개요
SMART(자체 모니터링, 분석 및 보고 기술)는 최신 하드디스크와 SSD에 내장된 기능으로, 디스크의 다양한 상태를 측정해 임박한 장애를 예측할 수 있게 합니다. smartmontools는 이 SMART 속성을 조회하고 테스트하는 오픈소스 도구 집합입니다. 관리자가 smartmontools를 사용하면 조기 경고를 받아 백업과 디스크 교체를 준비할 시간을 벌 수 있습니다.
핵심 용어 1줄 정의
- SMART: 디스크 내부 센서와 카운터를 통해 상태를 추적하는 표준 기술입니다.
- smartctl: SMART 데이터를 수동으로 조회·제어하는 도구입니다.
- smartd: 백그라운드에서 주기적으로 SMART 진단을 수집하고 알림을 보내는 데몬입니다.
설치
Debian/Ubuntu 계열에서는 기본 저장소에서 설치할 수 있습니다.
sudo apt-get update
sudo apt-get install smartmontoolsFedora 계열에서는 다음을 사용합니다.
sudo yum install smartmontools설치하면 두 가지 주요 프로그램이 시스템에 추가됩니다:
- smartctl: 상호작용형으로 수동 검사 및 제어
- smartd: 백그라운드에서 주기적으로 SMART를 체크하고 알림을 보내는 데몬
Important: 패키지 설치 후에는 smartctl/smartd가 디스크 장치 파일(예: /dev/sda)을 정확히 가리키는지 확인하세요. 가상화 환경이나 외장 케이스에서는 -d 옵션으로 장치 타입을 지정해야 할 수 있습니다.
smartctl 사용법
smartctl은 루트 권한이 필요합니다. 파티션이 아니라 전체 디스크 장치(예: /dev/sda)를 인수로 줘야 합니다. 이 문서 예제는 /dev/sda를 사용하므로, 실제 환경에 맞는 장치 파일로 바꿔 사용하세요.
디스크 정보 보기:
sudo smartctl -i /dev/sda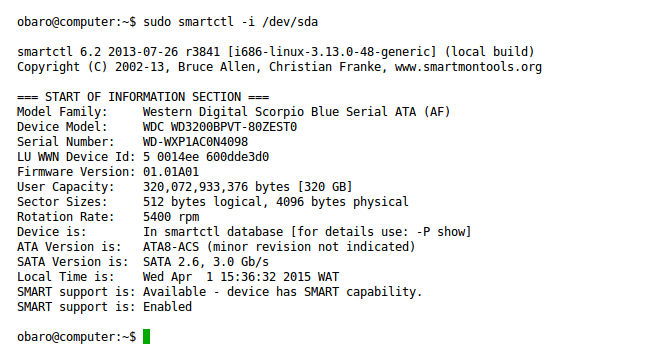
위 출력에서 SMART가 “Available” 그리고 “Enabled”로 표시되면 준비된 상태입니다. 만약 Available이지만 Enabled가 아니라면 아래 명령으로 활성화합니다:
sudo smartctl -s on /dev/sda디스크의 건강 상태 확인:
sudo smartctl -H /dev/sda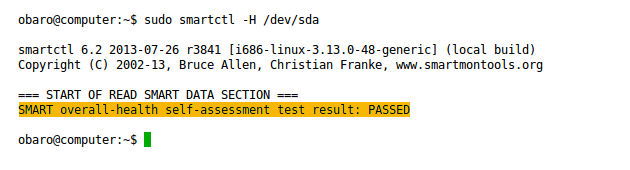
출력이 PASSED가 아니라면 디스크가 실패했거나 실패를 예측하고 있는 것입니다. 즉시 중요한 데이터를 백업하세요.
SMART 기능과 셀프테스트 정보 보기:
sudo smartctl -c /dev/sda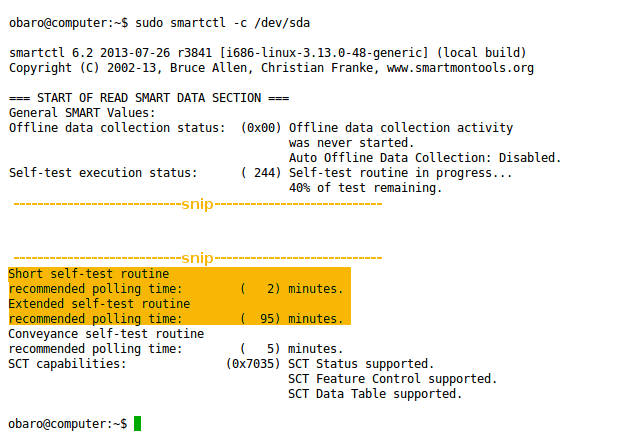
위 예시에서 단기 테스트(short)는 약 2분, 장기 테스트(long)는 약 95분으로 예상됩니다. 단기 테스트는 빠르게 주요 항목을 검사하고, 장기 테스트는 더 철저하게 검사합니다.
