Как загрузить данные Excel в Python с помощью Pandas
Важно: в примерах предполагается установленный Python 3.x. Если вы никогда не работали с Python, начните с базового курса по Python и изучите простые примеры перед этим руководством.
Что такое Pandas
Pandas — это открытая библиотека Python для анализа и обработки табличных данных. Ключевое понятие: DataFrame — объект в виде таблицы с индексами, строками и колонками, похожий на таблицу Excel. DataFrame упрощает фильтрацию, агрегацию и преобразование данных в Python.
Короткое определение: DataFrame — табличная структура данных (строки × столбцы), полезная для анализа.
Зачем загружать Excel в Python
- Повторяемая автоматизация преобразований и отчётов.
- Возможность сложной фильтрации, объединения и статистики вне Excel.
- Подготовка данных для машинного обучения и визуализации.
Установка Pandas и окружения
Примечание: Pandas требует Python 2.7 или 3.x, но рекомендуется Python 3.7+.
Варианты установки:
- Через pip (наиболее распространённый способ):
>> pip install pandas- Через pip для NumPy (если ещё не установлен):
>> pip install numpyЧерез Anaconda (рекомендуется для аналитиков): Pandas уже включён в дистрибутив Anaconda. Anaconda управляет зависимостями и окружениями.
Через pipenv/poetry: используйте менеджер зависимостей если вы хотите изолировать проект.
Пример для создания виртуального окружения и установки через pipenv:
>> pip install pipenv
>> pipenv --python 3.10
>> pipenv install pandasПодготовка Excel-файла
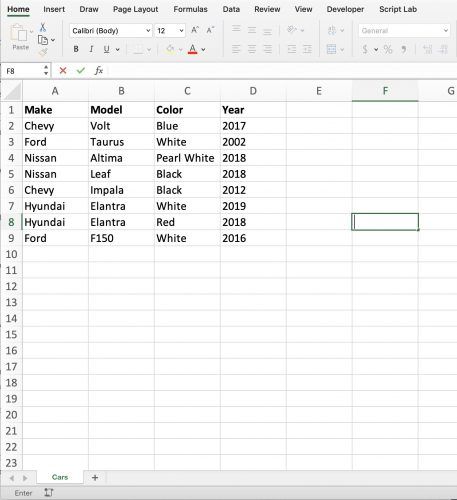
Для примера используем рабочую книгу Cars.xlsx, сохранённую на рабочем столе:
/Users/grant/Desktop/Cars.xlsxИзображение примера таблицы:
Что важно проверить перед импортом:
- Есть ли заголовок (имена столбцов) в первой строке? Если нет — нужно указать header=None и задать имена колонок вручную.
- Есть ли пустые строки/столбцы вокруг таблицы? Их лучше очистить.
- Нужны ли специфические типы (даты, числа)? Можно задать аргумент dtype или parse_dates.
- Если файл содержит несколько листов, определите, какой лист нужен (по имени или индексу).
Совет: сохраняйте файл в .xlsx. Для устаревших .xls или бинарных форматов могут потребоваться дополнительные движки.
Пишем скрипт: базовый пример
Создайте файл Script.py и импортируйте Pandas:
import pandas as pd
from pandas import ExcelFileСохраните путь к файлу в переменной:
Cars_Path = '/Users/grant/Desktop/Cars.xlsx'Прочитайте файл в DataFrame:
DF = pd.read_excel(Cars_Path)
print(DF)Запустите скрипт из терминала:
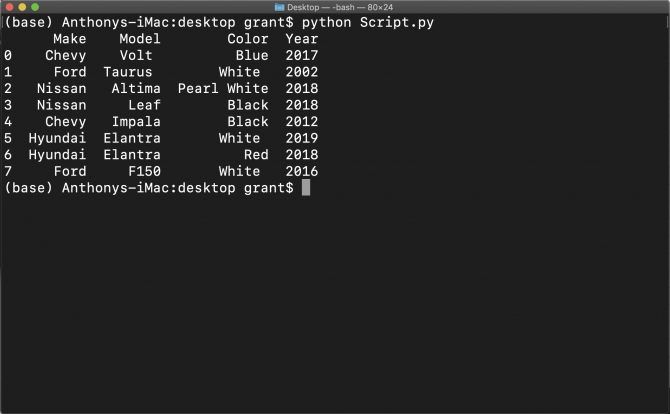
После выполнения вы увидите DataFrame в терминале:
Типичные параметры pd.read_excel и полезные опции
pandas.read_excel отвечает за чтение содержимого Excel и имеет много полезных аргументов. Ниже — шпаргалка (cheat sheet).
Основные параметры:
- io — путь к файлу, объект буфера или URL.
- sheet_name — имя листа, индекс (int), список листов или None для всех листов. По умолчанию 0 (первый лист).
- header — строка(и) с заголовками (по умолчанию 0). Если заголовка нет — header=None.
- names — список имён колонок, если вы хотите переопределить заголовки.
- index_col — колонка(ы) для индекса.
- usecols — какие колонки читать (словарь, список, диапазон строк/столбцов или строка Excel, например “A:C”).
- dtype — словарь типов колонок, например {“Year”: int}.
- parse_dates — колонки, которые нужно распознать как даты.
- na_values — дополнительные строки, которые следует считать NaN.
- engine — движок для чтения: ‘openpyxl’, ‘xlrd’ (устарел для xlsx), ‘odf’, ‘pyxlsb’. Обычно Pandas сам подберёт.
