Guida pratica a smartmontools: installazione, uso e monitoraggio SMART
Panoramica rapida
smartmontools sfrutta la tecnologia SMART (Self-Monitoring, Analysis and Reporting Technology) integrata nella maggior parte dei dischi ATA/SATA e SCSI. Gli strumenti possono prevedere degrado o guasti, eseguire auto-test e inviare notifiche. smartctl è l’interfaccia a riga di comando per interrogare e testare i dischi; smartd è il demone che automatizza le scansioni e le notifiche.
Per chi è questa guida
- Amministratori di sistema che vogliono integrare monitoraggio dischi in server o workstation.
- Utenti avanzati che vogliono verificare lo stato SMART dei propri dischi esterni o interni.
Requisiti minimi
- Disco compatibile S.M.A.R.T. (la maggior parte dei dischi moderni lo è).
- Accesso con privilegi root per interrogare i dispositivi (/dev/sdX).
Installazione
Su Debian/Ubuntu e derivate:
sudo apt-get install smartmontoolsSu RHEL/CentOS/Fedora usare il gestore di pacchetti della distribuzione (yum/dnf). Su sistemi BSD o macOS usare i pacchetti disponibili nei repository/port.
Importante: sui sistemi con controller RAID hardware, i dispositivi fisici possono non essere direttamente esposti come /dev/sdX. In quel caso consultare la documentazione del controller.
Verificare che il disco supporti SMART
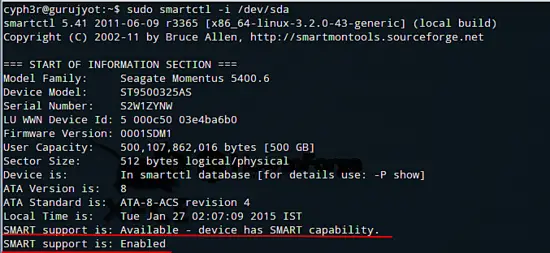
Per ottenere informazioni di base sul dispositivo:
sudo smartctl -i /dev/sdaSostituire /dev/sda con il nome del dispositivo del vostro disco. L’output indica se SMART è supportato e se è abilitato. L’ultima parte dell’output solitamente mostra lo stato globale di salute.
Nota importante: se SMART non è abilitato potete attivarlo con:
sudo smartctl -s on /dev/sdaSe il disco è connesso via SATA, potete forzare il rilevamento del tipo ATA per assicurare informazioni corrette:
sudo smartctl -a -d ata /dev/sdaEseguire test diagnostici
smartctl offre tre test principali: short, long e conveyance (trasporto). Per controllare quali test sono supportati e la durata stimata:
sudo smartctl -c /dev/sdaPer avviare un test lungo (esempio):
sudo smartctl -t long /dev/sdaPer avviare un test breve:
sudo smartctl -t short /dev/sdaPer il test di trasporto (conveyance):
sudo smartctl -t conveyance /dev/sdaI test vengono eseguiti in background. Per leggere i risultati (self-test log):
sudo smartctl -l selftest /dev/sda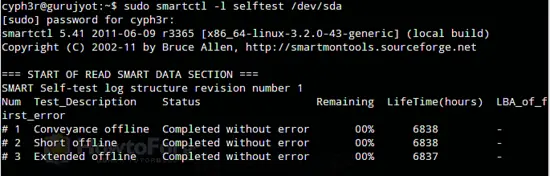
Se il test segnala errori o settori riallocati in aumento, effettuate subito un backup completo.
Interpretare lo stato SMART
Gli output rilevanti sono:
- ATTRIBUTI (es. Reallocated_Sector_Ct, Current_Pending_Sector): indicatori di degrado.
- HEALTH STATUS (OK / FAILED): stato complessivo.
- SELF-TEST LOG: storico dei test e risultati.
Regola pratica (euristica): un singolo settore riallocato non è immediatamente catastrofico, ma una crescita progressiva è un segnale di allarme. Se compaiono errori SMART o il rapporto di salute è FAILED, pianificate la sostituzione del disco.
