Мониторинг и оповещения в Google Cloud Platform

- Google Cloud Monitoring собирает метрики и логирует состояние ресурсов GCP (и поддерживает AWS). Настраивайте дашборды и пользовательские оповещения (Uptime Checks и Alerting Policies) для раннего обнаружения инцидентов.
- В статье — пошаговая инструкция по созданию дашборда и алертов, шаблоны плейбука инцидента, чеклисты для ролей, критерии приёмки и рекомендации по тестированию.
Быстрые ссылки
Введение
Google Cloud Platform предоставляет встроенный набор инструментов для наблюдения за состоянием ресурсов: сбор метрик, визуализация в дашбордах, проверки доступности и система оповещений. Это упрощает обнаружение проблем и реагирование на инциденты как для GCP, так и для подключённых AWS-ресурсов.
Короткие определения
- Метрика: числовой показатель (например, CPU Utilization).
- Uptime Check: внешняя проверка доступности веб/TCP сервиса.
- Alerting Policy: правило, которое генерирует уведомление при выполнении условия.
Настройка панели мониторинга
GCP автоматически создаёт базовые дашборды для основных ресурсов (Cloud Storage, диски, Compute Engine). Полная служба мониторинга доступна в боковой панели под Operations и в интерфейсе Monitoring.

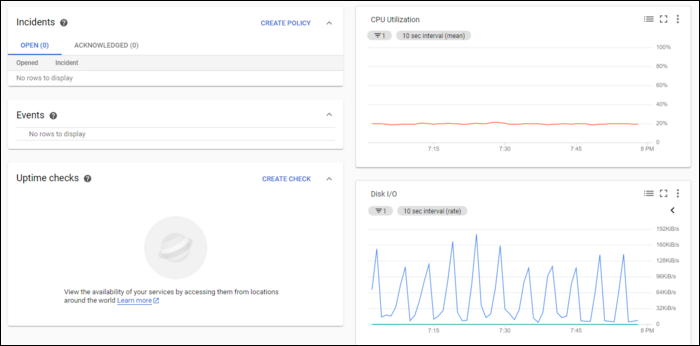
Существующие дашборды видны во вкладке Dashboards:

