개요
이미지는 우리 일상과 업무에서 정보를 담는 중요한 매체입니다. 사진이나 스캔한 문서에 있는 텍스트를 편집 가능한 형태로 바꾸려면 OCR(광학문자인식)이 필요합니다. 이 글에서는 대표적인 방법 세 가지(Gemoo Snap, Google Drive, 온라인 도구)를 단계별로 설명하고, 실제 현장에서 정확도를 높이는 팁, 실패 사례와 대체 방법, 역할별 체크리스트와 간단한 운영 절차(SOP)까지 제공합니다.
Important: OCR 결과는 100% 정확하지 않습니다. 특히 흐린 사진, 기울어진 스캔, 손글씨, 특수서체는 오류가 많습니다. 검수 프로세스를 반드시 포함하세요.
OCR이란 한 줄 정의
OCR(광학문자인식): 이미지를 분석해 문자 패턴을 식별하고 편집 가능한 텍스트로 변환하는 기술입니다.
목차
- Gemoo Snap으로 추출하기
- Google Drive로 추출하기
- 온라인 OCR 도구 활용법
- 정확도 향상 전처리와 실패 사례
- 역할별 체크리스트
- 간단 SOP(작업 절차)
- 자주 묻는 질문(FAQ)
- 요약
Gemoo Snap으로 추출하기
Gemoo Snap은 화면 캡처와 OCR 기능을 결합한 데스크톱 도구입니다. Windows와 macOS에서 사용 가능하며 Chrome 확장도 제공합니다. OCR 인식 후 바로 편집·복사할 수 있어 빠른 워크플로우에 적합합니다.
장점
- 화면에서 바로 선택해서 인식 가능
- 인식된 텍스트를 편집 후 복사 가능
- 클라우드 업로드·이미지 보정 기능 내장
제한사항
- 지원 언어가 제한적일 수 있음(설정에서 출력 언어 코드 예: EN)
- 복잡한 레이아웃, 손글씨 인식은 불완전할 수 있음
단계별 사용법
- Gemoo Snap을 설치 후 실행(Windows/macOS 또는 Chrome 확장).
- 인터페이스에서 Recognize Text (OCR) 기능을 선택하고 Output Language Code를 EN로 설정하세요.
- 인식할 영역을 드래그하거나 캡처합니다.
- 인식 결과가 표시되면 Edit(편집)으로 텍스트를 다듬고 Copy(복사)로 원하는 위치에 붙여넣습니다.

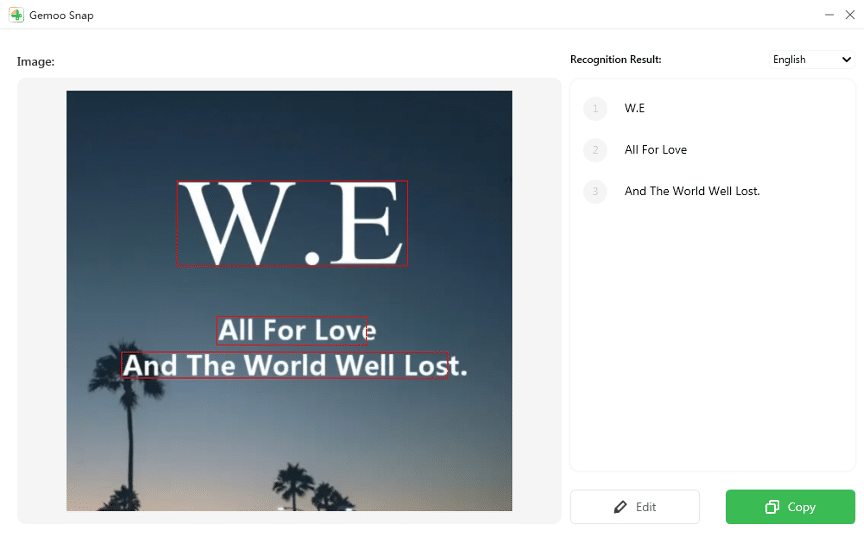
팁: 화면 해상도가 낮으면 먼저 캡처 옵션에서 고해상도(가능하면 원본 크기)로 캡처하세요. 언어 설정이 정확해야 인식률이 올라갑니다.
