Docker DesktopでCPUとメモリ使用量を監視する方法
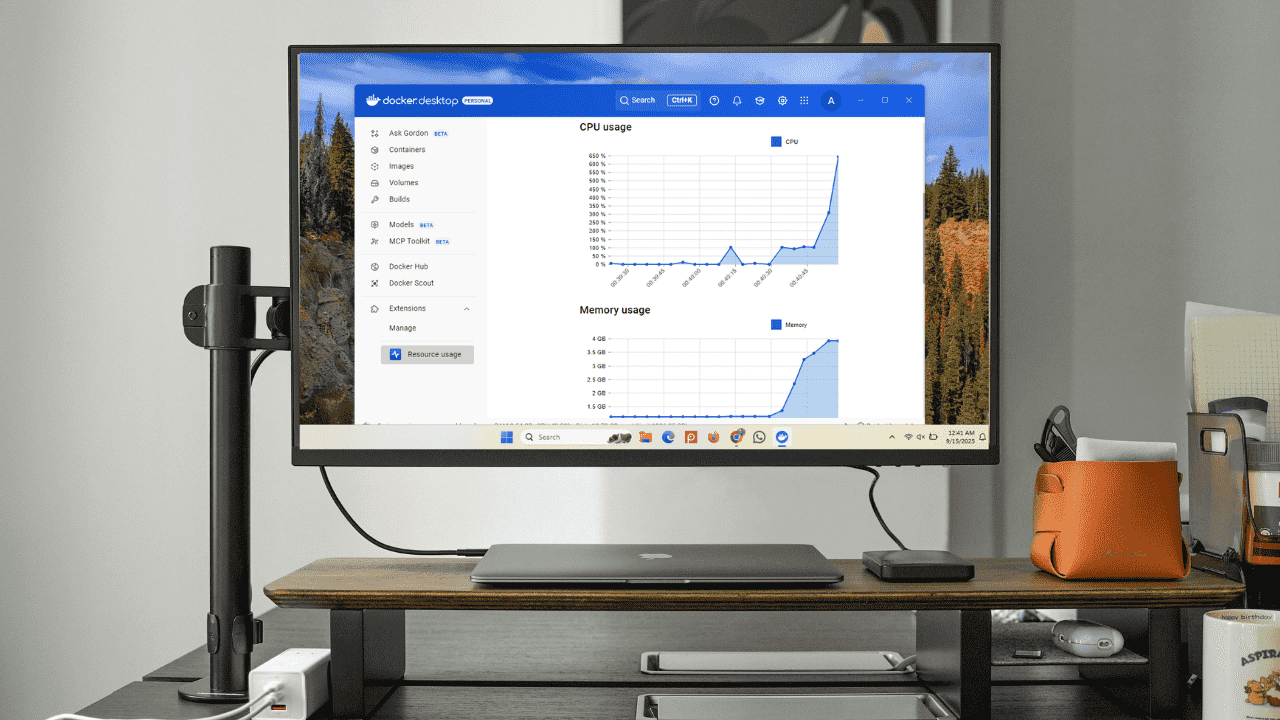
重要: Docker Desktopは仮想化層(WSL2/Hyper-V/HyperKit)上で動作するため、ホストで見える負荷がコンテナだけでなく仮想化プロセス由来であることを念頭に置いてください。
なぜDocker Desktopでリソースを管理する必要があるか
Docker DesktopはコンテナをホストOSの上位にある仮想化環境で動作させます。WindowsではWSL2やHyper-V、macOSではHyperKitが使われ、これによってコンテナの挙動はプラットフォーム間で一貫します。一方で仮想化層やDocker自身のバックグラウンドプロセスもCPUやメモリ、ディスクI/Oを消費します。
そのため、以下を達成するためにリソース管理が必要です。
- システム全体の応答性を保つ
- 特定のコンテナが過剰にリソースを使っていないか把握する
- 開発・テスト環境での隣接プロセスへの影響を最小化する
Docker DesktopはCPUコア数・メモリ割当・ディスク制限を設定するUIを提供し、不要なイメージやコンテナのクリーンアップ機能も備えています。リソース消費の多くは個々のコンテナが原因の場合もあれば、Dockerエンジン側や仮想化レイヤーが原因の場合もあります。したがって定期的な監視と原因切り分けが重要です。
Docker DashboardでCPUとメモリを監視する手順
Docker DesktopのDashboardはGUIで手軽に使える監視インターフェースです。コマンドラインを使わずにリアルタイムのCPU・メモリ使用量を確認できます。
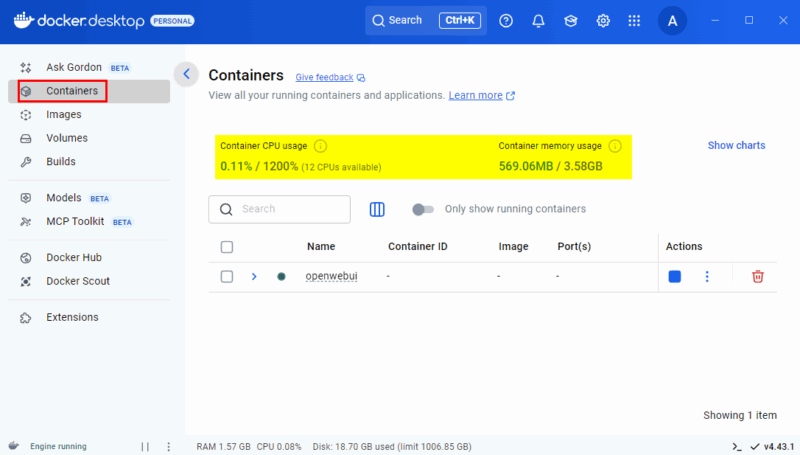
- Docker Desktopを開く
- 左サイドバーの「Containers」セクションを選択
- 実行中のコンテナごとにCPU・メモリ使用率が表示されるのを確認
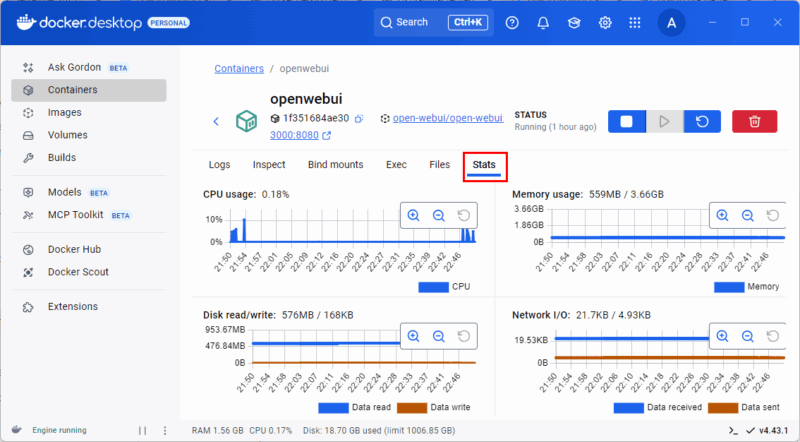
ダッシュボードから任意のコンテナをクリックすると、ログ、環境変数、実行中プロセス、リアルタイムのCPU/メモリ/ディスク/ネットワーク使用状況が確認できます。これは簡易的なトラブルシューティングに非常に便利です。