단기 테스트 실행:
sudo smartctl -t short /dev/sda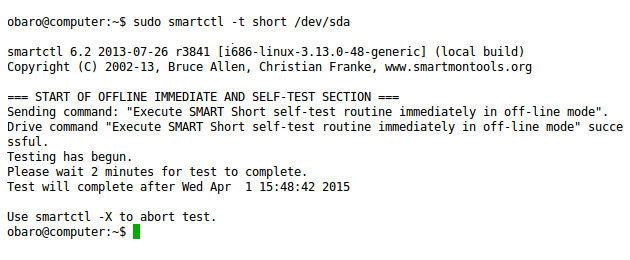
테스트는 백그라운드에서 실행되므로 다른 작업을 계속할 수 있습니다. 테스트 결과 확인:
sudo smartctl -l selftest /dev/sda이 명령은 마지막 20개의 셀프테스트 결과를 보여줍니다. 현재 진행 중인 테스트 여부는 이 리스트에서 알기 어렵습니다. 현재 상태를 확인하려면 smartctl -c나 -H로 상태를 다시 확인하거나 /proc/partitions, iostat 등으로 디바이스 활동을 모니터링하세요.
장기 테스트 실행:
sudo smartctl -t long /dev/sda테스트가 실패하면 즉시 백업하고 교체를 계획하세요.
주요 SMART 속성 해석 힌트
- Reallocated_Sector_Ct: 재할당된 섹터 수. 값 증가 시 주의.
- Current_Pending_Sector: 복구를 기다리는 섹터 수. 0이 아니면 위험 신호.
- Offline_Uncorrectable: 오프라인에서 복구할 수 없는 섹터 수.
- UDMA_CRC_Error_Count: 케이블/물리적 연결 문제의 징후일 수 있음.
smartd 구성 및 자동화
smartd는 장시간 운영 환경에서 필수적입니다. /etc/smartd.conf 파일에서 모니터 대상과 알림 정책을 설정합니다.
- /etc/smartd.conf 열기
- DEVICESCAN으로 자동 스캔하게 설정된 줄이 있다면 주석(#) 처리
- 모니터할 각 디스크마다 명시적으로 한 줄 추가
예시 라인:
/dev/sda -a -o on -S on -s (S/../.././02|L/../../6/03) -m root -M exec /usr/share/smartmontools/smartd-runner옵션 설명:
- /dev/sda: 모니터할 디바이스 파일
- -a: 일반적으로 사용되는 옵션을 모두 활성화
- -d sat: 필요하면 디바이스 타입을 지정(예: sat, ata, scsi)
- -o on: SMART 자동 오프라인 테스트 활성화
- -S on: SMART autosave 활성화
- -s (S/../.././02|L/../../6/03): 단기 테스트 매일 02:00, 장기 테스트 매주 토요일 03:00 스케줄
- -m root: 문제 발생 시 메일 발송 대상
- -M exec /usr/share/smartmontools/smartd-runner: -m 동작을 보완하는 스크립트 호출(Debian/Ubuntu 특화)
Notes: -m 옵션이 작동하려면 시스템 메일을 보내는 MTA가 구성되어 있어야 합니다. 별도의 모니터링 시스템(예: Zabbix, Prometheus+Alertmanager)과 연동하는 것을 권장합니다.
데몬 시작 및 자동시작 등록
Debian/Ubuntu에서는 /etc/default/smartmontools 파일을 열어 start_smartd=yes 행의 주석을 제거합니다. 그 후 데몬을 시작하거나 재시작합니다:
sudo /etc/init.d/smartmontools start
sudo /etc/init.d/smartmontools restart데몬은 진단 로그를 syslog에 남기며 오류 발생 시 이메일을 보냅니다. 이메일 테스트를 하고 싶다면 스마트 설정 라인에 -M test를 추가하고 재시작하세요.
