目的と対象読者
このガイドはLinuxサーバーで稼働するサービスの負荷監視を効率化したいシステム管理者、SRE、開発者向けです。atopの基本操作、出力の読み方、対処手順、代替ツールとの比較、運用プレイブックを含め、実運用で使える形にまとています。
重要用語(1行定義):
- atop: Linuxのリソース使用状況とプロセス単位の負荷をリアルタイム/履歴で監視できるコマンドラインツール。
目次
- atopとは
- インストール方法
- 基本的な出力と各行の意味
- 対話コマンド一覧と使い方の例
- 実践: 問題の切り分け手順(ミニ・メソドロジ)
- 運用用チェックリスト(役割別)
- インシデント対応プレイブック(簡易ランブック)
- いつ失敗するか/制限事項
- 代替ツールと比較
- 導入時の互換性・パッチ注意点
- 受け入れ基準(テストケース)
- ファクトボックス
- まとめ
atopとは
atopはコマンドライン上でシステム全体およびプロセス単位の負荷状況を表示するモニタです。CPU、メモリ、ディスク、ネットワークの消費状況をパフォーマンスの観点から表示し、どのプロセスが負荷を起こしているかを追跡できます。ログを保存して後で解析・長期トレンド把握にも使えます。
注意: ディスクのプロセス別負荷やネットワークのプロセス別負荷は、カーネル側の「storage accounting」や「cnt」パッチの有無に依存します。これらが無いとプロセス単位の詳細が表示されないことがあります。
インストール
Debian系(Ubuntu、Linux Mintなど)では次のコマンドでインストールできます。
sudo apt-get install atopRed Hat系(RHEL、CentOS、Fedora)ではyumまたはdnfを利用します。
sudo yum install atop
# または
sudo dnf install atop配布されたバイナリやソースからビルドする方法もあります。パッケージ名はディストリビューションで異なる場合があるのでリポジトリを確認してください。
atopの起動と基本表示
インストール後、管理者権限で起動します。
sudo atop下記は対話画面の一例です(画像はサンプル)。
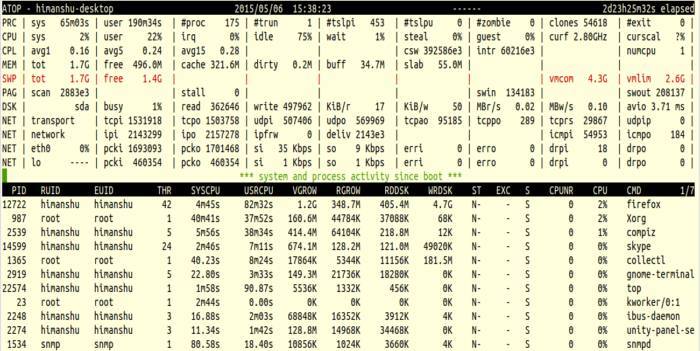
画面は大きく「システムレベル」と「プロセスレベル」に分かれます。デフォルトの更新間隔は通常10秒です。
システムレベル出力の各行(まとめ)
以下は画面上部に表示される主要行とその意味です。
- PRC: システム/ユーザモードで消費したCPU時間、プロセス数、実行中スレッド数やスリープ状態数、ゾンビ数、クローン呼び出し数、インターバル内に終了したプロセス数など。
- CPU: カーネル(sys)、ユーザ(user)、割り込み(irq/softirq)、アイドル(idle)、ディスク待ち(wait)などの割合。マルチプロセッサでは個別CPU行(cpu)が追加されます。
- CPL: ランキューにあるスレッド数、I/O待ちのスレッド数、コンテキストスイッチ数(csw)、割り込み数(intr)、利用可能CPU数など。
- MEM: 物理メモリ総量(tot)、空き(free)、ページキャッシュ(cache)、ディスクにフラッシュが必要な(dirty)、バッファ(buff)、スラブ(slab)等。
- SWP: スワップ全体(tot)、空き(free)、コミット済み仮想メモリ(vmcom)、コミット上限(vmlim)。
- DSK: ディスクの忙しさ(busy)、読み書きリクエスト数(read/write)、1リードあたりのKiB(KiB/r)、1ライトあたりのKiB(KiB/w)、読み書きの帯域(MBr/s / MBw/s)、平均キュー深度(avq)、平均遅延(avio)など。
- NET: トランスポート層(TCP/UDP)、IP層、各インターフェースごとの統計が表示されます。
色付け(赤・シアン等)で重要度を示します。例えばあるリソースが臨界値を超えると、その行全体が赤く表示されます。
注意: 出力の詳細はmanページ(man atop)を参照してください。
