы в DynamoDB и последовали каскадные отказы сервисов.
- Amazon, по данным опубликованных отчётов, терял примерно $72 млн в час во время длительных сбоев; у крупных компаний потери оценивались в миллионы долларов в час.
- Около 30% мирового рынка облачных услуг приходится на одного из лидеров, что усиливает эффект концентрации.
Эти факты показывают главную уязвимость: слишком большая зависимость от нескольких крупных поставщиков.
Почему интернет «ломается» массово
Концентрация трафика и сервисов в отдельных регионах и у нескольких крупных провайдеров создаёт точку единой ответственности. Когда такая точка даёт сбой, «эффект домино» быстро распространяется на сотни и тысячи приложений: платежные шлюзы, игровые платформы, корпоративные сервисы и умные устройства.
Это не случайность, а системная особенность архитектуры современных публичных облаков: экономия масштаба и удобство для разработчиков противоречат распределённой устойчивости.
Как облачная удобность ставит пользователей в зависимость
Облачные сервисы дают удобство: доступ с любого устройства, мгновенная синхронизация, удалённый бэкап. Но это удобство оплачивается отказом владения над инфраструктурой. В результате при сбое облака вы теряете не только приложение, но и функциональность, которую оно обеспечивает: платежи, умный дом, совместную работу.
В последнем инциденте более 270 млн устройств IoT оказались под риском по сочетанию зависимостей и уязвимостей. Это пример того, как массовая интеграция без резервных путей ведёт к массовым неприятностям.

Практические решения: шаги, которые вы можете сделать сегодня
Ниже — набор действий, которые можно применять по отдельности или в комбинации, в зависимости от ролей (частный пользователь, владелец малого бизнеса, сисадмин, разработчик).
1. Переход на local‑first приложения
Определение: local‑first = приложения, в которых рабочая копия данных находится локально и синхронизируется в фоновом режиме.
Почему это работает: вы сохраняете работоспособность в офлайне и синхронизируете изменения, когда соединение восстановлено.
Рекомендации:
- Замените облачные блокноты на Obsidian или Joplin (локальное хранение и синхронизация при необходимости).
- Для файлового обмена используйте Syncthing вместо единого облачного хранилища.
- Для чата и collaboration рассмотрите Matrix/Element вместо полностью управляющих облачных сервисов.
- Для документов — LibreOffice + периодический экспорт, или включённый офлайн‑режим в Google Docs.
Контрпример: local‑first не решит проблему, если вы нуждаетесь в мгновенном глобальном совместном редактировании у сотен пользователей одновременно — там остаются компромиссы между согласованностью и доступностью.
2. Включите и проверьте офлайн‑режимы и локальные бэкапы
Простые шаги:
- Экспортируйте критичные данные ежедневно (CSV, JSON, DB‑дампы).
- Настройте локальные копии почты и документов.
- Включите офлайн‑доступ в Gmail, Google Docs, Spotify и других приложениях, где это возможно.
Пример: пользователи Notion, которые регулярно делали локальные экспортные копии во время последнего сбоя, продолжили работать без потери данных.
3. Управление умным домом локально
Смарт‑дом часто зависит от внешних сервисов (Alexa, облачные мосты). Перенос логики и критичных устройств в локальную сеть даёт автономность.
Рекомендации:
- Запустите Home Assistant на Raspberry Pi или мини‑сервере для локального управления автоматизацией.
- Используйте Zigbee/Z‑Wave шлюзы для связи с лампами и замками, чтобы они работали без интернета.
- Рассмотрите Hubitat или Apple HomeKit (с локальными ролями) для приватности и устойчивости.
Ограничение: локальные решения требуют базовых навыков настройки сети и иногда покупки дополнительного оборудования.
4. Гибридные резервные копии и локальные NAS
Идея: сохраняйте быстрый локальный доступ и резервное копирование off‑site.
Рекомендации:
- NAS (Synology, QNAP) в локальной сети + периодическая репликация в облако (S3 или другой провайдер) для off‑site защиты.
- Nextcloud как «мини‑облако» на домашнем сервере или VPS с шифрованием и версионностью.
- Настройте ежедневные, инкрементальные и офф‑сайт резервные копии для критичных данных.

