Introduction à pandas et aux DataFrames en Python

Liens rapides
Qu’est-ce que pandas ?
Qu’est-ce qu’un DataFrame ?
Comment créer un DataFrame
Importer un DataFrame
Examiner un DataFrame
Ajouter et supprimer des colonnes
Effectuer des opérations sur les colonnes

Si vous souhaitez analyser des données en Python, il est utile de connaître pandas. Cette bibliothèque simplifie grandement l’analyse tabulaire. Le DataFrame est le format principal que vous manipulerez. Ce guide explique comment l’utiliser efficacement.
Qu’est-ce que pandas ?

pandas est une bibliothèque Python très utilisée en science des données et en analyse. Elle organise les données en structures appelées DataFrames et propose de nombreuses opérations pour transformer, résumer et nettoyer ces données. pandas a été créé au sein de la finance quantitative puis open-source au cours des années 2000.
Installation via PyPI :
pip install pandasConseil pratique : travaillez avec Jupyter Notebook ou un autre environnement interactif. Jupyter conserve un historique de vos cellules et facilite la réexécution et la documentation de vos analyses. Pour des explorations rapides en terminal, IPython convient aussi.
Qu’est-ce qu’un DataFrame ?
Un DataFrame est la structure tabulaire de pandas. Il ressemble à une feuille de calcul ou à une table relationnelle : lignes et colonnes. Chaque colonne a un nom (en-tête). On peut y stocker du texte, des entiers, des flottants et des séries temporelles. Le concept est comparable aux data frames en R.
Définition courte : un DataFrame = table à deux dimensions (index de lignes + colonnes nommées).
Comment créer un DataFrame
Vous pouvez construire un DataFrame à partir de listes, dictionnaires ou tableaux NumPy. Voici un exemple pas à pas.
Créer un axe x avec NumPy :
import numpy as np
x = np.linspace(-10, 10)Créer une variable dépendante y (fonction linéaire simple) :
y = 2 * x + 5Importer pandas (raccourci usuel) :
import pandas as pdConstruire le DataFrame :
df = pd.DataFrame({'x': x, 'y': y})Astuce : utiliser des noms courts comme pd et np est la convention. Cela rend le code plus lisible et plus concis.
Exemple minimal
import numpy as np
import pandas as pd
x = np.linspace(-10, 10)
y = 2 * x + 5
df = pd.DataFrame({'x': x, 'y': y})
print(df.head())Importer un DataFrame depuis des fichiers
Plus souvent, vous importerez des données depuis un fichier. pandas lit les formats tabulaires courants : CSV, Excel, clipboard, SQL, JSON, etc.
Lire un fichier Excel :
df = pd.read_excel('/path/to/spreadsheet.xls')Lire un CSV :
df = pd.read_csv('/path/to/data.csv')Coller depuis le presse-papiers (pratique pour petits jeux de données) :
df = pd.read_clipboard()Note : pandas détecte souvent l’encodage et le séparateur, mais pour des fichiers étrangers, précisez encoding=’utf-8’ ou sep=’;’.
Examiner un DataFrame
Une fois le DataFrame chargé, inspectez sa forme et son contenu.
Obtenir les premières lignes :
df.head()
Obtenir les dernières lignes :
df.tail()
Slicing par index (exclut l’index de fin) :
df[1:3]
Afficher un nombre précis de lignes :
df.head(10)
Exemple avec un dataset public (Titanic)
Le dataset Titanic est souvent utilisé pour des démonstrations. Après l’avoir téléchargé :
titanic = pd.read_csv('data/Titanic-Dataset.csv')
titanic.head()
Lister les colonnes :
titanic.columnspandas propose aussi des méthodes d’information :
