빠른 링크
- pandas란 무엇인가?
- DataFrame이란?
- DataFrame 생성하기
- DataFrame 가져오기
- DataFrame 살펴보기
- 열 추가 및 삭제
- 열 연산 수행하기
- 실무 체크리스트 및 플레이북
pandas란 무엇인가?

정의(한 줄): pandas는 파이썬에서 표 형식(테이블) 데이터를 읽고 조작하며 분석하도록 설계된 라이브러리입니다. 주요 기능은 DataFrame이라는 2차원 레이블이 있는 데이터 구조를 제공하는 것입니다.
핵심 요약: pandas는 데이터 읽기/쓰기(CSV, Excel 등), 결측치 처리, 그룹화(aggregation), 조인, 시계열 처리, 기본 통계 함수 제공, 그리고 다른 시각화/통계 라이브러리와의 연동에 강합니다. 상호작용이 쉬운 환경(Jupyter)에서 특히 유용합니다.
설치 예시 (PyPI):
pip install pandas권장 환경: Jupyter Notebook/Lab 또는 IPython. Jupyter를 사용하면 코드 실행 기록과 시각화를 문서 형태로 보관할 수 있어 반복 분석에 유리합니다.
노트: pandas는 초기 개발자와 기여자가 있고 오픈소스로 유지됩니다. pandas의 내부 구조는 NumPy 배열을 중심으로 구성되어 있어 수치 연산과의 호환성이 좋습니다.
DataFrame이란?
한 줄 정의: DataFrame은 행과 열로 조직된 2차원 레이블 데이터 구조로, 각 열은 서로 다른 자료형(숫자, 문자열, 날짜 등)을 가질 수 있습니다.
비유: 스프레드시트의 시트나 관계형 DB의 테이블과 유사합니다. 컬럼(header)은 변수 이름, 각 행은 관측치(레코드)로 생각합니다.
특징 요약:
- 레이블 인덱스(행 인덱스)와 컬럼 라벨을 가집니다.
- NumPy와 밀접하게 결합되어 벡터화 연산이 가능합니다.
- 결측치(NaN)를 처리하는 다양한 도구를 제공합니다.
DataFrame 생성하기
사전 준비: pandas가 설치되어 있고 NumPy가 있으면 다양한 방법으로 DataFrame을 생성할 수 있습니다.
예: 간단한 선형 함수 열을 가진 DataFrame 만들기
import numpy as np
x = np.linspace(-10, 10)
y = 2 * x + 5
import pandas as pd
df = pd.DataFrame({'x': x, 'y': y})설명: 위 코드는 x(독립변수)와 y(종속변수)를 NumPy로 만들고, 이를 딕셔너리 형태로 DataFrame에 전달합니다. 컬럼 이름은 딕셔너리의 키로 설정됩니다.
대체 생성 방법:
- 딕셔너리 목록: pd.DataFrame([{‘a’:1,’b’:2}, {‘a’:3,’b’:4}])
- 2차원 배열/NumPy: pd.DataFrame(np_array, columns=[…])
- Series 병합: pd.concat([…], axis=1)
DataFrame 가져오기
데이터는 보통 파일이나 외부 소스에서 불러옵니다. pandas는 다양한 포맷을 지원합니다.
CSV 불러오기:
df = pd.read_csv('/path/to/data.csv')Excel 불러오기:
df = pd.read_excel('/path/to/spreadsheet.xls')클립보드로부터 불러오기(작은 표 테스트용):
df = pd.read_clipboard()추가 옵션: 인코딩(encoding), 구분자(sep), 날짜 자동 파싱(parse_dates), 특정 컬럼을 인덱스로 사용(index_col) 등 다양한 파라미터가 있습니다.
팁: 대용량 데이터(수백 MB 이상)는 read_csv의 iterator, chunksize 옵션을 사용하거나 Dask 같은 대체 도구를 고려하세요.
DataFrame 살펴보기
데이터를 불러온 후에는 구조와 핵심 통계량을 먼저 확인합니다.
기본 조회:
df.head()
df.tail()부분 슬라이스:
df[1:3] # 1번 인덱스부터 2번 인덱스까지행 개수 제한 지정:
df.head(10)
df.tail(10)컬럼 목록 확인:
df.columns기술 통계량(숫자형 컬럼):
df.describe()컬럼 하나의 통계:
df['Age'].describe()
df['Age'].mean()
df['Age'].median()긴 출력 제어:
pd.set_option('display.max_rows', None)이미지 예시:

실습 예시 — Titanic 데이터셋 불러오기:
titanic = pd.read_csv('data/Titanic-Dataset.csv')
titanic.head()
데이터 설명 예시:
titanic.columns
titanic.describe()
설명: describe()는 평균(mean), 표준편차(std), 최소값(min), 25%/50%/75% 분위수, 최대값(max)을 반환하여 데이터 분포를 빠르게 이해하게 해줍니다.