Примеры:
Чтение конкретного листа по имени:
DF = pd.read_excel(Cars_Path, sheet_name='Sheet1')Чтение нескольких листов (вернёт словарь DataFrame):
sheets = pd.read_excel(Cars_Path, sheet_name=['Sheet1', 'Sheet2'])
# sheets['Sheet1'] — DataFrame для листа Sheet1Чтение без автоматического индекса (убираем индексный столбец):
DF = pd.read_excel(Cars_Path, index_col=None)Если у вас в таблице нет заголовка и вы хотите задать свои имена колонок:
DF = pd.read_excel(Cars_Path, header=None, names=['Make', 'Model', 'Color', 'Year'])Чтение только колонок A и C (в Excel обозначении):
DF = pd.read_excel(Cars_Path, usecols='A:C')
# или по именам колонок
DF = pd.read_excel(Cars_Path, usecols=['Make', 'Year'])Задание типов и парсинг дат:
DF = pd.read_excel(Cars_Path, dtype={'Year': 'int64'}, parse_dates=['PurchaseDate'])Чтение из URL (если файл доступен по HTTP/HTTPS):
DF = pd.read_excel('https://example.com/data/Cars.xlsx')Сохранение DataFrame обратно в Excel и другие форматы
После обработки вы можете сохранить результат:
DF.to_excel('/Users/grant/Desktop/Cars_processed.xlsx', index=False)
DF.to_csv('/Users/grant/Desktop/Cars.csv', index=False)Частые ошибки и как их исправить
Ошибка с движком (Engine error): Pandas может попросить установить openpyxl или xlrd. Решение: установить пакет, например pip install openpyxl.
UnicodeDecodeError при чтении CSV: укажите encoding, например encoding=’utf-8’ или ‘cp1251’. Для Excel обычно не требуется.
Неверные типы колонок: используйте dtype или преобразуйте после чтения с помощью astype.
Проблемы с датами: укажите parse_dates и, при необходимости, dayfirst=True.
Большой файл слишком медленный: читайте по частям (chunksize) или используйте специализированные инструменты.
Отладка: проверка содержимого и структуры
После чтения используйте стандартные Pandas-методы для осмотра:
DF.head() # первые строки
DF.info() # информация о колонках и типах
DF.describe() # базовые статистики для числовых колонок
DF.columns # список колонок
DF.shape # (строки, колонки)Альтернативы и для чего они годятся
- openpyxl — работа с ячейками, форматированием, стилями (если нужен тонкий контроль над форматом Excel).
- xlrd — чтение старых .xls (ограничения для .xlsx в новых версиях). Сейчас xlrd больше не поддерживает .xlsx.
- xlwings — интеграция с запущенным Excel, полезно для взаимодействия с пользователем и автоматизации тонн Excel-скриптов.
- pyxlsb — чтение бинарных .xlsb файлов.
- CSV — иногда проще сохранить Excel в CSV и читать его, если нет нескольких листов или форматирования.
Когда Pandas подходит лучше: массовая обработка и анализ. Когда Pandas не подходит: если требуется работа с форматированием и стилями Excel.
Советы по производительности
- Используйте usecols, чтобы читать только нужные столбцы.
- Для очень больших файлов используйте chunking через pd.read_csv с chunksize; для Excel chunking нет прямого аргумента, поэтому конвертируйте в CSV, если возможно.
- Указывайте dtype, чтобы избежать затрат на автоматическое определение типов.
- Если файл повторно читается в нескольких скриптах, сохраняйте промежуточные результаты в Feather, Parquet или HDF5 для быстрого загрузки.
Безопасность и приватность
- Не загружайте в скрипт пароли или приватные ключи. Обрабатывайте конфиденциальные данные в безопасной среде.
- Если файл находится в общем доступе (облачное хранилище), проверьте права доступа перед публикацией результатов.
- Удаляйте временные файлы после завершения обработки, если они содержат чувствительную информацию.
Совместимость и движки
Короткая матрица совместимости:
