

ジャンプリンク
pandasとは何か
DataFrameとは何か
DataFrameの作成方法
DataFrameの読み込み
DataFrameの調査方法
列の追加と削除
列に対する演算
データをPythonで分析するなら、pandasに慣れると作業が大幅に楽になります。DataFrameはpandasで最もよく使われるデータ形式です。以下では実際に手を動かしながら基本を学びます。
pandasとは何か

pandasはデータサイエンスやデータ分析で広く使われるPythonのライブラリです。表形式データ(行と列)をDataFrameという構造で管理し、読み込み、集計、加工、可視化に便利な多くのメソッドを提供します。簡単に言えば「データを表で扱うためのツールボックス」です。
用語定義(ワンライン): DataFrame — 行と列を持つ2次元の表形式データ構造。
インストールはPyPIから:
pip install pandasJupyter NotebookやJupyterLab、あるいはインタラクティブなIPython環境で使うと便利です。ノートブックは計算過程を保存できるので、数日後に作業を振り返るときに役立ちます。記事中の例とスクリーンショットは著者のノートブックからのものです。
DataFrameとは何か
DataFrameはスプレッドシートや関係データベースのテーブルに似ています。列ごとに名前(ヘッダー)があり、数値・文字列・時系列などの多様な型を混在させられます。R言語のdata.frameと概念が近く、統計解析/可視化ライブラリと組み合わせて使われます。
DataFrameの特徴(簡潔):
- インデックス(行ラベル)とカラムラベルを持つ
- 異なる列で異なるデータ型を許容する
- NumPy配列と親和性が高く、高速なベクトル演算が可能
DataFrameの作成方法
まずNumPyで独立変数(x)を作り、それを使って線形関係の従属変数(y)を作ります。その後pandasでDataFrameを組み立てます。
import numpy as np
x = np.linspace(-10, 10)
y = 2 * x + 5
import pandas as pd
# x, y配列を渡してDataFrameを作成
df = pd.DataFrame({'x': x, 'y': y})ポイント:
- pandasをpdと略すのは標準的な慣習で可読性が上がります。
- DataFrameは辞書(列名: 値リスト/配列)を渡すことで簡単に作れます。
別の作成例:リストや辞書、ネストした辞書
# リストのリストから
data = [['Alice', 30], ['Bob', 25]]
df2 = pd.DataFrame(data, columns=['Name', 'Age'])
# 辞書から
data_dict = {'Name': ['Alice', 'Bob'], 'Age': [30, 25]}
df3 = pd.DataFrame(data_dict)DataFrameの読み込み
現実の分析ではファイルから読み込むことが多いです。代表的な読み込み例を示します。
# Excel
df = pd.read_excel('/path/to/spreadsheet.xls')
# CSV
df = pd.read_csv('/path/to/data.csv')
# クリップボードから(小さな表のコピー&ペーストに便利)
df = pd.read_clipboard()備考: LibreOffice CalcなどでもCSVでエクスポートしてやり取りできます。
DataFrameの調査方法
データを読み込んだらまず中身を調べます。代表的なメソッドを説明します。
# 先頭5行(デフォルト)
df.head()
# 末尾5行
df.tail()
# 先頭n行
df.head(10)
# 行のスライス(Pythonのスライスを使う)
df[1:3]
# 全カラム名を確認
df.columns
# 数値列の要約統計量
df.describe()
説明: describe()は平均、標準偏差、最小値、25パーセンタイル、中央値(50パーセンタイル)、75パーセンタイル、最大値を示します。これは統計家ジョン・タッキーの「five-number summary」に相当する指標を含みます。
列の抽出と表示設定
列は角括弧で抽出します。
# 'Name'列だけを見る
df['Name']
# 長い出力を全部表示したいとき
pd.set_option('display.max_rows', None)
# ひとつの列の統計情報
df['Age'].describe()
# 列の平均や中央値
df['Age'].mean()
df['Age'].median()
列の追加と削除
列は簡単に追加できます。列全体に演算を適用して新しい列に代入するだけです。
# x列の値を二乗する例
df['x2'] = df['x'] ** 2
# 追加後に削除するには
df = df.drop('x2', axis=1) # axis=1は列操作を示す注意:
- dropはデフォルトで新しいDataFrameを返します(inplace=False)。元のDataFrameを更新したければ df.drop(‘x2’, axis=1, inplace=True) を使うか、戻り値を代入してください。