컬럼 선택과 출력:
titanic['Name']
# 긴 목록 전체를 출력
titanic['Name'].to_string()컬럼 선택 결과가 잘리면 pd.set_option으로 제어할 수 있습니다.
열 추가 및 삭제
열 연산은 벡터화되어 있어 빠르고 직관적입니다.
예: 제곱값을 새 열로 추가
# 기존 열을 연산
df['x_squared'] = df['x'] ** 2
# 삭제
df = df.drop('x_squared', axis=1) # axis=1은 컬럼을 의미주의: drop은 기본적으로 원본 DataFrame을 변경하지 않습니다(복사본 반환). 원본을 바꾸려면 inplace=True를 쓰거나 결과를 할당하세요.
열 연산 수행하기
수학/통계 연산, 문자열 처리, boolean 필터링 등 다양한 연산이 가능합니다.
간단한 수치 연산:
df['x'] + df['y']여러 컬럼 선택:
subset = titanic[['Name', 'Age']]조건 필터링(불리언 색인):
older_than_30 = titanic[titanic['Age'] > 30].loc를 사용한 선택:
older_than_30 = titanic.loc[titanic['Age'] > 30]SQL 유사 쿼리 예시:
SELECT * FROM titanic WHERE Age > 30값 집계 및 시각화 예시 — 탑승항구별 인원 수 막대그래프:
embarked = titanic['Embarked'].value_counts()
embarked = embarked.rename({'S':'Southhampton', 'C':'Cherbourg', 'Q':'Queenstown'})
embarked.plot(kind='bar')이미지: 탑승 항구별 막대 차트
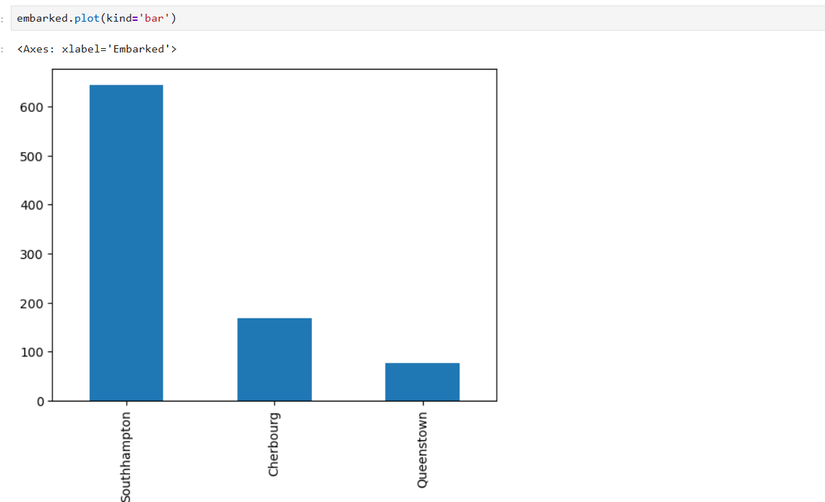
설명: value_counts()는 해당 컬럼의 각 값의 빈도수를 반환합니다. rename()은 인덱스(여기서는 항구 코드)를 사람이 읽기 쉬운 이름으로 바꿉니다.
중요
- 큰 데이터셋은 메모리 문제를 일으킬 수 있습니다. 메모리 제약이 있으면 chunk 단위로 읽거나 Dask/Polars 같은 대체 프레임워크를 고려하세요.
- 연산 시 pandas는 자동으로 자료형을 추론합니다. 하지만 의도치 않은 object dtype(문자열) 변환이 발생할 수 있으니 dtype을 명시하여 읽는 것이 안전합니다.
언제 사용하지 말아야 하는가
- 데이터가 수 기가바이트 이상으로 메모리에 전부 올라오지 않는 경우.
- 초저지연(실시간) 처리나 분산 처리 파이프라인(대규모 스트리밍)에는 부적절할 수 있습니다.
- 고성능 수치 연산을 위해서는 NumPy, Numba, 혹은 GPU 기반 라이브러리를 고려하세요.
대안: Dask(분산/병렬), Polars(성능 최적화된 DataFrame), Vaex(메모리 효율적 대규모 데이터), SQLite/BigQuery 같은 데이터베이스.
사고 모델과 휴리스틱
- 데이터를 ‘읽기 → 확인 → 정리(결측/중복/타입) → 변환 → 분석/시각화‘ 단계로 나눠 작업하세요.
- 우선성: 결측치/중복/형식 오류를 먼저 해결하면 분석 신뢰도가 크게 올라갑니다.
- 오류 방지: 연산 전 .info(), .dtypes로 컬럼 타입을 확인하고, inplace 사용을 최소화하여 의도치 않은 원본 변경을 방지하세요.
