Load average в Linux — как читать и оптимизировать
Что такое load average в Linux
Load average — это показатель, который отражает среднее количество процессов, либо выполняемых на CPU, либо ожидающих CPU (включая процессы в состоянии uninterruptible sleep, часто ожидающие ввода-вывода). В отличие от мгновенной загрузки CPU (CPU usage), load average даёт сглаженную картину активности системы за интервалы 1, 5 и 15 минут.
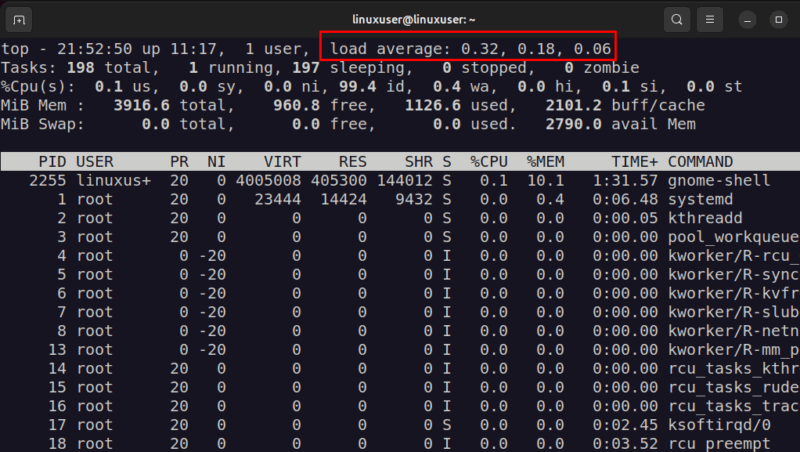
Linux выводит три числа, например:
load average: 0.19, 0.10, 0.14- Первое число — среднее за 1 минуту.
- Второе — за 5 минут.
- Третье — за 15 минут.
Коротко: load average измеряет не процент загрузки CPU, а количество активных и ожидающих процессов в системе.
Как интерпретировать значения
Чтобы понять, здоровая ли текущая нагрузка, нужно знать число логических ядер (vCPU) в системе. Можно узнать его командой:
nproc
# или
lscpu | grep -i "cpu(s):"Правила интерпретации:
- Для одноядерной машины load average ~1.0 ≈ 100% загрузки CPU.
- Для N ядер — load average ≈ N соответствует полной загрузке всех ядер.
- Если load average стабильно выше N — процессы чаще ждут CPU и система перегружена.
Важно: высокая нагрузка не всегда означает проблемный CPU. Часто причиной являются задержки ввода-вывода (I/O wait), нехватка памяти (swap) или большое количество блокированных процессов.
Команды и способы проверки
Ниже — набор команд, которые быстро дадут картину состояния системы.
uptime
Показывает время работы, число пользователей и три числа load average:
uptimeПример вывода: средняя нагрузка 0.15, 0.15, 0.04 — система в данный момент загружена минимально.
/proc/loadavg
Читать напрямую:
cat /proc/loadavgФормат похож на вывод uptime и дополнительно содержит число запущенных задач и last PID.
top, htop
top и htop дают интерактивный, постоянно обновляющийся вид процессов и вверху показывают load average. Используйте htop для удобной сортировки и фильтрации по колонкам.
top
# или
htop
ALT: Снимок экрана команды top с выделенными значениями load average и таблицей процессов
vmstat, iostat, sar
vmstat 1 5— показывает блоки CPU, памяти и ввода-вывода в коротких интервалах.iostat -x 1 5— детализирует I/O по дискам.sar(sysstat) — собирает исторические метрики.
Примеры:
vmstat 1 5
iostat -x 1 5glances, atop
Инструменты уровня «всё в одном»: glances и atop удобно показывают I/O, сеть, процессор и память и помогают увидеть узкие места быстро.
Типичные причины высокого load average
- CPU-нагрузка (CPU-bound приложения).
- Долгие операции ввода-вывода (I/O wait) — часто из-за медленных дисков или перегрузки контроллеров.
- Нехватка оперативной памяти и активное использование swap.
- Множество одновременно запущенных cron-джобов или фоновых задач.
- «Зависшие» или блокированные процессы (uninterruptible sleep).
Как найти причину — пошаговая методология
Короткая методология (6 шагов):
- Посмотрите три числа load average (
uptimeили/proc/loadavg). - Узнайте число логических ядер (
nproc). - Откройте
top/htop, отсортируйте по CPU и по TIME+. - Проверьте
vmstatиiostatна признаках I/O wait (wa) и высокой дисковой загрузки. - Просмотрите логи и cron (
grep CRON /var/log/syslog) на предмет одновременных задач. - При необходимости остановите подозрительные процессы и повторно оцените.
Пример использования top для поиска виновника
- Запустите
top. - Нажмите
Pдля сортировки по CPU,M— по памяти. - Смотрите колонку S (состояние):
R— running,D— uninterruptible sleep (обычно I/O),Z— zombie.