5. Multi‑cloud и поставщики периферии (edge)
Для бизнеса: распределяйте критичные сервисы между несколькими регионами и поставщиками (multi‑cloud) и используйте CDN/edge‑поставщиков, чтобы снизить нагрузку на центральные регионы.
Плюсы: уменьшение риска концентрации, гибкость при локальных проблемах у одного провайдера.
Минусы: рост стоимости и операционной сложности; требуется автоматизация развертывания.
Мини‑методология внедрения устойчивости (пошагово)
- Инвентаризация: зафиксируйте все сервисы и зависимости (чеклист по ролям).
- Приоритизация: выделите критичные для бизнеса/жизни функции (платежи, доступ к помещениям, базы клиентов).
- Быстрые победы: включите офлайн‑режимы, ежедневные экспорты, локальные копии конфигураций.
- Технические меры: настройте NAS/Nextcloud, локальную автоматизацию, Syncthing.
- Тестирование: симулируйте сетевой разрыв и проверяйте, как работают ваши сценарии.
- Автоматизация и документация: скрипты синхронизации, playbook для восстановления.
Роль‑ориентированные чеклисты
Частный пользователь:
- Включить офлайн‑режимы мессенджеров и почты.
- Сделать экспорт заметок и контактов.
- Настроить локальный контроль умного дома (если есть).
Владелец малого бизнеса:
- Локальные копии бухгалтерии и клиентских данных.
- Резервные каналы оплаты и ручные процедуры приёма платежей.
- План переключения на резервные услуги (контакты поставщиков).
Сисадмин/DevOps:
- Multi‑region deploy и health checks.
- Репликация данных на локальные и альтернативные облака.
- Скрипты автоматического failover и тесты восстановления.
SOP: быстрый план на случай облачного сбоя
- Оповестить команду и включить инцидент‑чат.
- Переключить критичные сервисы на локальные или резервные копии.
- Запустить заранее настроенные скрипты переключения (failover).
- Логировать изменения и уведомлять пользователей с инструкциями.
- После восстановления — проанализировать причины и обновить playbook.
Критерии приёмки: после переключения ключевые функции (авторизация, оплата, базы данных) должны быть доступны в тестовой сессии в пределах 15 минут.
Когда местные меры не помогут (ограничения)
- Массовое отключение электричества/интернет‑каналов в регионе оставляет локальные решения беспомощными.
- Сложные распределённые транзакции с требованием сильной согласованности (ACID) могут не поддерживаться в offline‑first моделях без серьёзных архитектурных изменений.
- Физическое повреждение оборудования: локальные NAS и Raspberry Pi тоже ломаются — нужен off‑site бэкап.
Риск‑матрица (качество→вероятность)
- Потеря связи с облаком: средняя вероятность, высокий импакт → митигаторы: local‑first, off‑site бэкап.
- Аппаратная поломка локального хранилища: низкая вероятность, средний импакт → митигаторы: RAID, удалённые копии.
- Потеря данных из‑за некорректной синхронизации: низкая вероятность, высокий импакт → митигаторы: версионность, контроль целостности.
Приватность и соответствие (GDPR и данные)
- Локальное хранение даёт преимущество в контроле над данными — проще документировать места хранения и исполнять запросы субъектов данных.
- При репликации в облако обязательно шифрование и контроль доступа, логирование и контрактные обязательства с провайдером.
- Для передачи в оф‑site хранилища используйте защищённые каналы (TLS), шифрование на стороне клиента и минимизацию объёма персональных данных.
Тесты и приёмка
Основные тест‑кейсы:
- Отключение внешнего интернета: рабочие процессы должны продолжать работать в течение N часов.
- Восстановление синхронизации: изменения, сделанные локально, корректно синхронизируются в облако без потери.
- Функции критичной инфраструктуры (оплата, замки): доступны в локальном режиме.
Быстрый чек‑лист внедрения за 30 дней
Дни 1–7: инвентаризация и приоритизация.
Дни 8–14: включение офлайн‑режимов, ежедневные экспорты.
Дни 15–21: установка NAS/Nextcloud, базовая автоматизация.
Дни 22–30: симуляция инцидента, корректировка SOP, обучение команды.
Часто задаваемые вопросы
Что делать, если провайдер облака сообщает о восстановлении — как вернуться к нормальной работе?
Плавно: убедитесь в целостности данных, выполните синхронизацию изменений, затем поэтапно переключите трафик обратно, мониторя метрики.
А стоит ли полностью уходить из публичного облака?
Не обязательно. Гибридный подход даёт лучшее сочетание удобства и надёжности: используйте облако для масштабируемости и локальные решения для критичных функций.
Насколько эта стратегия дороже?
В краткосрочной перспективе есть затраты на оборудование и время настройки. Но в долгосрочной перспективе снижение простоев и потерянных транзакций обычно оправдывает расходы.
Итоги
- Сбой облака — предупреждение, а не приговор.
- Комбинация local‑first приложений, офлайн‑режимов, локального управления умным домом и гибридных резервных копий даёт реальную устойчивость.
- Начните с инвентаризации, реализуйте быстрые победы и постепенно автоматизируйте переключение и восстановление.
Примените хотя бы одну из описанных мер уже сегодня — экспорт критичных данных или простая настройка локальной копии заметок существенно снизят риск простоя.
Справочный лист (однострочный глоссарий)
- Local‑first: подход, где основная рабочая копия хранится локально и синхронизируется при соединении.
- NAS: сетевое хранилище для локальных резервных копий.
- Multi‑cloud: размещение сервисов у нескольких облачных провайдеров для снижения концентрации риска.
Похожие материалы