Esempi rapidi di comandi utili
- Stato di salute rapido:
sudo smartctl -H /dev/sda- Tutte le informazioni SMART:
sudo smartctl -a /dev/sda- Controllo SMART su dispositivi con interfaccia specifica:
sudo smartctl -a -d ata /dev/sdaAbilitare il demone smartd per monitoraggio automatico
smartd è il demone che esegue controlli programmati e può inviare notifiche. Per abilitare l’avvio automatico su Debian/Ubuntu editare:
sudo nano /etc/default/smartmontoolsAssicuratevi che la riga che abilita il servizio non sia commentata. Poi configurate i dispositivi in /etc/smartd.conf:
sudo nano /etc/smartd.confUn esempio di riga nel file di configurazione:
/dev/sda -m root -M exec /usr/share/smartmontools/smartd-runnerSpiegazione dei parametri principali:
- -m root: invia una mail all’utente root in caso di errori.
- -M exec /usr/share/smartmontools/smartd-runner: esegue uno script per azioni custom (se presente).
- -a: seleziona opzioni comuni (equivalente a -H -l error -l selftest -f).
- -s: schedula self-test. Esempio per eseguire short giornaliero alle 02:00 e long settimanale il sabato alle 03:00:
DEVICESCAN -a -H -l error -l selftest -f -s(S/../.././02|L/../../6/03) -m root -M exec /usr/share/smartmontools/smartd-runnerSe DEVICESCAN non funziona, specificare i dispositivi singolarmente (/dev/sda, /dev/sdb, …).
Personalizzare notifiche e azioni
Se non volete usare lo script smartd-runner potete specificare -M on -M off o usare -M exec con il vostro script che invia alert via email, webhook o integra con sistemi di monitoraggio (Prometheus Alertmanager, PagerDuty, ecc.). Lo script può eseguire azioni come:
- invio e-mail
- invio HTTP POST a un endpoint di alerta
- creazione di ticket in un sistema ITSM
Nota: lo script deve essere eseguibile e testato con attenzione per evitare falsi positivi.
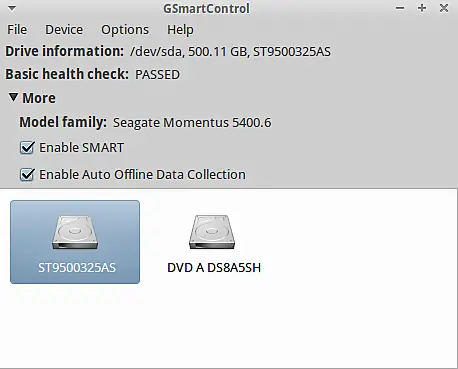
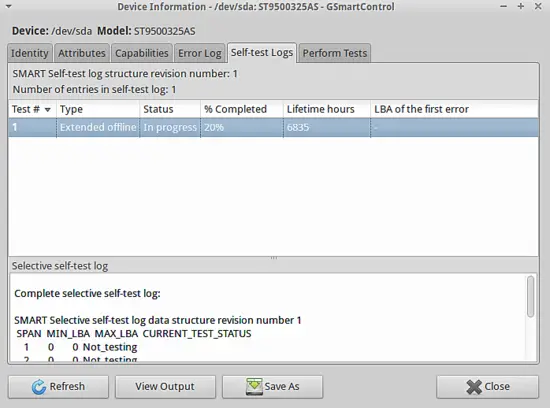
GUI alternativa: GSmartControl
Per chi preferisce interfaccia grafica:
sudo apt-get install gsmartcontrolGSmartControl offre visualizzazione degli attributi, avvio di self-test e log dei test. È utile per utenti desktop o per ispezioni manuali rapide.
Procedure operative (SOP) essenziali
Segue una procedura operativa rapida che potete adattare in azienda.
- Inventario: elencare tutti i dispositivi di storage e verificare se supportano SMART.
- Abilitare SMART su tutti i dispositivi compatibili.
- Avviare scansioni short giornaliere e long settimanali con smartd.
- Configurare notifiche automatiche (mail o integrazione con sistema di monitoraggio).
- Stabilire soglie di escalation (es. 3 settori riallocati in 7 giorni -> ticket di sostituzione).
- Testare procedure di recovery e backup regolari.