미니 방법론: 데이터 탐색(EDA) 7단계
- 데이터 불러오기(read_*)
- 기본 구조 확인(.head(), .info(), .describe())
- 결측치/중복 탐지(.isnull().sum(), .duplicated())
- 타입 정리(.astype(), to_datetime)
- 파생변수 생성(도메인 지식 기반)
- 그룹화/집계(.groupby, .agg)
- 시각화(matplotlib/seaborn)로 인사이트 검증
역할별 체크리스트
데이터 분석가
- 데이터의 샘플을 보고 변수 정의를 문서화한다.
- 결측치 정책을 정한다(삭제, 대체, 예측).
- 파생 변수 후보를 도출한다.
데이터 엔지니어
- 파일 포맷과 인코딩을 표준화한다.
- 대용량 데이터 처리 파이프라인을 설계한다.
- 스키마(데이터 타입)를 명확히 정의한다.
데이터 사이언티스트
- 분석에 쓰일 컬럼을 확정하고 정규화/스케일링을 적용한다.
- 재현 가능한 노트북과 코드로 실험을 기록한다.
- 모델 입력으로 사용할 DataFrame을 검증한다.
플레이북: 간단한 탐색 워크플로우
- 파일을 불러온다: pd.read_csv / read_excel
- 구조 확인: df.info(), df.head()
- 결측치 파악: df.isnull().sum()
- 자료형 정리: df[‘date’] = pd.to_datetime(df[‘date’])
- 불필요 컬럼 제거: df.drop([…], axis=1)
- 파생 변수 생성: df[‘age_group’] = pd.cut(df[‘age’], bins=[0,18,35,60,100])
- 요약 통계와 시각화: df.groupby(…).mean().plot()
- 결과 저장: df.to_csv(‘cleaned.csv’, index=False)
테스트 사례와 수용 기준
- 불러오기 테스트: UTF-8/CP949 포함 파일을 문제없이 읽을 것.
- 타입 테스트: 날짜 컬럼이 datetime으로 변환될 것.
- 계산 테스트: 파생변수 공식(예: bmi)이 주어진 수식과 일치할 것.
- 재현성: 같은 입력 파일로 동일한 처리 시 동일한 출력이 나올 것.
결정 흐름(간단한 데이터 수입 결정)
flowchart TD
A[데이터 파일 수신] --> B{파일 크기 < 200MB?}
B -- Yes --> C[일반 pandas로 처리]
B -- No --> D[분할/스트리밍 처리 또는 Dask/Polars 검토]
C --> E{메모리 충분?}
E -- Yes --> F[데이터 정리 및 분석]
E -- No --> D
D --> G[성능 최적화 또는 데이터베이스 로드]
F --> H[모델 학습 또는 시각화]위 흐름은 대표적인 기준이며, 프로젝트 요구사항에 따라 임계값(여기선 200MB)은 달라질 수 있습니다.
호환성 및 마이그레이션 팁
- 대용량 데이터 = Dask/Polars 권장. Polars는 pandas API와 비슷하지만 더 빠른 경우가 많습니다.
- 기존 pandas 코드의 병렬화는 간단한 방법으로는 apply 병목을 줄이고 벡터화 연산으로 대체합니다.
- SQL 기반 파이프라인을 사용하는 경우 pandas.read_sql과 SQLAlchemy를 통해 연동할 수 있습니다.
보안 및 개인정보 주의사항
- 개인식별정보(PII)는 로컬 파일에 평문으로 저장하지 마십시오. 최소화, 마스킹 또는 암호화 정책을 적용하세요.
- 외부에서 받은 파일은 악성 포맷(예: 잘못된 엑셀 시트 매크로)이 없는지 확인하세요.
용어집(한 줄 정의)
- Series: 1차원 레이블 배열, 단일 컬럼과 유사.
- Index: 행 레이블; 정렬 및 라벨 기반 선택에 사용.
- Vectorization: 루프 대신 배열 연산을 사용해 빠르게 처리하는 기법.
- NA/NaN: 결측값 표기.
결론 요약
pandas와 DataFrame은 파이썬에서 데이터 탐색과 전처리를 효율적으로 수행하도록 설계된 도구입니다. 작은 데이터셋의 대부분 작업은 pandas로 충분하지만, 데이터 규모나 처리 요구에 따라 대안(Dask, Polars)을 고려해야 합니다. 항상 데이터의 구조와 타입을 먼저 확인하고, 결측치와 이상값 처리를 우선순위로 두세요.
추가 리소스: pandas 공식 문서, Jupyter Notebook 튜토리얼, Polars 및 Dask 프로젝트 페이지 (검색을 통해 최신 자료 확인 권장).
이 가이드가 pandas로 데이터 탐색을 시작하는 데 실용적인 출발점을 제공하길 바랍니다. pandas는 통계학자, 데이터 과학자, 분석가에게 필수적인 도구이며, 실습과 반복을 통해 더 빠르고 안전하게 다룰 수 있습니다.