Типовой график для Compute Engine по умолчанию показывает загрузку CPU, операции ввода/вывода диска и недавние оповещения. Период и диапазон времени на графиках можно менять.
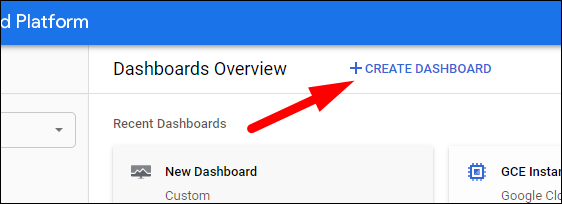
Создание собственного дашборда — пошагово
- В панели Monitoring откройте Dashboards и нажмите «Create dashboard».
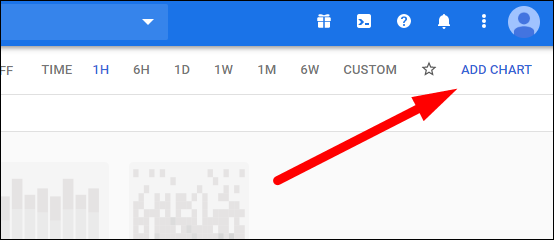
- Добавьте диаграмму (chart) — диаграммы могут содержать несколько метрик.
- Выберите Resource Type (тип ресурса). Это ограничит набор доступных метрик к применимым.
- Укажите Metric name — какие данные показывать (CPU, Disk I/O, Memory, Network In/Out).
- Настройте Filter, чтобы задать дефолтный проект, имя инстанса, зону или группу.
- Group By меняет способ агрегирования/отображения нескольких ресурсов (например, разделять по имени инстанса).
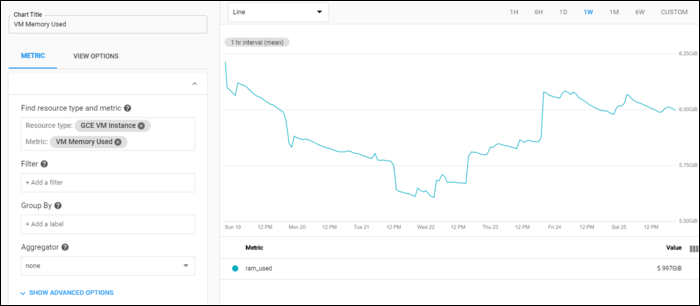
- Сохраните диаграмму. В любой момент можно править настройки или включить режим статистики (Stats Mode) для скользящих средних.
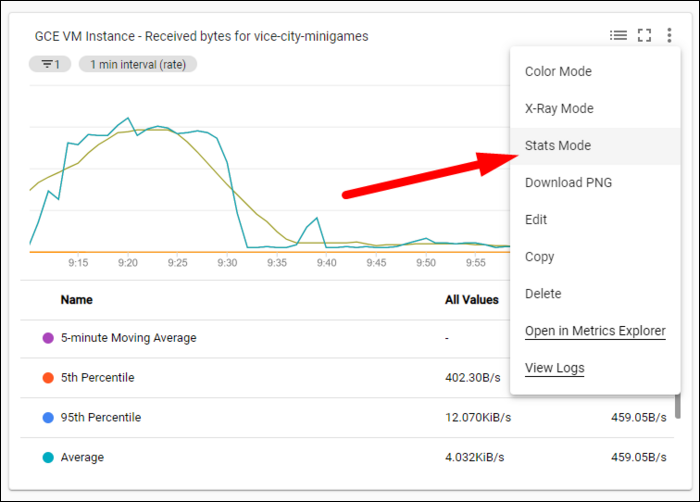
Важно: создавайте дашборды, применимые к группе ресурсов, чтобы переиспользовать их для разных проектов и зон. Для быстрого расследования можно добавить фильтр по instance name или по тегам.
Настройка пользовательских оповещений
Monitoring предлагает две базовые функции оповещений — Uptime Checks и Alerting Policies. Обе бесплатны и не лимитированы.
Uptime Checks выполняют внешние HTTP/TCP проверки на заданном интервале. Alerting Policies оценивают метрики и генерируют оповещение при соблюдении условий.
Uptime checks создаются из Overview:
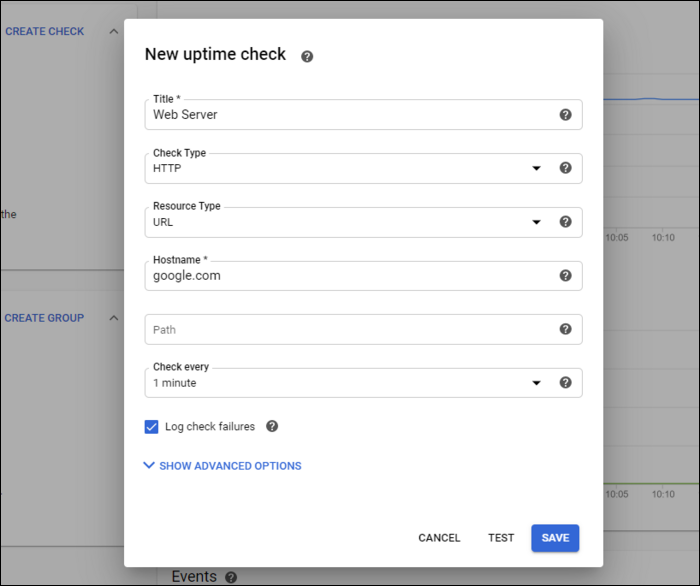
После сохранения Uptime Check сервис предложит добавить Alert Policy, которая будет оповещать при падении доступности.
Alerting Policies настраиваются в разделе Alerting: выберите ресурс, метрику, фильтр и условие. Пример: триггер — CPU Utilization > 80% в течение 5 минут.
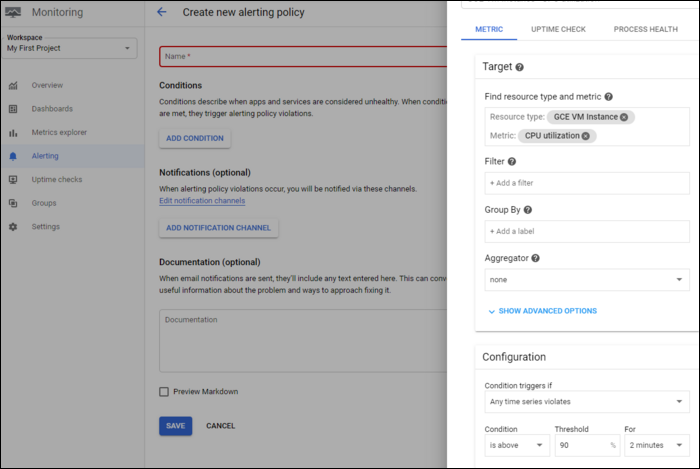
Каналы уведомлений
Для оповещений можно использовать:
- Email (самый простой)
- SMS
- Slack
- Webhook (для интеграции с внешними платформами)