실전 운영 체크리스트 (역할별)
시스템 관리자 체크리스트
- 설치: smartmontools가 최신인지 확인
- 권한: smartctl/smartd가 루트 권한으로 동작하는지 확인
- 장치 식별: RAID/가상장치 환경에서 올바른 -d 옵션 사용
- 알림: MTA 또는 외부 모니터링과 연동
- 일정: 정기적인 단기/장기 테스트 스케줄 설정
- 기록: syslog 및 별도 저장소로 SMART 이벤트 보관
데스크톱 사용자의 최소 체크리스트
- 주기적 수동 검사: 한 달에 한 번 smartctl -H 실행
- 중요 데이터는 항상 외부 백업 또는 클라우드에 보관
- UDMA CRC 오류가 반복되면 케이블/포트 점검
응급 대응자 체크리스트
- SMART 경보 수신 시 즉시 백업
- chkdsk/fsck로 파일시스템 정합성 확인(읽기 전용으로 마운트 후 복구)
- 불량 섹터가 있으면 디스크 교체 계획 수립
표준 운영 절차(SOP) 요약
- 알림 수신: smartd 또는 모니터링 시스템으로부터 경보 수신
- 즉시 백업: 빠른 전체 백업(증분/전체 전략에 따라)
- 로그 수집: smartctl -a /dev/sdX 출력 저장
- 진단: 재할당 섹터, pending 섹터, CRC 에러 확인
- 결정: 디스크 교체 필요 여부 판단
- 교체 및 복원: 새 디스크로 교체하고 데이터 복원
- 검증: RAID 리빌드, 파일시스템 체크 후 정상 서비스 복귀
간단한 실행 예시(진단 로그 수집):
sudo smartctl -a /dev/sda > ~/smartlog-$(date +%F).txt테스트 케이스 및 수용 기준
설정 확인
- 스마트 지원: smartctl -i /dev/sdX에서 SMART가 Available 및 Enabled로 표시되어야 함
- 데몬 실행: systemctl status smartd 또는 /etc/init.d/smartmontools 상태가 활성화되어 있어야 함
알림 확인
- -m 대상에 대해 테스트 메일이 성공적으로 전송되어야 함
- syslog에 smartd 관련 이벤트가 기록되어야 함
셀프테스트
- -t short가 정상 시작되고, -l selftest에 결과가 기록되어야 함
- -t long가 예약대로 실행되어야 함(예: 주간 스케줄)
수용 기준
- 모든 모니터 대상이 7일 동안 경고 없이 정상일 것
- 경고 발생 시 24시간 이내에 백업/대체 계획이 실행될 것
대안 및 언제 smartmontools가 적합하지 않은가
대안
- 제조사 전용 툴: 일부 제조사는 더 많은 제조사별 속성 및 펌웨어 진단을 제공
- 상용 제품: DriveDx(맥), Data Lifeguard Diagnostic 등 GUI 기반 상용 툴
- 중앙 모니터링: Zabbix, Nagios, Prometheus와 통합해 장기 추세를 모니터링
적합하지 않은 경우
- 하드웨어 RAID 컨트롤러 뒤에 숨겨진 물리 드라이브: 컨트롤러가 SMART를 통과시키지 않으면 smartmontools만으로는 충분한 정보 획득 불가
- 일부 USB-외장 가변 케이스: USB-브리지가 SMART 명령을 통과시키지 못할 수 있음
- 완전한 예측은 불가능: SMART는 예측도를 높여주지만 모든 고장을 포착하지는 못함
운영 시 유용한 정신 모델(heuristics)
- ‘빠른 증가‘ 모델: 재할당 섹터 수가 급격히 늘면 즉시 우선순위 높은 조치
- ‘pending 섹터 + 리할당 증가‘ 모델: 데이터 무결성 위험, 즉시 백업
- ‘CRC 에러 반복’ 모델: 물리적 연결(케이블/포트) 문제 우선점검
보안·프라이버시 주의사항
- smartd가 보내는 로그/메일은 민감한 정보(장치 모델, 시리얼 등)를 포함하므로 접근 권한을 제한하세요.
- 원격으로 알림을 보낼 때는 전송 경로와 수신자를 신뢰할 수 있도록 구성합니다.
사실 상자
- 단기 테스트 예시 시간: 약 2분
- 장기 테스트 예시 시간: 약 95분
- smartd는 자동 백그라운드 검사와 알림을 통해 관리자의 대응 시간을 벌어줍니다
문제 발생 시 의사결정 흐름 (간단한 플로우)
flowchart TD
A[SMART 경고 수신] --> B{현재 백업이 있는가}
B -- 예 --> C[저장소 무결성 검사]
B -- 아니오 --> D[즉시 백업]
C --> E{재할당/대기 섹터가 증가했는가}
D --> E
E -- 예 --> F[디스크 교체 계획 수립]
E -- 아니오 --> G[모니터링 강화]
F --> H[교체 후 데이터 복원 및 검증]
G --> I[주기적 보고서 생성]마무리 요약
SMART와 smartmontools는 하드디스크 장애를 완벽히 예측할 수는 없지만 중요한 조기 경보를 제공합니다. smartctl로 수동 검사를 수행하고 smartd로 자동 모니터링 및 알림을 설정해 데이터 손실 위험을 줄이세요. 가장 중요한 방어선은 여전히 잘 설계된 백업 전략입니다.
Important: SMART 경고는 즉시 행동을 요구하는 신호입니다. 경고를 무시하면 돌이킬 수 없는 데이터 손실이 발생할 수 있습니다.
끝요약
- smartmontools는 무료 도구로 SMART 정보를 조회하고 테스트합니다.
- smartctl은 수동 검사, smartd는 자동 모니터링과 알림 담당입니다.
- SMART 속성(재할당, pending, CRC 등)을 정기적으로 확인하고 알림을 구성하세요.
- SMART는 백업을 대신하지 못하므로 백업 전략을 최우선으로 하세요.