Google Drive로 추출하기
Google Drive는 추가 소프트웨어 없이 이미지를 Google 문서(문서도구)로 열어 텍스트를 추출할 수 있는 쉬운 방법을 제공합니다.
단계별 사용법:
- Google Drive에 이미지 파일(JPEG, PNG, TIFF, PDF 등)을 업로드합니다.
- 업로드한 파일을 마우스 오른쪽 버튼 클릭 -> “다음으로 열기” -> “Google 문서”를 선택합니다.
- Google 문서가 이미지 아래에 자동으로 인식된 텍스트를 새 문서 형태로 생성합니다.
- 생성된 텍스트를 편집하고 저장하거나 복사해 사용합니다.
장점: 설치 불필요, 간단한 변환, Google 계정만 있으면 가능
단점: 복잡한 레이아웃(다단, 표 포함)은 잘못 변환될 수 있음. 대량 처리엔 별도 워크플로 필요.
참고: 변환 정확도는 이미지 품질과 원문 언어에 크게 좌우됩니다.
온라인 OCR 도구 사용하기
간단히 테스트하거나 가끔 사용하는 경우 온라인 OCR 서비스가 편리합니다. 대표 서비스로는 Online OCR, Free OCR, OCR.space 등이 있습니다.
사용법(일반적):
- 웹사이트 접속 -> 파일 업로드 -> 인식 언어 선택 -> 변환 실행 -> 결과 복사
장점: 설치 불필요, 무료 요금제 제공, 다양한 포맷 지원 단점: 개인정보·민감 문서는 업로드 위험, 대량 처리 제한, 업로드 크기 제한
보안 노트: 민감한 문서(개인정보, 계약서 등)는 신뢰 가능한 엔터프라이즈 솔루션 또는 로컬 OCR을 사용하세요.
정확도 향상을 위한 전처리 팁
이미지 전처리는 OCR 성공률을 크게 높입니다. 다음 절차를 권장합니다.
- 해상도: 가능하면 300 DPI 이상(스캔시). 사진은 가능한 원본 크기로 사용.
- 기울기 보정: 문서가 기울어졌다면 수평으로 보정합니다.
- 대비/명도: 텍스트가 배경과 충분히 구분되도록 대비를 높입니다.
- 노이즈 제거: 불필요한 점·음영 제거(필터 사용).
- 영역 분할: 복잡한 레이아웃은 텍스트 블록 단위로 나눠 인식하세요.
간단 체크리스트:
- 텍스트가 선명한가?
- 문서가 기울어있지 않은가?
- 불필요한 마크업(스탬프, 도장)이 있는가?
언제 OCR이 실패하는가 (대표 사례)
- 손글씨: 글자 모양이 일정치 않으면 오류가 큽니다.
- 복잡한 레이아웃: 여러 열, 표, 이미지 혼합 문서
- 특수서체/손상된 인쇄물: 독특한 폰트나 번짐이 있는 문서
- 낮은 해상도·저조명 사진: 문자 인식 불가
대응 방법: 전처리(스캔 재촬영, 이미지 보정) → 다른 OCR 엔진 재시도 → 인간 검수/타이핑 서비스 이용.