Resource Usage拡張で監視を強化する
Docker Desktopの標準UIに加えて、Resource Usage拡張を使うと詳細なダッシュボードとグラフ表示が利用できます。複数コンテナを同時に比較したい場合や、短時間のスパイクを視覚的に把握したい場合に有用です。
インストール手順:
- Docker Desktop左サイドバーの「Extensions」を開く
- 検索バーに「Resource Usage」と入力
- 表示された拡張の「Install」ボタンをクリックしてインストール
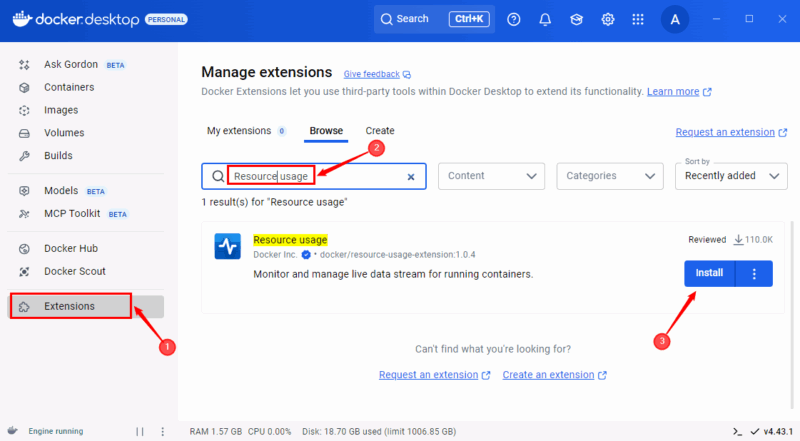
インストール後、左サイドバーにある拡張アイコンから起動できます。コンテナごとのCPU・メモリ・ディスクI/O・ネットワークアクティビティを表やチャートで確認でき、フィルタやソートでリソース消費の多いコンテナを特定できます。
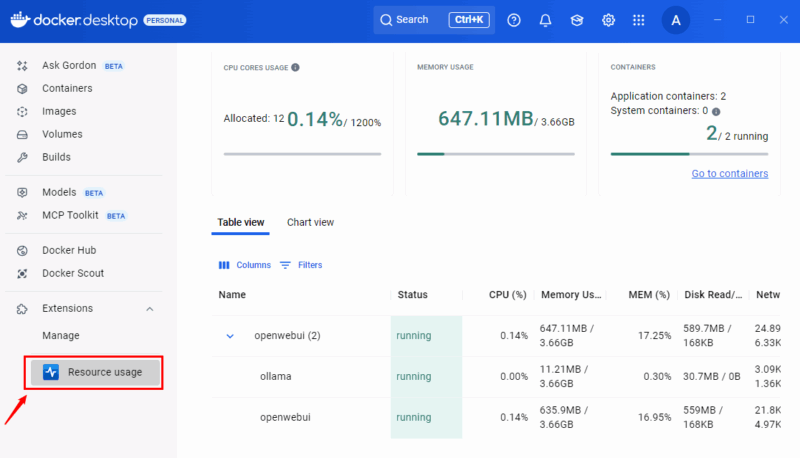
Chart Viewに切り替えると、時間軸に沿ったリソースグラフが表示され、スパイクや異常な挙動を見つけやすくなります。
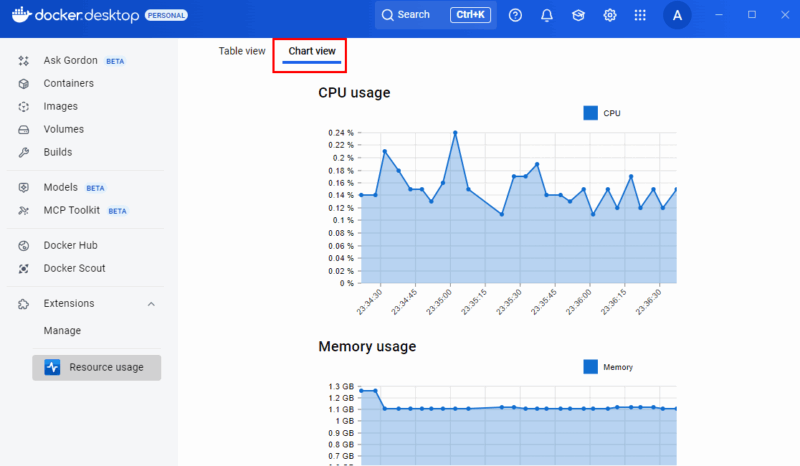
この拡張は標準UIより詳細な情報を提供するため、複数コンテナを同時に運用している環境で特に役立ちます。
docker statsコマンドでリアルタイムに追跡する
GUIよりも端末での確認を好む場合、docker statsコマンドは便利です。実行中のコンテナのCPU、メモリ、ネットワーク、ディスクI/Oをストリーム表示します。Docker Desktop内のターミナルでも実行できます。
docker stats出力はリアルタイムで更新されます。ストリームを停止するにはCtrl + Cを押します。任意のコンテナのみを監視する場合はコンテナ名またはIDを指定します。
docker stats <コンテナ名またはID>
# 例: docker stats openwebui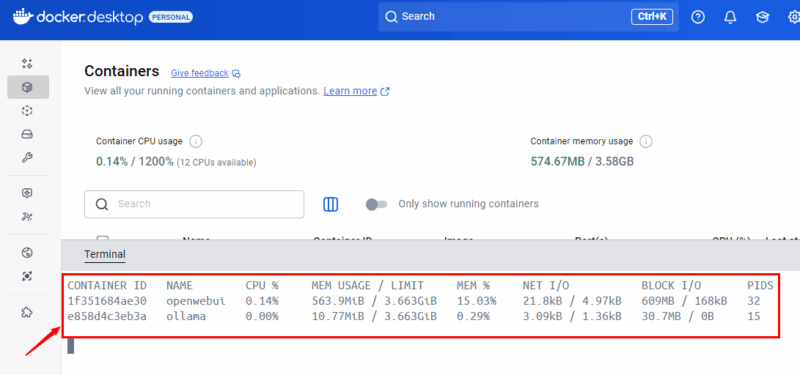
docker statsはスクリプトへ組み込むこともでき、一定間隔でスナップショットを取ってログ化するなどの運用も可能です。