titanic.info()Statistiques descriptives sur les colonnes numériques :
titanic.describe()
Définitions rapides :
- mean : moyenne arithmétique.
- std : écart type.
- 25%, 50%, 75% : quartiles.
Accéder à une colonne par nom :
titanic['Name']
Pour voir la colonne entière sans troncature :
pd.set_option('display.max_rows', None)
print(titanic['Name'].to_string())Obtenir des statistiques sur une seule colonne :
titanic['Age'].describe()
Moyenne et médiane :
titanic['Age'].mean()
titanic['Age'].median()
Ajouter et supprimer des colonnes
Vous pouvez créer de nouvelles colonnes à partir d’opérations sur des colonnes existantes.
Par exemple, élever au carré la colonne x :
df['x'] 2
Ajouter la nouvelle colonne :
df['x2'] = df['x']2
Supprimer une colonne :
df = df.drop('x2', axis=1)Important : axis=1 signifie que l’opération s’applique aux colonnes. Sans réaffecter le résultat à df (ou sans utiliser inplace=True), drop ne modifie pas le DataFrame existant.
Effectuer des opérations sur des colonnes
Vous pouvez réaliser des opérations arithmétiques et logiques sur les colonnes.
Additionner x et y :
df['x'] + df['y']
Sélectionner plusieurs colonnes (double crochets) :
titanic[['Name', 'Age']]
Filtrer avec une condition booléenne (similaire à WHERE en SQL) :
titanic[titanic['Age'] > 30]
Équivalent SQL :
SELECT * FROM titanic WHERE Age > 30Sélectionner avec loc (étiquettes) :
titanic.loc[titanic['Age'] > 30]
Exemple de visualisation : ports d’embarquement
Compter les valeurs d’une colonne :
embarked = titanic['Embarked'].value_counts()Remplacer les abréviations par les noms complets :
embarked = embarked.rename({'S': 'Southampton', 'C': 'Cherbourg', 'Q': 'Queenstown'})Tracer un diagramme en barres :
embarked.plot(kind='bar')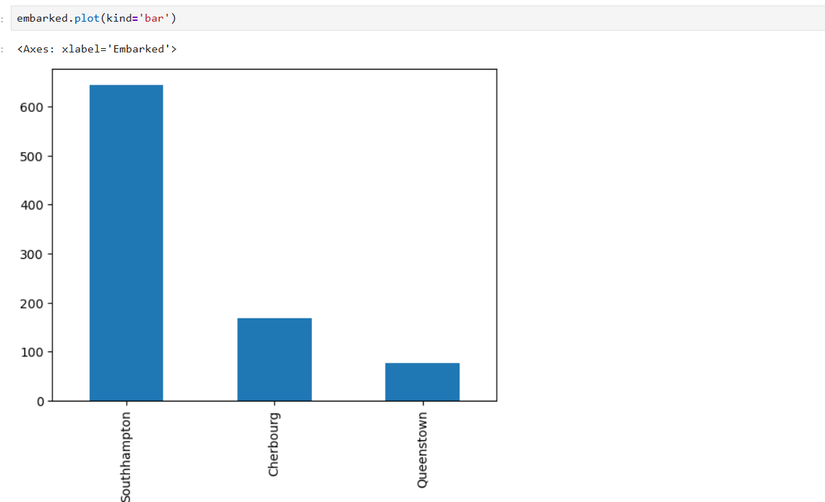
Bonnes pratiques et pièges courants
Important : pandas fonctionne en mémoire. Pour des datasets très volumineux (plusieurs dizaines de Go), préférez des outils spéciaux (Dask, Polars, bases de données, ou traitement par lots).
Notes :
- Toujours vérifier les types (dtypes) : pd.DataFrame.dtypes.
- Gérer les valeurs manquantes : isna(), dropna(), fillna().
- Pour des opérations groupées, utilisez groupby().
- Évitez les boucles Python sur chaque ligne : utilisez les opérations vectorisées.
Alternatives et quand les choisir
- Dask : si vos données dépassent la mémoire et que vous souhaitez une API proche de pandas pour le parallélisme.
- Polars : API inspirée de pandas mais conçue pour la performance et la faible consommation mémoire.
- SQL / bases de données relationnelles : pour des jointures lourdes et des requêtes optimisées.
Modèles mentaux et heuristiques rapides
- DataFrame = table en mémoire. Si ça tient en RAM, pandas est souvent la solution la plus simple.
- Vectorisation > boucles : appliquez une opération sur la colonne entière plutôt que parcourir ligne par ligne.
- Nettoyage d’abord : identifiez types et valeurs manquantes avant l’analyse statistique.
Boîte à outils rapide (cheat sheet)
- Chargement : read_csv, read_excel, read_sql
- Inspection : head(), tail(), info(), describe(), shape
- Indexation : [], .loc, .iloc
- Transformation : assign, apply (prend du temps), map, replace
- Agrégation : groupby().agg()
- Fusion : merge, concat
- Export : to_csv, to_excel
Checklist rapide avant l’analyse
- Vérifier l’encodage et le séparateur du fichier.
- Vérifier les dtypes : df.dtypes.
- Repérer valeurs manquantes : df.isna().sum().
