Monitoraggio del carico con atop su Linux
Importante: gli esempi sono stati testati su Ubuntu 14.04; molte funzionalità dipendono dalla versione del kernel e da eventuali patch come “cnt” o dall’accounting di I/O per processo.
Perché usare atop
atop è pensato per l’analisi delle prestazioni in tempo reale e per la registrazione storica delle risorse. A differenza di strumenti più semplici come top o htop, atop può registrare dati e mostrare a posteriori i momenti di picco, oltre a indicare quali processi hanno generato il carico.
Definizione rapida: accounting di I/O per processo = raccolta delle statistiche di lettura/scrittura attribuite ai singoli processi dal kernel.
Installazione
Utenti di sistemi Debian-based (ad esempio Ubuntu o Mint) possono installare atop con:
sudo apt-get install atopSu altre distribuzioni usate il package manager della vostra distro (ad esempio yum/dnf su Red Hat/CentOS/Fedora oppure zypper su openSUSE). È possibile scaricare il codice sorgente o i binari dal sito ufficiale di atop se necessario.
Nota: alcune funzionalità (uso disco/rete per processo) richiedono supporto del kernel: l’accounting di storage per processo o la patch “cnt”.
Avvio e modalità di registrazione
Per avviare atop in modalità interattiva:
sudo atopPer registrare i dati in background (utile per analisi storiche):
sudo atop -w /var/log/atop.raw 600Questo scrive un campione ogni 600 secondi (10 minuti) nel file specificato. Per leggere un file registrato:
sudo atop -r /var/log/atop.rawPanoramica dell’output
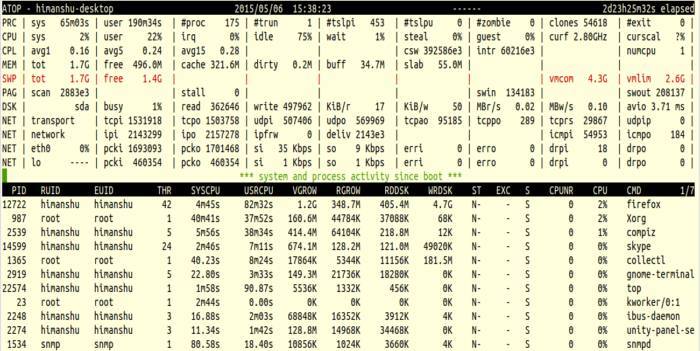
L’output di atop è diviso in due parti principali: informazioni a livello di sistema e informazioni a livello di processo. Le righe di sistema hanno etichette come PRC, CPU, CPL, MEM, SWP, DSK, NET. Di seguito una spiegazione pratica e come interpretare ciascuna riga.
PRC
Contiene: tempo CPU totale in kernel (sys) e user (user), numero totale di processi (#proc), thread in esecuzione (#trun), sleeping interruptible (#tslpi), sleeping un-interruptible (#tslpu), zombie (#zombie), chiamate clone (clones) e processi terminati durante l’intervallo (#exit).
Come usare: un aumento improvviso di #trun indica contesa per CPU; #zombie crescente può indicare problemi di reap dei figli.
CPU
Mostra percentuali di tempo CPU: kernel (sys), user, irq/softirq (irq), idle (nessun processo in attesa I/O) e wait (almeno un processo in attesa di I/O). In sistemi multi-CPU vengono elencati anche i singoli core (cpu in minuscolo).
Heuristics: un valore di wait persistentemente elevato indica I/O-bound; alto sys rispetto a user può indicare workload kernel-intensive.
CPL
Contiene informazioni di carico: numero di thread nella runqueue o in attesa di I/O, context switch (csw), interrupt serviti (intr) e numero di CPU disponibili.
Interpretazione: alta runqueue con poche CPU disponibili → CPU saturata.
MEM
Totale memoria fisica (tot), memoria libera (free), page cache (cache), pagine dirty da flushare (dirty), buffer filesystem (buff), slab (malloc kernel).
Nota: la cache è utile; una bassa free non è necessariamente un problema se cache è alta.
SWP
Swap totale e libero (tot, free), memoria virtuale impegnata (vmcom) e limite massimo (vmlim). Swap intenso indica pressione di memoria a lungo termine.
DSK
Tempo occupato (busy), numero richieste letto/scritte, KiB per read/write, MB/s read/write, profondità media di coda (avq), latenza media avio.
Avvertenza: per vedere I/O attribuito a processi è necessario che il kernel supporti l’accounting di storage per processo o che la patch “cnt” sia applicata.
NET
Mostra attività trasporto (TCP/UDP), livello IP e interfacce attive. Per il dettaglio per processo serve supporto kernel specifico.
Informazioni a livello di processo
Dopo le righe di sistema, atop mostra processi che hanno cambiato l’utilizzo durante l’intervallo. Le colonne includono PID, utente, CPU%, mem%, tempo I/O, e più colonne che variano a seconda delle opzioni e dei tasti premuti.
Comandi interattivi utili
Durante atop, potete premere singoli tasti per cambiare la vista:
- m — mostra dettagli memoria
- d — mostra dettagli disco
- n — mostra dettagli rete
- v — mostra caratteristiche aggiuntive dei processi (I/O, file aperti, ecc.)
- c — mostra la linea di comando completa dei processi
- t — cambia l’ordinamento per CPU
- k — termina un processo (usare con cautela)
- h — aiuto rapido
Suggerimento: combinare -w per registrazione con visualizzazione -r per analisi post-mortem dei momenti di picco.