- .xlsx: openpyxl (рекомендуется)
- .xls: xlrd (старые форматы)
- .xlsb: pyxlsb
- .ods: odf
Если Pandas жалуется на «Engine» — обычно нужно установить соответствующую зависимость: pip install openpyxl или pip install pyxlsb.
Роль-базовые чек-листы
Для аналитика данных:
- Убедиться, что заголовки корректны.
- Прописать usecols и parse_dates.
- Проверить пропуски и уникальные значения.
Для инженера данных:
- Автоматизировать загрузку (cron, Airflow или CI).
- Проверять контроль качества и тесты на целостность.
- Сохранять вывод в сжатые форматы (Parquet).
Для начинающего:
- Начать с простого pd.read_excel и изучить DF.head(), DF.info().
- Экспериментально менять аргументы read_excel.
Критерии приёмки
- Скрипт корректно загружает основной лист и возвращает DataFrame без ошибок.
- Форматы дат и чисел распознаны корректно или явно приведены через dtype/parse_dates.
- Файл сохраняется в нужный формат (если требуется) и доступен следующему шагу пайплайна.
Примеры расширенного использования
Чтение диапазона конкретных колонок и парсинг дат:
DF = pd.read_excel(Cars_Path, usecols=['Make','Model','Year','PurchaseDate'], parse_dates=['PurchaseDate'])Чтение всех листов и объединение в один DataFrame:
sheets = pd.read_excel(Cars_Path, sheet_name=None) # вернёт dict
combined = pd.concat(sheets.values(), ignore_index=True)Обработка пропусков и базовая очистка:
DF = DF.dropna(subset=['Make','Model']) # удалить строки без марки или модели
DF['Year'] = DF['Year'].fillna(0).astype(int)Мини-методология для проекта
- Подготовить файл Excel: очистить служебные строки, установить заголовок.
- Создать виртуальное окружение и установить зависимости.
- Написать скрипт с pd.read_excel и базовой валидацией (DF.info(), проверки на пустые значения).
- Добавить логирование и тесты (например, assert DF.shape[0] > 0).
- Прописать шаг сохранения в более быстром бинарном формате, если планируется повторное чтение.
Тестовые кейсы и приёмка
- Ожидаемый результат: DataFrame содержит N строк и M колонок.
- Тест: при чтении файла с заголовком DF.columns совпадают с ожидаемым списком колонок.
- Тест: для столбца Year все значения являются целыми числами.
Короткая шпаргалка (cheat sheet)
- Чтение файла: pd.read_excel(path)
- Лист по имени: sheet_name=’Name’
- Только колонки: usecols=[‘A’,’B’] или ‘A:C’
- Без индекса: index_col=None
- Сохранить: DF.to_excel(path, index=False)
Часто задаваемые вопросы
Как установить Pandas?
Установите через pip: pip install pandas или используйте Anaconda.
Что такое DataFrame?
DataFrame — табличная структура данных с индексами, строками и столбцами для анализа.
Как убрать индекс, который Pandas добавляет по умолчанию?
При записи в Excel используйте index=False или при чтении не указывайте index_col.
Короткое руководство по отладке
- Выполните DF.head() и DF.info().
- Если колонки не прочитались — проверьте header и names.
- При ошибке движка — установите openpyxl или соответствующий пакет.
Заключение
Pandas — удобный инструмент для переноса данных из Excel в среду программирования. С него удобно начинать автоматизацию отчётов, очистку данных и подготовку к анализу. Освоив базовые параметры read_excel и методы проверки содержимого, вы сможете быстро и надёжно переносить табличные данные в рабочие скрипты.
Image Credit: Rawpixel/ Depositphotos
Похожие материалы

Несколько аккаунтов Skype: Multi Skype Launcher

Журнал для работы: повысить продуктивность

Персональные звуки уведомлений на Android

Скачивание шоу Hulu для офлайн‑просмотра

Microsoft Start: персонализированная новостная лента