Herodotus: механизм и защита Android‑трояна
Включить новое меню «Пуск» в Windows 11

Панель полей сводной таблицы в Excel — руководство

Включить новое меню «Пуск» в Windows 11
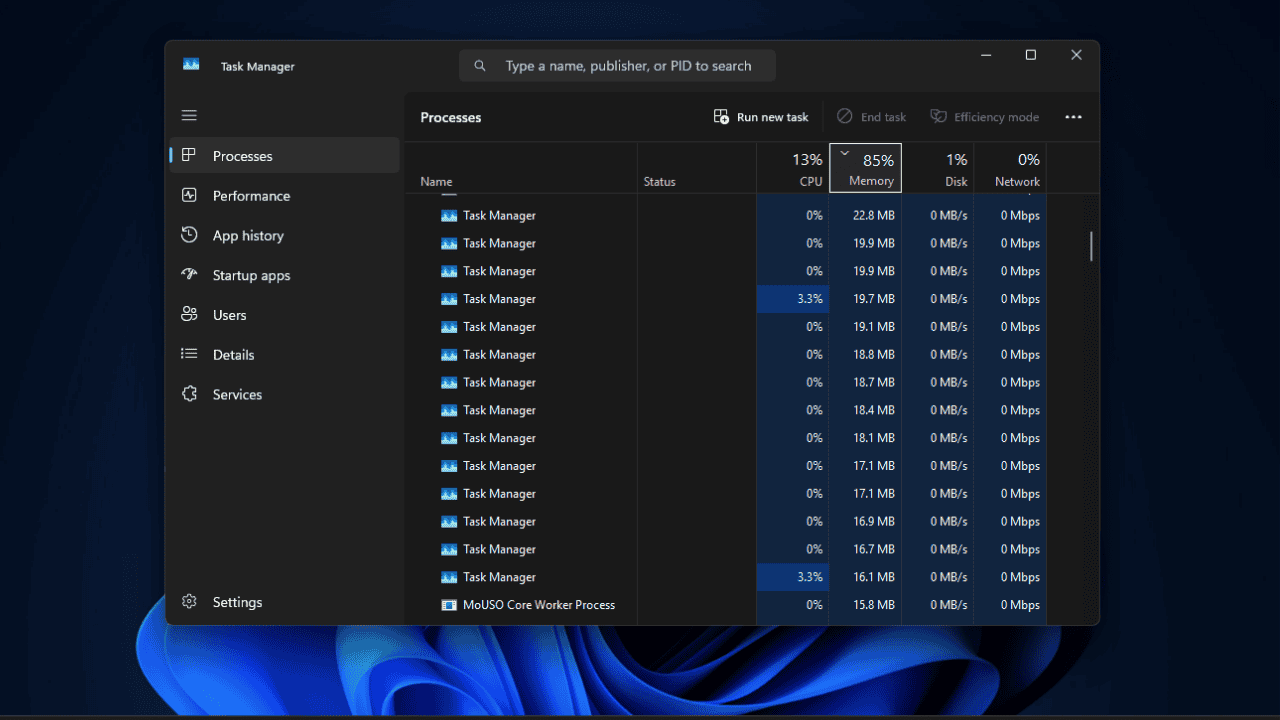
Дубликаты Диспетчера задач в Windows 11 — как исправить