対話コマンド一覧(よく使うキー)
atopはキーボードから表示内容を切り替えて使います。主なキー:
- m: メモリ関連表示
- d: ディスク関連表示
- n: ネットワーク関連表示
- v: プロセスの特性一覧(メモリ/スレッド等)
- c: プロセスのコマンドライン表示
- t: プロセスのツリー表示(もし利用可能なら)
- h: ヘルプ
- q: 終了
例: コマンド行をプロセス一覧に付けて確認したいときは、起動後にcを押します。スクリーンショットの例:
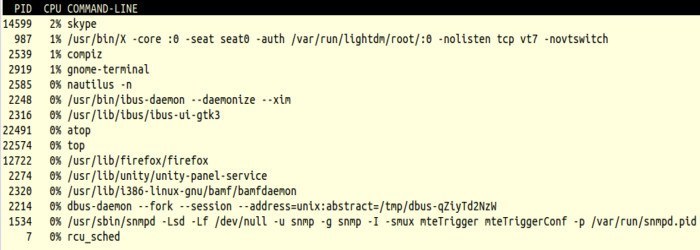
このように各プロセスのコマンドライン引数を確認できます。
実践: 問題の切り分け手順(ミニ・メソドロジ)
以下は実際の障害時に素早く原因を絞るための手順です。簡潔なチェックリスト形式で示します。
- atopを起動して全体像を掴む(sudo atop)
- PRCとCPU行を確認してCPUバウンドかを判定する(CPU行のuser/sys/irq)
- MEMとSWPを確認してメモリ枯渇・スワップ発生を確認する
- DSKのbusyとavioを確認してディスクI/Oがボトルネックか判定する
- NET行でインターフェースやIP/TCPの帯域やエラー確認
- 問題となるリソースが特定できたら、プロセスレベル(v, c)で影響のあるプロセスを特定
- 影響プロセスのPIDを取得してログ参照/straceやgdbは慎重に実行
- 臨時対処(プロセス停止、リソース制限、プロセス再起動)を実行
- 再発防止のためモニタ閾値設定とアラートルールを整備
役割別チェックリスト
以下は日常運用で役立つ短いチェックリストです。
Sysadmin(運用担当):
- atopを起動して5分間のスナップショットを取得
- CPU負荷と平均負荷(load average)の差を確認
- ディスクI/OのBusy率が高ければiostatやiotopを追加で実行
- メモリが逼迫していればスワップの発生を確認
SRE/オンコール:
- atopログのローテーションと保管ポリシーを設定(履歴解析用)
- 高負荷時の自動トリガ(監視ツール→PagerDuty等)を設定
- インシデント後にatopのログを使って主原因報告を記載
開発者:
- アプリケーションがCPUスパイクを起こす場合、プロファイル取得を依頼
- メモリリークの挙動はatopのメモリ時系列で確認
インシデント対応プレイブック(簡易ランブック)
以下は「CPU使用率が継続的に高い」場合の簡易ランブックです。
- 影響確認: atopでCPU行とPRCを確認。
- プロセス特定: vキー、cキーで高CPUを消費しているPIDを特定。
- 軽微対処: 該当プロセスを優先度下げ(renice)して様子を見る。
- 必要なら一時停止/再起動: サービスの再起動手順に従い安全に再起動。
- 永続対処: コードプロファイル、負荷試験、スケールアウト検討。
- ポストモーテム: atopのログとサーバログをまとめて原因分析。
重要: 本番での強制killやstraceの利用は副作用があるため、影響範囲を必ず確認してから実行してください。
いつ失敗するか/制限事項
- カーネルの設定次第でプロセス別のディスク/ネットワーク統計が取得できない場合がある(storage accountingやcntパッチ)。
- コンテナ環境(Docker、Kubernetes)ではホスト側とコンテナ側で表示が異なることがある。namespaceの扱いに注意。
- atopは瞬間的なスパイクよりも継続する負荷の追跡に強いが、非常に短周期(ミリ秒単位)の事象は別ツールでの補完が必要。
- 大規模ホストで多数のプロセスを同時に監視すると表示が重くなる場合がある。
代替ツールと比較
短い比較表(質的):
- atop: プロセス単位の詳細+履歴保存に強い。運用での調査に有用。
- top/htop: インタラクティブで軽量、プロセス操作しやすい。プロセス一覧中心。
- iostat: ディスクI/O特化の統計取得に強い(長期分析向け)。
- vmstat: システム全体の軽量なサマリを短周期で取得するのに向く。