Quando atop è utile e quando può fallire
Quando usare atop:
- investigare picchi di carico avvenuti in passato (registrazione)
- determinare quale processo ha causato I/O o CPU elevati
- analisi dettagliata di sistema in produzione
Limiti di atop:
- per processi nascosti da container/cgroup, è necessario che il kernel o la configurazione permetta l’attribuzione delle risorse ai processi dentro i container
- per avere I/O e rete per processo potresti aver bisogno di patch o di una versione del kernel che supporti tale accounting
- output complesso: richiede pratica per interpretare correttamente i colori e le cifre
Alternative e strumenti complementari
- top / htop — visione rapida dei processi in tempo reale
- sar (sysstat) — raccolta storica di metriche di sistema
- iostat — dettaglio I/O per disco
- nmon — singolo strumento interattivo per CPU, memoria, disco e rete
- perf / eBPF strumenti — analisi a basso livello e profiling
Scegliere: usare atop quando si vuole correlare attività di processo con metriche di sistema e registrare per analisi posteriore.
Mental model per investigare performance
- Baseline: conoscere il comportamento normale della macchina (utilizzi tipici, picchi previsti).
- Detezione: alert su CPU/IO/rete/mem oltre soglie ragionevoli.
- Drill-down: usare atop per vedere quali processi hanno consumato risorse durante l’intervallo problematico.
- Correzione: intervenire (configurazione, risorse, tuning, scaling).
- Post-mortem: registrare e documentare la causa e la risoluzione.
Playbook rapido per carichi elevati
Passaggi rapidi:
- Aprire atop o leggere il file di log: sudo atop -r /var/log/atop.raw
- Esaminare righe CPU/DSK/MEM per capire se il problema è CPU-bound, I/O-bound o memoria-bound
- Ordinare i processi per risorsa (t → CPU, d → disco) e identificare i top offender
- Se I/O elevato: verificare queue depth e latenza DSK (avq, avio)
- Se swap elevato: controllare vmcom e liberare memoria o aumentare RAM
- Documentare PID/commanda e azioni intraprese
Criteri di accettazione minimal per una diagnosi:
- Capire se il problema è limitato alla macchina o è distribuito
- Identificare il processo principale responsabile del picco
- Registrare timestamp e file di atop per future analisi
Checklist per i ruoli
Sysadmin:
- Installare e configurare cron/servizio per la registrazione periodica di atop
- Verificare permessi e spazio su disco per i file di log atop
SRE/DevOps:
- Integrare gli output di atop con il playbook di incident response
- Configurare rotazione e centralizzazione dei file .raw per analisi
Sviluppatore applicazioni:
- Conoscere come interpretare le colonne CPU/IO per ottimizzare codice
- Fornire metriche applicative correlate agli intervalli di atop
Esempi di comandi utili (cheat sheet)
- Avvio interattivo: sudo atop
- Installazione su Debian/Ubuntu: sudo apt-get install atop
- Scrivere file di registro ogni 600s: sudo atop -w /var/log/atop.raw 600
- Leggere file registrato: sudo atop -r /var/log/atop.raw
- Forzare visualizzazione CPU per processo: nella sessione interattiva premere t
Compatibilità e migrazione
- Comportamento dipende dal kernel: per vedere I/O/rete per processo verificate la presenza di accounting di storage o della patch “cnt”.
- In ambienti containerizzati potete dover eseguire atop sul nodo host o usare strumenti nativi dei container (cAdvisor, strumenti di orchestrazione).
Sicurezza e privacy
atop eseguito con privilegi (root) può mostrare linee di comando complete dei processi, che potrebbero contenere parametri sensibili. Limitare l’accesso ai file di log e agli eseguibili e assicurarsi che l’uso di atop sia conforme alle policy di sicurezza e privacy della vostra organizzazione.
Esempi di casi pratici e come risolverli
Caso 1 — alta CPU
- Sintomi: PRC/CPL mostrano alta runqueue, CPU% user/sys elevate.
- Azioni: ordinare per CPU (t), identificare processo, valutare se throttling, aumentare capacità o ottimizzare codice.
Caso 2 — I/O lento
- Sintomi: DSK busy alto, MB/s elevato e avio grande.
- Azioni: controllare quali processi generano I/O, spostare workload, ottimizzare accessi disco, verificare RAID/controller.
Caso 3 — memoria e swap
- Sintomi: MEM cache bassa, SWP increasing, vmcom vicino a vmlim.
- Azioni: riavviare processi che perdono memoria, aumentare RAM, rivedere limiti di memoria del container.
Piccola guida di accettazione dei test
Test 1: atop registra dati ogni X secondi nel file specificato
- Pass: file .raw cresce e atop -r mostra timestamp registrati
Test 2: Vista per processo mostra linea comando
- Pass: premere c e verificare che la colonna della command line sia popolata
Test 3: Visualizzazione I/O per processo (solo se il kernel lo supporta)
- Pass: colonne I/O non vuote per processi attivi
Glossario in una riga
- runqueue: code di thread pronti per la CPU; runqueue alta = contesa CPU.
Conclusione
atop è uno strumento potente per il monitoraggio del carico su Linux, utile sia in tempo reale che per analisi post-mortem. Per sfruttarlo al meglio, configurate la registrazione, imparate a interpretare le righe PRC/CPU/CPL/MEM/DSK/NET e integrate atop nei vostri playbook operativi.
Note finali: consultate sempre la man page di atop (man atop) per i dettagli su tutte le opzioni e le colonne disponibili.
Breve annuncio:
Atop ora disponibile per i vostri server Linux: installatelo, attivate la registrazione e iniziate a correlare processo e risorse per diagnosi più rapide. Utile in produzione per investigare picchi inattesi e migliorare l’affidabilità del servizio.