Рекомендация: используйте несколько каналов одновременно (например, Slack для команды, Email для эскалации).
Типичные метрики и примеры политик
| Ресурс | Метрика | Пример условия (Alerting Policy) |
|---|---|---|
| Compute Engine | CPU Utilization | > 80% в течение 5 минут |
| Диск | Disk Read/Write Ops | резкий рост > 200% базовой линии |
| Сеть | Network In/Out (bytes) | устойчивое падение трафика на N% |
| Приложение | HTTP 5xx rate | > 1% от запросов за 2 мин |
| Балансировщик | Latency | p95 > допустимого SLA |
Эти примеры — отправная точка. Настраивайте пороги с учётом нормального поведения приложения.
Лучшие практики
- Определите «эмоционные пороги»: критично/важно/инфо, чтобы не генерировать шум.
- Начните с низкой частоты проверок, затем уменьшайте интервалы для критичных сервисов.
- Группируйте инстансы по ролям и применяйте общие дашборды.
- Настройте runbooks для каждого типа оповещения.
- Тестируйте уведомления до продакшна.
Когда мониторинг не сработает — типичные причины
- Неправильные фильтры: дашборд показывает не те инстансы.
- Неподходящие пороги: слишком высокие — запаздывание, слишком низкие — ложные срабатывания.
- Проблемы с каналом уведомлений: Email/SMS блокируются.
- Скрытые буферы: метрика аггрегируется и «сглаживает» кратковременные пики.
Контрмеры: используйте несколько представлений метрик, включите скользящие средние и одноразовые проверки (ephemeral alert) для пиков.
Альтернативные подходы
- Prometheus + Grafana: гибкая система сбора и визуализации, хорошо подходит для микросервисов.
- Datadog/New Relic: облачные SaaS-платформы с расширенными интеграциями и APM.
Выбор зависит от требований к SLA, стоимости и степени контроля над метриками.
Модель принятия решений (Mermaid)
flowchart TD
A[Проблема видна на дашборде?] -->|Да| B{Это критично?}
A -->|Нет| G[Настроить метрики / добавить логи]
B -->|Да| C[Проверить Alerting Policy]
B -->|Нет| D[Сохранить наблюдение, добавить тикет]
C --> E{Уведомление ушло?}
E -->|Да| F[Следовать runbook]
E -->|Нет| H[Проверить каналы уведомлений и права]Роли и чеклисты
SRE / On-call:
- Убедиться, что критичные алерты имеют runbook.
- Проверить каналы уведомлений и их тестовую доставку.
- Настроить эскалации.
DevOps / Инженер инфраструктуры:
- Создать дашборд для группы инстансов.
- Настроить группировку и фильтры.
- Делать ревью порогов каждый релиз.
Product Manager / Владелец сервиса:
- Утвердить SLA и ключевые показатели.
- Убедиться, что важные бизнес-метрики мониторятся.
Security / Compliance:
- Отслеживать метрики доступа и аномалии в трафике.
- Настроить оповещения о несанкционированных изменениях.
Плейбук инцидента и откат (шаблон)
- Получено оповещение — определить приоритет (P0/P1/P2).
- On-call запускает runbook для типа алерта.
- Сбор информации: последние 15 минут логов, нагрузка, сети, метрики.
- Если требуется — масштабировать вверх/вниз (scale up/down) или отключить проблемный экземпляр.
- Проверить восстановление; если не восстановлено — откат к последней стабильной версии.
- После восстановления — post-mortem, запись действий и изменение порогов/документации.
Критерии приёмки
- Дашборд отображает ключевые метрики для каждой роли сервиса.
- Алерты имеют описанный runbook и канал уведомлений.
- Тестовые оповещения доставляются всем каналам.
Тестовые сценарии и критерии приёмки
Пример теста для Alerting Policy:
- Предусловие: тестовая метрика искусственно повышена до 85% CPU.
- Действие: дождаться выполнения условия 5 минут.
- Ожидаемый результат: оповещение приходит в Slack и Email; runbook запускается.
Автоматические тесты: используйте CI/CD для временного применения тест-политик и проверки доставки уведомлений.
Риски и смягчения
- Шум от ложных алертов — смягчение: повышение порога, увеличение временного окна, добавление условия на другой метрике.
- Потеря уведомлений — смягчение: мультиканальная доставка, проверка доставки, мониторинг статуса каналов.
- Человеческий фактор (непонятные runbook) — смягчение: простые инструкции, ссылки на логи и команды восстановления.
Шпаргалка: быстрые команды и шаблоны
Шаблон сообщения в Slack при инциденте:
“INCIDENT: [P{x}] Сервис: <имя>, Симптом: <описание>, Время:
, Действия: <ссылка на runbook>” Стандартный набор метрик для дашборда: CPU, Memory, Disk I/O, Network In/Out, Error rate (5xx), Latency p95.
Глоссарий (1-строчные определения)
- Dашборд: визуальная панель с графиками и метриками сервиса.
- Alerting Policy: правило, генерирующее оповещение при выполнении условия.
- Uptime Check: внешняя проверка доступности сервиса.
Итог
Настройка мониторинга и оповещений в GCP — это сочетание правильно подобранных метрик, осмысленных порогов и отработанных процессов реагирования. Постройте переиспользуемые дашборды, тестируйте каналы уведомлений и документируйте runbook’ы: это уменьшит время реакции и количество ложных срабатываний.
Important: настройте мультиканальные оповещения и регулярный ревью правил, чтобы система оставалась релевантной по мере роста инфраструктуры.
Дополнительно: если нужно, могу подготовить CSV-шаблон дашборда или пример JSON для импорта Alerting Policy.
Похожие материалы

Herodotus — Android‑троян и защита
Как включить новый Пуск в Windows 11

Панель полей сводной таблицы в Excel — быстрый разбор

Включение нового меню Пуск в Windows 11
Дубликаты Диспетчера задач в Windows 11 — как исправить