- nmon: プロファイル/チャート化も可能で、性能解析に便利。
- sar (sysstat): 長期収集と履歴分析に向いている(バッチ収集)。
選び方のヒューリスティック: 即時調査なら atop / htop、I/O中心なら iostat/iotop、長期トレンドなら sar。
互換性とパッチに関する注意点
- process-levelのディスク/ネットワーク統計はカーネルの機能に依存します。使用するディストリビューションのカーネルとatopのバージョンの互換性を確認してください。
- コンテナやcgroups環境では表示される値がコンテナ内の論理資源に基づくことがあり、ホスト全体の値と乖離します。
- 特定の機能(例: per-process disk accounting)は古いカーネルやデフォルト設定では有効でない可能性があります。必要時はカーネル設定やパッチの導入を検討してください。
受け入れ基準(テストケース)
導入後に満たすべき基本的な受け入れ基準:
- atopを起動して主要行(PRC/CPU/MEM/DSK/NET)が表示される
- cキーでプロセスのコマンドラインが確認できる
- 10秒程度の負荷発生時にatop上で該当資源の色付き表示が出る
- ログ保存(/var/log/atop等)を有効化して、後から特定時刻のログを解析できる
運用テンプレートとチェックリスト(導入時)
- インストール(パッケージ確認、バージョン管理)
- atopの自動起動設定(cron/atop自体の収集スクリプト)
- ログのローテーション設定(logrotate)
- 監視連携:Prometheus/Datadog等へアラート連携する場合はエクスポータや収集パイプラインを検討
- ドキュメント化:コマンドの使い方、よくある兆候と対処方法をWikiに記載
ミニ・チートシート(よく使うコマンド)
- atop(全体)
sudo atop- 1回だけ現在値を取得して表示(インターバル0)
sudo atop -R 1 1- ログを保存して後で解析(例: /var/log/atop/日ごとのログ) 多くのディストリビューションではatopのサービスがログ収集を行うユーティリティを含んでいます。
ファクトボックス
- デフォルト更新間隔: 通常10秒(設定可能)
- 主な対象: CPU/メモリ/ディスク/ネットワーク/プロセス
- 利点: プロセス単位のリソース消費を履歴とともに追跡できる点
- 制限: カーネル依存の機能があるため環境によってはプロセス別のI/Oが取得できない
運用上のリスクと軽減策
- 誤ったプロセス停止でサービス影響を与えるリスク → 事前にサービス依存関係と再起動手順をドキュメント化
- 履歴ログの肥大化 → ログローテーションと保存期間を定める
- コンテナ環境での誤解 → ホストとコンテナ内の双方で計測し、差分を理解する
日本ローカルの注意点
- 日本語環境でターミナルのロケール設定が不適切だと表示崩れが起きる可能性があるため、UTF-8のロケールを使用してください(例: LANG=ja_JP.UTF-8)。
- 企業内の監査や記録保存ポリシーに合わせてatopログの保管期間とアクセス制御を設定してください。
まとめ
atopはLinuxの負荷監視において現場で非常に有用なツールです。インタラクティブにリアルタイムで調査できるだけでなく、ログ保存を有効にすれば事後分析やトレンド解析にも役立ちます。導入時はカーネル設定やコンテナ環境の違いを理解し、運用プレイブックとログ管理を整備することを推奨します。
重要: atopは万能ではありません。短周期のイベントや深いプロファイリングは専用ツールで補完してください。
短い行動プラン(100〜200字の導入告知文)
導入告知: 新たにLinux負荷監視ツール「atop」を運用に導入しました。CPU・メモリ・ディスク・ネットワークとプロセス単位の履歴分析が可能です。まずはステージ環境で試験運用を行い、本番ではログ保存と自動アラート連携を設定します。
参考: さらに詳しい使い方は man atop を参照してください。



