定義(1行)
OCRとは、画像やスキャン文書内の文字を解析して編集可能なテキストに変換する技術です。
この記事の目的と対象読者
- 目的:画像やスクリーンショットから正確に文字を抽出するための実践手順と運用ルールを提供します。
- 対象:学生、ビジネスユーザー、エンジニア、カスタマーサポート、翻訳/ローカライズ担当者。
重要: 画像品質や文字のフォント、手書きの読みやすさによって結果が左右されます。処理後の確認と手動修正は必須です。
目次
- Gemoo Snapでの手順
- Google Driveでの手順
- オンラインOCRツールの使い方
- 精度向上の実践テクニック
- 受け入れ基準(Критерии приёмкиの訳語として)
- 運用/SOP(簡易プレイブック)
- 役割別チェックリスト
- よくある失敗例と対処法
- FAQ
- まとめ
Gemoo Snapを使う(手順と注意点)
OCRの一つの選択肢としてGemoo Snapを利用する方法を詳述します。Gemoo SnapはデスクトップアプリとChrome拡張を提供し、画像認識→編集→コピーのワークフローが用意されています。出力言語コードはEN(英語)などサポート言語で指定できます。
- ダウンロードとインストール
- Windows/Macに対応。必要に応じてChrome拡張もインストールします。
- アプリを起動して、インターフェースからRecognize Text(OCR)機能を選びます。
- Output Language CodeをENなど適切な言語コードに設定します。
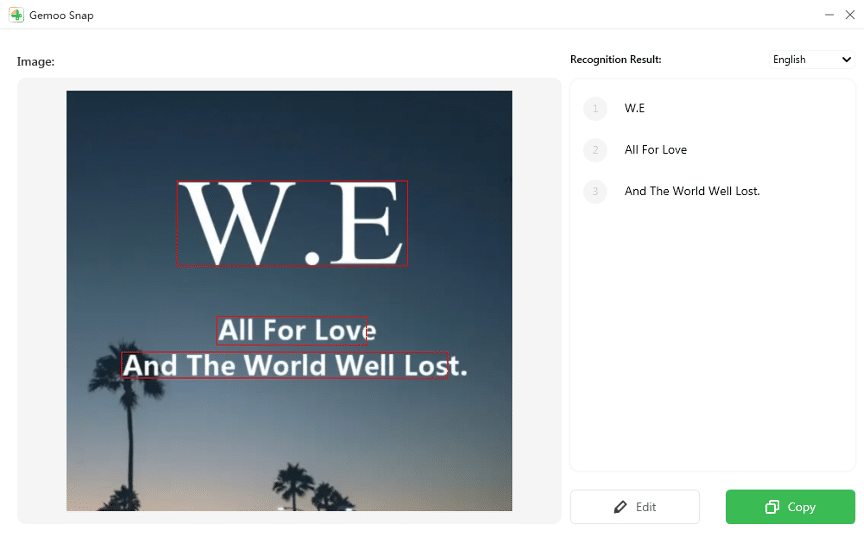
- 文字認識の実行
- 認識したい領域を選択(スクリーンショット可)。
- 認識結果が表示されるので、Editで誤認識を修正します。
- Copyボタンでクリップボードにコピーして、任意の場所へ貼り付けます。

注意点
- 小さな文字や低解像度画像は誤認識の原因になります。可能なら高解像度で撮影し、文字が水平に並ぶように調整してください。
実用ヒント
- 複数言語が混在する場合は、それぞれに対応した言語コードを試すか、分割して処理します。
- 認識後は必ず校正(スペルチェックやコンテキスト確認)を行ってください。
Google Driveを使う方法(無料で手軽)
Google Drive(Google ドライブ)はアップロードした画像やPDFをGoogle ドキュメントで開くと自動でOCRを実行します。手順は簡単です。
手順
- 画像をGoogle Driveにアップロードする。
- アップロードしたファイルを右クリック→「アプリで開く」→「Google ドキュメント」を選ぶ。
- 変換後のドキュメント内に画像下や新規ページとして認識済みテキストが表示される。
- 必要に応じて編集・保存する。
利点
- 無料で使える。クラウド上で処理されるためローカル環境を汚さない。
制約
- 認識精度は画像品質や言語に依存。特殊フォントや複雑なレイアウトは崩れることがある。
注意点
- 機密性の高い画像はクラウドにアップロードする前に社内ポリシーを確認してください(プライバシー/GDPRなど)。
オンラインOCRツールを使う(短期作業向け)
代表的な無料サービス:Online OCR、Free OCR、OCR.spaceなど。操作はほぼ共通で、ブラウザで画像をアップロードして言語を選ぶだけです。
メリット
- インストール不要、すぐに使える。
デメリット
- ファイルサイズや回数に制限がある場合が多い。機密データは注意。
実践的なワークフロー
- 大量処理の場合はAPI付きのサービスを検討する(有償)。
- バッチ処理 → 自動後処理(スクリプトで正規化) → 人手で校正、の順が効率的。
精度向上の実践テクニック
画像品質を上げる
- 解像度:文字が読みやすくなるように300dpi相当を目安に。
- 照明:影や反射を避ける。均一な光源で撮影する。
- 傾き補正:文字ラインが水平になるようにトリミング/回転する。
前処理を行う
- コントラストや明るさを最適化する。
- ノイズ除去、シャープ化、二値化(白黒化)を試すと認識率が上がることが多い。
言語とフォントを指定する
- 使用するOCRがサポートする言語を正しく設定する。
- 固有名詞や専門用語が多い場合は辞書登録やカスタムモデルを使う。
後処理で品質を担保する
- 辞書によるスペル修正とコンテキストチェックを組み合わせる。
- 正規表現で数字や日付、メールアドレスなどを抽出・検証する。
注意: 手書き文字は機械的に読み取るのが難しいケースがあります。手書きOCRはフォント認識より精度が低いことを想定してください。