- Nettoyer / normaliser les colonnes (dates, catégories).
- Indexer si nécessaire pour accélérer les jointures.
- Échantillonner pour les tests rapides.
Playbook d’analyse exploratoire (SOP minimal)
- Charger les données et sauvegarder une copie stricte : raw = df.copy()
- Exécuter df.info() et df.describe()
- Vérifier les clés uniques et les duplicatas : df.duplicated().sum()
- Traiter les valeurs manquantes selon le contexte (drop, fill)
- Convertir les colonnes de dates : pd.to_datetime()
- Visualiser distributions (histogrammes), relations (scatter), proportions (bar)
- Enregistrer le notebook et les visualisations
Cas d’usage / Tests d’acceptation simples
- Test 1 : read_csv lit le fichier et df.shape renvoie (>0, >0).
- Test 2 : Après to_datetime, la colonne date a dtype datetime64[ns].
- Test 3 : groupby sur une colonne catégorielle produit un DataFrame agrégé.
Checklists par rôle
- Data scientist : valider qualité des labels, features numeriques, normalisation.
- Data analyst : vérifier cohérence des agrégations, filtres temporels.
- Data engineer : préparer pipeline d’ingestion, schéma et indexation.
Arbre de décision pour choisir un outil (Mermaid)
graph TD
A[Vos données tiennent en RAM ?] -->|Oui| B[Utiliser pandas]
A -->|Non| C[Paralléliser ou out-of-core]
C --> D{Traitements complexes ou jointures ?}
D -->|Oui| E[Base de données / SQL]
D -->|Non| F[Dask ou Polars]Glossaire (1 ligne chacun)
- DataFrame : table en mémoire avec index et colonnes nommées.
- Series : colonne unique d’un DataFrame.
- Vectorisation : application d’opérations sur des tableaux entiers.
- dtype : type de données d’une colonne (int, float, object, datetime).
Scénarios où pandas n’est pas la meilleure option
- Données > RAM et nécessité de traitement en temps réel : préférez Spark, Dask ou une base distribuée.
- Traitements en streaming : technologies spécialisées (Kafka Streams, Flink).
- Besoin de très hautes performances mémoire et multi-thread : Polars peut être mieux.
Sécurité, vie privée et bonnes habitudes
- Ne chargez pas des données personnelles sensibles sans cryptage ni anonymisation.
- Lorsque vous partagez des notebooks, supprimez ou anonymisez les colonnes sensibles.
- Respectez le RGPD : minimisez la conservation des données personnelles.
Résumé
pandas est un outil central pour manipuler des données tabulaires en Python. Il permet de charger, nettoyer, explorer et préparer des données pour la visualisation et la modélisation. Pour des jeux de données courants qui tiennent en mémoire, c’est la solution la plus pratique. Pour des volumes plus importants, évaluez Dask ou Polars.
Principaux points à retenir :
- Installez pandas avec pip et utilisez Jupyter pour prototyper.
- DataFrame = structure tabulaire ; apprenez head(), tail(), describe(), dtypes.
- Préférez les opérations vectorisées aux boucles.
- Pour les très grands jeux de données, considérez des alternatives.
Notes finales : ce guide vous aide à démarrer l’exploration de jeux de données avec pandas. Pour aller plus loin, pratiquez sur vos propres jeux de données, documentez vos étapes et sauvegardez des versions intermédiaires.
Matériaux similaires

Installer et utiliser Podman sur Debian 11
Guide pratique : apt-pinning sur Debian

OptiScaler : activer FSR 4 dans n'importe quel jeu
Dansguardian + Squid NTLM sur Debian Etch

Corriger l'erreur d'installation Android sur SD