さらに進んだ監視: エンタープライズや長期保存を考える場合
簡易監視はDocker Desktopの機能だけで十分なことが多いですが、長期的な傾向分析やアラート運用を行う場合は専用の監視基盤を検討します。代表的な選択肢の一例(概念説明のみ):
- Portainer: 軽量なGUIによる管理とモニタリング機能。運用の簡素化に向く。
- Prometheus + Grafana: 時系列データの長期保存と柔軟な可視化、アラートを実現する組み合わせ。
- サードパーティSaaS(Datadog等): エージェントを使った統合監視、ログとメトリクスの一元管理。
重要なのは、データの保持期間、アラート条件、運用負荷を見積もり、導入後にメンテナンス計画を作ることです。
典型的な問題とトラブルシューティング手順(SOP)
以下は高いCPU/メモリ消費を検知した際の簡易プレイブックです。状況に応じて順序を調整してください。
- 影響範囲の特定
- DashboardまたはResource Usageで最もリソースを使っているコンテナを特定する
- docker statsでリアルタイム確認
- ログとプロセス確認
- コンテナ内のログを確認しエラーや繰り返し処理がないか見る
- docker execでコンテナに入りtopやpsを確認
- リソース上限と再起動検討
- 必要に応じてメモリ・CPUの制限を設定して挙動を観察
- 問題が継続する場合はコンテナを再起動して再発するか確認
- 永続化された負荷か確認
- しばらく観察してスパイクか継続負荷かを判定
- 根本原因対応
- アプリケーションのメモリリーク、無限ループ、過度なキャッシュなどを修正
インシデント用テンプレート(実用的なテーブル)
| 項目 | 記入例 | 備考 |
|---|---|---|
| 発見日時 | ログのタイムスタンプ | |
| 発見手段 | Dashboard / Alert / 手動 | |
| 影響範囲 | コンテナ名、サービス名 | |
| 初動対応者 | 連絡先 | |
| 影響度 | 高/中/低 | サービス停止の有無 |