受け入れ基準
画像から抽出したテキストを受け入れるための最低基準(例)
- 認識率(自動検証): 字種による一致率90%以上(自動検証が可能な場合)。
- 重要フィールド(氏名、金額、日付など)は目視での確認済み。
- レイアウトが重要な場合は表形式の列幅と順序が保たれていること。
これらは組織や用途に合わせて調整してください。
運用/簡易SOP(プレイブック)
目的: 画像からテキストを抽出し、編集可能なデータとして格納する。毎日行う処理のフロー。
ステップ
- 画像の取得と分類(機密か否か、言語、フォーマット)
- 前処理(解像度、傾き補正、ノイズ除去)
- OCR実行(Gemoo Snap / Google Drive / API)
- 自動後処理(正規化、スペルチェック、日付/数値の検証)
- 人的レビュー(重要項目のみ)
- 完了保存とログ記録(誰がいつ処理したか)
ロールバック
- 認識結果が基準未満の場合は原画像を再取得し、前処理パラメータを変更して再実行する。
役割別チェックリスト
データ入力担当者
- 画像の解像度と向きを確認
- 「OCR対象」タグを付与
品質管理担当者
- 抽出テキストのサンプル検査(ランダム抽出)
- 誤認識の傾向を記録して学習材料にする
エンジニア(自動化)
- API呼び出しの再試行ロジックを実装
- 後処理スクリプトのユニットテストを作成
法務/プライバシー担当
- 機密データがクラウドに送信される場合の承認確認
- データ削除要請対応フローを定義
よくある失敗例と対処法
失敗例: 小さな画面のスクリーンショットで誤認識が多い 対処: 可能な限り拡大してOCRにかける、または高解像度で再取得する。
失敗例: 複数言語が混在していて認識が不安定 対処: 言語ごとに領域を分割して処理するか、多言語対応モデルを使用する。
失敗例: 手書き文字がほとんど読めない 対処: 人力での転記を前提に、OCRは補助として使う。手書き専用のモデルを試す。
セキュリティとプライバシーの注意点
- 機密情報(個人識別情報、契約書、機密文書)はクラウドOCRにアップロードする前に必ず社内ポリシーに従ってください。必要ならオンプレミスのOCRソリューションを使うことを検討してください。
- GDPRや各国のプライバシー規制に準拠する必要がある場合、データ送信先と保持期間を明確にすること。
テストケースと受け入れテスト(簡易)
- 高品質印刷文字のサンプルで正確に抽出できるか。期待値: 目視で95%以上一致。
- 低解像度・ぼやけた画像での抽出精度の低下を検出できるか。
- 表形式データで列の順序と項目名が保持されるか。
- 手書きテキストに対する失敗モードをログに残すか。
FAQ
Q: OCRで手書きはどの程度読み取れますか? A: 手書きは認識可能ですが、筆跡や読みやすさに依存します。機械認識は活字より精度が低いため、重要情報は目視確認を推奨します。
Q: どのファイル形式に対応していますか? A: 一般的なOCRはJPEG、PNG、PDF、TIFFに対応します。
Q: OCRの精度はどれくらいですか? A: OCRの精度は90~95%程度と言われることがあり、画像品質、フォント、言語により変動します。
Q: 無料ツールと有料ツールの違いは? A: 有料ツールはカスタム辞書、レイアウト保持、高度な前処理、APIや大量処理のサポートが充実しています。
代替アプローチ(短期〜長期)
- 短期: オンラインOCRやGoogle Driveで手早く抽出して手動校正。
- 中期: Gemoo Snapのようなデスクトップツールを導入してワークフローを標準化。
- 長期: OCR APIと後処理パイプライン(正規化・検証・学習データ生成)を組み合わせて自動化し、フィードバックループで精度を改善する。
まとめ
画像から文字を抽出するにはOCRが中心技術です。Gemoo Snapは手軽で編集機能があり、Google Driveは手早く無料で使えます。どのツールを使うにせよ、前処理・後処理・人の目による検証を組み合わせることが成功の鍵です。運用ルールと受け入れ基準を定め、定期的に精度評価を行ってください。
重要: 機密データや個人情報を扱う場合はクラウド利用ポリシーを必ず確認してください。
要点(まとめ)
- OCRは画像をテキストに変換する技術。ツール選定と前後処理が精度を左右する。
- Gemoo Snap、Google Drive、オンラインツールそれぞれ利点がある。
- 前処理(解像度・傾き・ノイズ除去)と後処理(スペル/正規化)は精度向上に必須。
- 機密情報はクラウド転送に注意。社内ポリシーに従うこと。