ALT: Окно top с процессами Firefox и GNOME Shell, демонстрирующее причины повышенной загрузки CPU
Как понижать высокий load average — практические шаги
- Остановите ненужные или «упавшие» процессы:
kill/kill -9по PID. - Закройте ресурсоёмкие приложения (браузеры, компиляторы, CI-задания).
- Ограничьте одновременное число пользователей или задач.
- Добавьте или настройте swap, чтобы снизить давление на память.
- Оптимизируйте приложения: уменьшите число потоков, буферов, используйте профилирование.
- Установите приоритеты через
nice/reniceдля фоновых задач. - Для I/O-проблем — рассмотрите SSD, RAID, перераспределение нагрузки или настройку очередей диска.
Пример команды для изменения приоритета (уменьшить приоритет фоновой задачи):
renice +10 -p 12345Диск и I/O — распространённая ловушка
Высокий wa в top указывает на ожидание ввода-вывода. Даже при низкой загрузке CPU обилие операций чтения/записи может поднять load average, потому что процессы остаются в состоянии ожидания.
Рекомендации при высоком I/O wait:
- Проанализируйте
iostat -xиiotop. - Перенесите горячие файлы на более быстрые диски.
- Разбейте I/O-горячие задачи по времени или устройствам.
- Проверьте файловые системы на ошибки и дефрагментацию (для соответствующих FS).
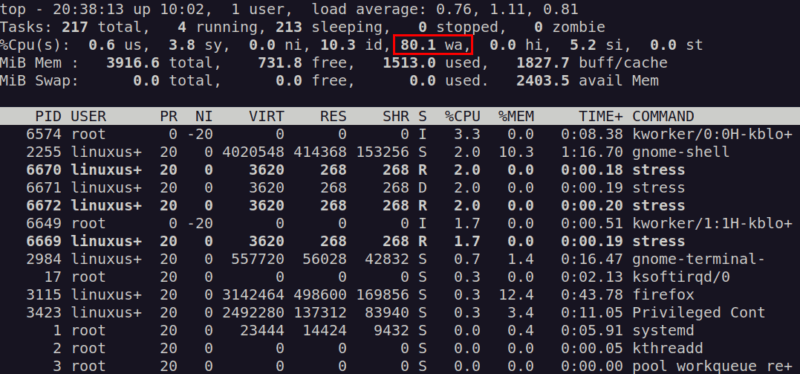
ALT: График I/O wait и использование диска, показывающий узкие места в дисковой подсистеме
Управление cron и планирование задач
Одновременный старт множества cron-джобов создаёт кратковременные всплески load average. Проверьте перекрытия:
grep CRON /var/log/syslog | tail -n 50Варианты решения:
- Распределяйте время запуска.
- Используйте Anacron для периодических задач на десктопах/машинах с ненулеым аптаймом.
- Установите простой планировщик (systemd timers) с рандомизацией времени старта.
Контейнеры и оркестрация
Docker и Kubernetes помогают изолировать ресурсы: лимиты CPU и памяти предотвращают, чтобы один контейнер полностью заорал ресурсы хоста. Настройте ресурсы под контролем:
- В Kubernetes используйте requests/limits для CPU и памяти.
- В Docker — флаги
--cpus,--memory.
Когда load average обманчив
- Высокая загрузка в однопоточном приложении на многопроцессорном хосте может быть нормой.
- Низкий load average не гарантирует отсутствие проблем — например, короткие пиковые нагрузки могут не отразиться в 5/15-минутных числах.
- На виртуальных хостах значение load average стоит интерпретировать с учётом overcommit-а и разделения физических CPU между VM.
Рольные чек-листы (для быстрого действия)
Системный администратор:
- Узнать число ядер (
nproc). - Запустить
top/htopиvmstat. - Проверить
iostatи логи cron. - При необходимости ограничить задачи (
nice) или остановить их.
Разработчик:
- Посмотреть, не вызвано ли это вашим приложением (горячие циклы, утечки потоков).
- Запустить профилирование (perf, strace).
- Оптимизировать числа потоков и операции I/O.
SRE / инженер по надежности:
- Настроить мониторинг (Prometheus + node_exporter показывает load average и число CPU).
- Установить алерты при load > 0.8 * vCPU в течение N минут.
- Планировать capacity и тестирование в нагрузке.
Мини-методология диагностики (шаблон)
- Снять текущие показатели: uptime, top, vmstat, iostat.
- Определить, связана ли проблема с CPU, I/O или памятью.
- Найти процессы-«виновники».
- Протестировать простые меры: nice, остановка процесса, перераспределение.
- Внедрить долгосрочные меры: лимиты, оптимизация, апгрейд.