| 一時対処 | 再起動/スケールダウン/制限適用 | |
| 恒久対処 | コード修正/設定変更/アーキ検討 | |
| 完了報告 | 関係者に周知 |
役割別チェックリスト
開発者、運用担当者、テスト担当者それぞれの視点で短いチェックリストを示します。
開発者:
- ローカルでのリソースエミュレーション(細かい負荷テスト)を行ったか
- 不要なデバッグログや重い処理を本番コードに残していないか
- メモリリークが疑われる箇所の単体テストを実施したか
運用担当者:
- リソース使用率の閾値とアラートを定義しているか
- 日常のキャパシティレビューがスケジュールされているか
- 画像や古いコンテナのクリーンアップルールを決めているか
テスト担当者:
- 負荷試験でコンテナレベルのリソース消費を計測したか
- スパイク時の回復時間(RTO)の測定を行ったか
メンタルモデルとヒューリスティクス(判断のための考え方)
- どこに責任があるかをまず切り分ける: アプリケーション層(コンテナ内)か、Docker/仮想化層か。
- スパイクは一過性か継続性かを判定する: 一過性ならバーストを許容、継続なら根本原因を追う。
- 小さな変更で再現するか試す: 設定変更→再現性確認→本番展開の順でリスクを下げる。
決定フローチャート
flowchart TD
A[高いCPU/メモリを観測] --> B{単一コンテナが高負荷か}
B -- Yes --> C[そのコンテナのログとプロセスを確認]
B -- No --> D[ホスト側・Dockerエンジンを確認]
C --> E{原因がアプリケーションか}
E -- Yes --> F[アプリ修正・リリース]
E -- No --> G[コンテナ設定(メモリ/CPU制限)を調整]
D --> H{仮想化層が高負荷か}
H -- Yes --> I[VM設定・WSL2/Hyper-Vを見直す]
H -- No --> J[ネットワーク/ディスクI/Oを調査]コマンド・チートシート
# すべてのコンテナのリソースをストリーム表示
docker stats
# 特定コンテナのみ
docker stats <コンテナ名>
# コンテナのログ確認
docker logs -f <コンテナ名>