列に対する演算
列同士の演算はベクトル化され高速に実行されます。
# 列同士の足し算(要素ごと)
df['x'] + df['y']
# 複数列の選択(2重角括弧)
df[['x', 'y']]Titanicデータセットを例に、特定の列を選んだり条件で抽出したりできます。
# NameとAgeだけ選ぶ
titanic[['Name', 'Age']]
# 年齢が30歳より大きい行を選ぶ
titanic[titanic['Age'] > 30]
# locを使った選択(行の条件と列選択を組み合わせられる)
titanic.loc[titanic['Age'] > 30]これはSQLの次のクエリに相当します:
SELECT * FROM titanic WHERE Age > 30
集計・カウントと可視化の例
乗船港ごとの人数を集計して棒グラフを作る例を示します。
embarked = titanic['Embarked'].value_counts()
# 値ラベルを置換
embarked = embarked.rename({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'})
# 棒グラフを描く
embarked.plot(kind='bar')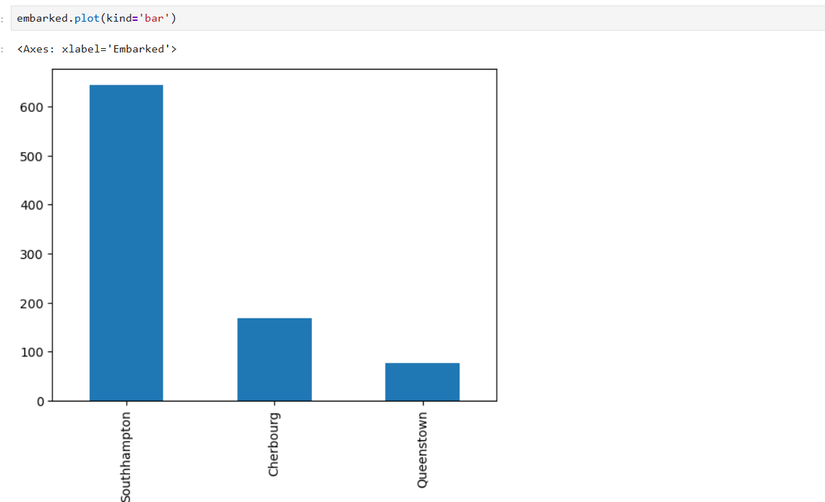
実践的なワークフロー(ミニメソッド)
典型的なデータ分析の流れを数ステップで示します。実務で毎回これらを確認すると品質が安定します。
- データの読み込み: read_csv / read_excel / read_sql など
- 概要確認: head(), info(), describe(), columns
- 前処理: 欠損値処理(dropna, fillna)、型変換(astype)
- 加工: 新規列作成、フィルタリング、グルーピング(groupby)
- 検証: 可視化、統計量の確認
- 保存: to_csv, to_excel
例:
# 欠損値を中央値で補完
titanic['Age'] = titanic['Age'].fillna(titanic['Age'].median())
# グループごとの生存率を計算
survival_by_class = titanic.groupby('Pclass')['Survived'].mean()よくある問題と対処
- 大きなファイルでメモリ不足になる: DaskやVaexといったアウトオブコア(ディスク主体)ライブラリを検討する。
- 列名に空白や特殊文字がある: 事前にrenameやcolumns属性で正規化する。
- 日付の扱い: parse_dates引数やpd.to_datetimeで明示的に変換する。
代替アプローチと適用シーン
- 小規模データや数値計算中心: NumPy配列の方がシンプルで高速な場合がある。
- 大量データ(数GB〜TB): Dask, PySpark, Vaexを検討。
- SQLと連携: データベースで集約・フィルタを行い、結果をpandasでロードして可視化・分析するハイブリッドが効率的。
パフォーマンスのヒント
- 可能な限りベクトル化演算を使う(forループを避ける)。
- 型を最適化(例えばint64をint32にするなど)してメモリ削減。
- カテゴリ型(category)を利用してメモリと速度を改善。
- 必要な列だけ読み込む(usecols引数)。
セキュリティとプライバシーの注意点
- 個人データ(氏名、メール、IDなど)を扱う場合、GDPRや国内の個人情報保護法に従い匿名化や最小化を行う。
- ログやスナップショットを共有する前に個人情報を削除する。
- クラウドにデータをアップロードする場合は保存先のアクセス制御と暗号化を確認する。
役割別チェックリスト
データサイエンティスト:
- データの理解(head, info, describe)
- 欠損値と外れ値の処理
- 再現可能なノートブック作成
データアナリスト:
- KPIに必要な列を抽出
- 集計と可視化
- レポートのためのクリーニング
エンジニア:
- ETLパイプラインへの組み込み
- 大容量データの効率的な読み込み
- 型とメモリの最適化
テストケースと受け入れ基準
- 読み込み: ファイルを読み込んで行数とカラム数が既知の値と一致すること。
- 欠損値処理: 指定したカラムの欠損値がすべて補完されていること。
- 型変換: 数値カラムが数値型に変換され、計算がエラーなく実行されること。
小さな用語集(1行ずつ)
- DataFrame: 行と列で表現される2次元データ構造。
- Series: 単一の列に対応する1次元の配列ライクなオブジェクト。
- ベクトル化: 配列全体に対して要素ごとの演算を一度に行うこと。
- groupby: 指定したキーで集約処理を行う操作。
よくある失敗例と回避策
失敗例: CSVを読み込んだら日付が文字列として扱われ、日付演算が出来ない。 回避策: read_csvのparse_dates引数やpd.to_datetimeで明示的に変換する。
失敗例: メモリ不足で処理が止まる。 回避策: usecolsで必要な列だけ読み込む、dtypeを最適化する、またはDaskの導入を検討する。
追加の参考ワークフロー(簡易プレイブック)
- データソースを確認(CSV/Excel/DB/API)
- 取得/ダウンロード
- pd.read_*で読み込み(必要ならparse_dates, dtype, usecolsを指定)
- info(), head(), describe()で概要確認
- 欠損値と型を整理
- 必要な集計と可視化を実行
- 結果をCSV/Excel/データベースに保存
まとめ
- pandasのDataFrameは、Pythonで表形式データを扱う中心的なツールです。
- 読み込み、調査、前処理、集計、可視化の一連の操作が揃っているため、探索的データ分析に向いています。
- 大規模データやメモリ制約がある場合は、DaskやVaexなどの代替を検討してください。
重要: 実際のデータを扱う際は、個人情報保護や保存先のセキュリティを常に意識してください。
この記事がpandasでのDataFrame入門に役立つことを願っています。pandasは統計家やデータサイエンティスト、アナリストにとって非常に強力なツールであり、Pythonがデータ処理分野で人気を持つ理由の一つです。