Decision tree (общее руководство)
flowchart TD
A[Высокий load average] --> B{load > vCPU?}
B -- Да --> C{wa 'I/O wait' высокий?}
B -- Нет --> D[Проверьте память и swap]
C -- Да --> E[Проверить iostat и iotop; улучшить диск или распределить I/O]
C -- Нет --> F[Процессы CPU-bound: оптимизировать или распределить]
D --> G[Swap активен? -> добавить RAM или оптимизировать потребление]
E --> H[Рассмотреть SSD/RAID/профилирование дисков]
F --> I[Использовать nice/renice, ограничить контейнеры]Критерии приёмки
- Load average после действий стабильно ниже или равен числу логических ядер.
- Значения I/O wait находятся в нормальном диапазоне для вашей нагрузки.
- Пользовательские сервисы отвечают в ожидаемые SLA.
Однострочный глоссарий
- load average — среднее количество процессов, выполняющихся или ожидающих CPU;
- wa — проценты времени CPU в ожидании ввода-вывода;
- swap — пространство подкачки на диске;
- nice/renice — инструменты для изменения приоритетов процессов.
Примеры, когда метрика не подходит
- Для диагностики сетевых задержек load average почти бесполезна — используйте netstat, ss, tcpdump.
- Для IO-bound задач лучше смотреть iostat, iotop и показатели дисковой подсистемы, а не только load average.
Итоги
Load average — полезная, но контекстно-зависимая метрика. Сравнивайте её с числом логических ядер и дополняйте проверкой I/O, памяти и процессов. Быстрая диагностика — uptime, top, vmstat, iostat и /proc/loadavg. Решения варьируются от простой остановки процесса до переработки архитектуры I/O и добавления ресурсов. Регулярный мониторинг и лимитирование ресурсов (в контейнерах или на уровне ОС) помогают держать систему стабильной.
Важно: перед перезагрузкой всегда сначала попытайтесь найти и устранить корень проблемы, чтобы избежать повторения.
Похожие материалы

Herodotus: механизм и защита Android‑трояна
Включить новое меню «Пуск» в Windows 11

Панель полей сводной таблицы в Excel — руководство

Включить новое меню «Пуск» в Windows 11
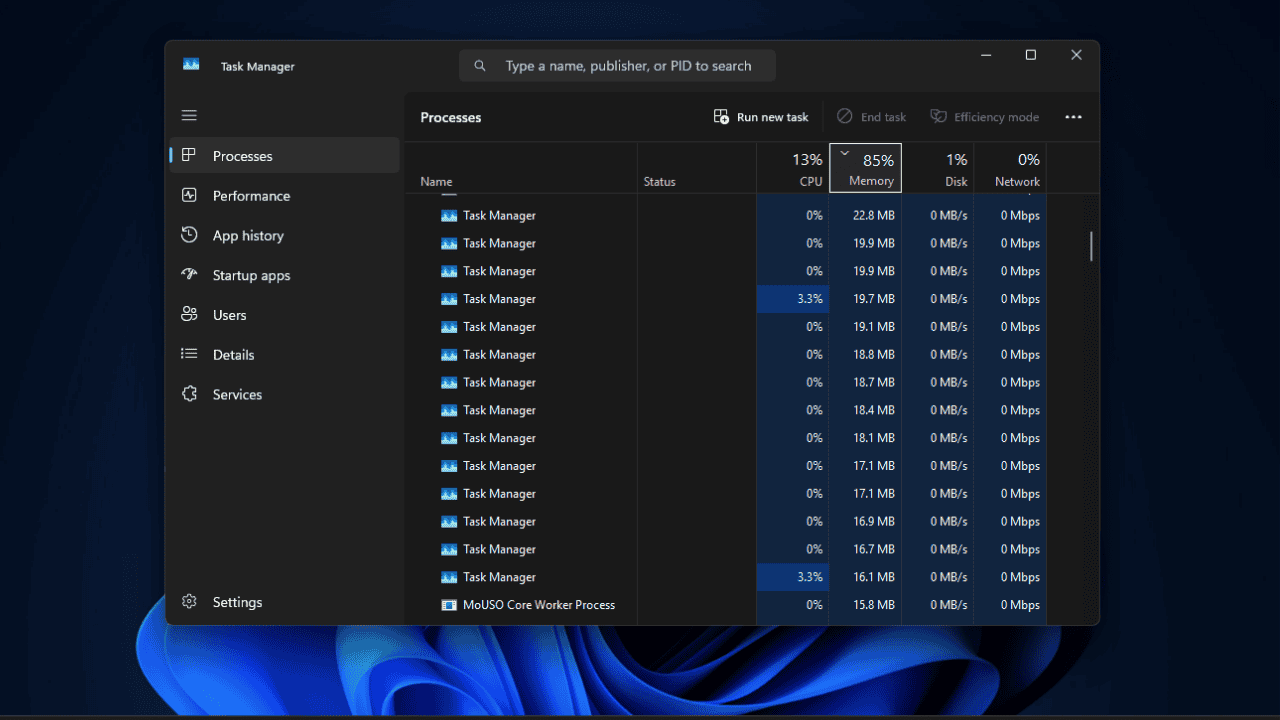
Дубликаты Диспетчера задач в Windows 11 — как исправить