역할별 체크리스트
사용자인 경우(개인):
- 간단한 문장은 Gemoo Snap 또는 Google Drive로 우선 시도
- 민감 문서는 로컬 툴로만 처리
콘텐츠 관리자:
- 배치 처리 시 OCR 로그와 원본 이미지를 보관
- 검수 라인(편집자)을 두어 오탈자 수정
보안 담당자:
- 외부 서비스 업로드 규정 수립
- 암호화 전송/저장 여부 확인
간단 SOP: 이미지 텍스트 추출 절차
- 원본 확보 및 분류(민감·비민감)
- 전처리(해상도 보정, 기울기 수정, 노이즈 제거)
- 1차 OCR(Gemoo Snap 또는 Google Drive 적용)
- 결과 비교(필요 시 다른 엔진 재시도)
- 사람이 검수하여 최종 수정
- 결과 저장 및 메타데이터 기록
수용 기준:
- 키워드·숫자 데이터는 99% 이상 정확할 것(인간 검수 후)
- 일반 텍스트는 문서 유형에 따라 95% 수준 목표
비교표: 간단 선택 가이드
- Gemoo Snap: 빠른 화면 캡처 + 편집이 필요할 때 추천
- Google Drive: 추가 설치 없이 간단히 변환할 때 추천
- 온라인 OCR 서비스: 파일 한두 개 빠르게 테스트할 때 추천
- 엔터프라이즈 OCR(예: ABBYY, Adobe Acrobat 등): 대량·고정밀 작업 및 보안 요구 시 추천
추가 기술적 팁(개발자/자동화 담당자용)
- 배치 처리: OCR 엔진 API(예: Tesseract, OCR.space API 등)를 사용해 파이프라인 구성
- 언어모델 연동: 추출 후 자연어처리로 교정(스펠링체크, 문맥 복원)
- SLI/SLO 아이디어: 인식 성공률(사전 정의된 검수 샘플 기준)과 처리 지연 시간으로 모니터링
flowchart TD
A[이미지 준비] --> B{이미지 품질}
B -- 좋음 --> C[OCR 적용]
B -- 보통/나쁨 --> D[전처리]
D --> C
C --> E{결과 신뢰도}
E -- 높음 --> F[저장 및 활용]
E -- 낮음 --> G[다른 엔진 or 인간 검수]
G --> F자주 묻는 질문
Q: OCR이란 무엇인가요?
A: OCR은 Optical Character Recognition(광학문자인식)의 약자로, 이미지를 분석해 문자를 식별하고 텍스트로 변환하는 기술입니다.
Q: 어떤 OCR 소프트웨어가 유명한가요?
A: Gemoo Snap, Adobe Acrobat, ABBYY FineReader, Readiris 등이 자주 사용됩니다.
Q: 손글씨도 추출할 수 있나요?
A: 가능하지만 정확도는 글씨체와 품질에 크게 좌우됩니다. 보통은 인쇄체보다 정확도가 낮습니다.
Q: 어떤 파일 형식에서 추출할 수 있나요?
A: JPEG, PNG, PDF, TIFF 등 일반 이미지와 스캔 파일에서 추출할 수 있습니다.
Q: OCR 정확도는 어느 정도인가요?
A: 언어·이미지 품질에 따라 다르지만, 영어의 경우 보통 90–95% 수준이라는 보고가 있습니다. 이는 참고치이며 실제 값은 환경에 따라 달라집니다.
Q: 스캔한 문서에서도 쓸 수 있나요?
A: 네, 스캔한 문서에서도 OCR로 텍스트를 추출할 수 있습니다.
요약
- 간단히 텍스트를 추출하려면 Gemoo Snap(빠른 캡처+편집)과 Google Drive(설치 불필요)를 먼저 시도하세요.
- 전처리(해상도/기울기/대비)와 언어 설정이 정확해야 인식률이 올라갑니다.
- 흐린 이미지, 손글씨, 복잡한 레이아웃은 오류가 많으므로 인간 검수나 대체 워크플로가 필요합니다.
Notes: 민감한 문서는 외부 온라인 서비스에 업로드하지 마시고 로컬 엔드포인트나 신뢰 가능한 엔터프라이즈 솔루션을 사용하세요.
저장/배포용 소셜 미리보기 제안:
- 제목: 이미지에서 텍스트 추출하는 실무 OCR 가이드
- 설명: Gemoo Snap, Google Drive, 온라인 도구별 단계와 전처리 팁, SOP를 한 번에 정리한 가이드입니다.