# コンテナに入ってプロセス確認
docker exec -it <コンテナ名> sh -c "ps aux" # シェルに応じて調整
# 不要なイメージを削除
docker system prune --volumesセキュリティとプライバシーの注意点
- ログに機密情報(シークレットや個人データ)を書き出さないでください。監視データはアクセス制御が必要です。
- 外部クラウドサービスへメトリクスを送る場合はデータ保持と同意、法的要件(GDPR等)を確認してください。
- エージェントを導入する際は権限(読み取り/書き込み)を最小権限で設定してください。
1行用語集
- docker stats: コンテナ単位のリアルタイムメトリクスを表示するCLIコマンド。
- Resource Usage拡張: Docker Desktop向けの詳細リソース監視用拡張機能。
- Dashboard: Docker DesktopのGUIによる簡易監視インターフェース。
いつ監視だけでは不足するか(失敗ケース)
- コンテナが短時間にだけスパイクするがログに痕跡が残らない場合、サンプリング間隔が問題で追跡できないことがあります。詳細な時系列データ収集が必要です。
- ディスクI/Oやカーネルレベルのボトルネックはコンテナ単位のメトリクスだけでは見えにくいことがあります。ホスト側の観測やパフォーマンストレースが必要です。
まとめ
Docker Desktopの内蔵ダッシュボード、Resource Usage拡張、docker statsはそれぞれ用途に応じて使い分けられます。短時間の問題確認はダッシュボードやdocker statsで素早く切り分け、長期保存やアラート運用が必要な場合はPrometheus/Grafanaなどの監視基盤を検討してください。役割ごとのチェックリストとSOPを整備しておくと、インシデント対応が高速化します。
まとめのチェック:
- まずDashboardや拡張で誰が何を消費しているかを見つける
- 必要ならdocker statsやdocker execで深掘りする
- 継続的な監視とログ保存が必要な場合は専用基盤を導入する
エンドノート: 小さなローカルテスト環境でもリソースの管理を習慣にすると、プロダクションへの不意な影響を防げます。