Checklist per ruoli
- Amministratore di sistema:
- Abilitare smartd su server critici.
- Integrare notifiche con tool di incident management.
- Automatizzare report mensili sui trend SMART.
- Utente casalingo:
- Installare smartmontools e lanciare un short test settimanale.
- Tenere backup aggiornati su dispositivo esterno o cloud.
- Team di storage:
- Monitorare trend di attributi (Reallocated, Pending, UDMA CRC).
- Schedulare sostituzione preventiva dei dischi con trend peggiorativo.
Casi in cui SMART può fallire o non bastare (controesempi)
- Dischi che falliscono improvvisamente senza segnali SMART: SMART migliora la probabilità di avviso, ma non garantisce il 100% di predizione.
- Controller RAID hardware che mascherano errori SMART: in questi casi si deve interrogare il controller o usare strumenti vendor-specifici.
- Guasti elettrici o fisici improvvisi (cadute meccaniche) che non lasciano tempo ai dati SMART di aggregarsi.
Per questi motivi, SMART è uno strumento prezioso ma non sostituisce backup regolari e strategie di ridondanza.
Approcci alternativi e integrazioni
- Strumenti vendor-specifici: alcuni NAS e server hanno strumenti proprietari più integrati con controller.
- Monitoraggio centralizzato: raccogliere output SMART con exporter (es. node_exporter moduli o script personalizzati) per grafici e alert centralizzati.
- Test di surface/sector mapping avanzati: usare strumenti come badblocks per testare settori in modo più approfondito quando necessario.
Esempio di playbook per incidente (sospetto degrado)
- Ricevuto alert SMART, verificare l’output
smartctl -a /dev/sdX. - Eseguire self-test long se non già eseguito:
smartctl -t long /dev/sdX. - Eseguire backup immediato dei dati critici.
- Pianificare finestra di sostituzione disco se i parametri peggiorano.
- Se il disco è in RAID, procedere con rebuild su nuovo disco e monitorare i log del controller.
- Conservare il disco fallito per analisi o smaltirlo secondo policy aziendale.
Criteri di accettazione per uno smart monitoring affidabile
- Tutti i dispositivi critici mostrano dati SMART leggibili.
- smartd attivo e configurato con notifiche e self-test schedulati.
- Backup e procedure di recovery verificate.
- Dashboard centralizzata con trend degli attributi SMART per almeno 90 giorni.
Mini-glossario
- SMART: tecnologia di auto-monitoraggio dei dischi.
- smartctl: utility CLI per interrogare ed eseguire test SMART.
- smartd: demone che automatizza i controlli SMART.
- Reallocated_Sector_Ct: conta dei settori riallocati, indicatore di degrado.
Suggerimenti pratici (che non richiedono dati sensibili)
- Verificare i log syslog/daemon per messaggi di smartd.
- Testare le email di notifica con un indirizzo non critico prima di usare indirizzi di produzione.
- Non affidarsi esclusivamente alla percentuale di salute: monitorare gli attributi grezzi e la tendenza nel tempo.
Privacy e sicurezza
I dati SMART non contengono tipicamente dati personali, ma possono rivelare informazioni sul modello e l’età del dispositivo. Proteggete gli output e gli script di notifica: gli script eseguibili da smartd devono avere permessi stretti e non devono esporre credenziali in chiaro.
Risoluzione problemi comuni
- Problema: DEVICESCAN non rileva i dischi dietro un RAID hardware. Soluzione: usare lo strumento del vendor o interrogare il controller per esporre i dispositivi.
- Problema: smartd non invia email. Soluzione: verificare che il sistema abbia un MTA configurato o usare uno script che invii via API a un servizio di alert.
Risorse e link utili
- Pagina ufficiale: smartmontools.org
- Pagine man:
man 8 smartctl,man 8 smartd,man 5 smartd.conf
Riepilogo
smartmontools è uno strumento essenziale per il monitoraggio predittivo dei dischi. Non sostituisce i backup, ma migliora la capacità di rilevare problemi in anticipo. Integrare smartctl e smartd in una strategia più ampia di monitoraggio e incident response aumenta l’affidabilità dell’infrastruttura.
Nota importante: eseguite sempre backup prima di operazioni invasive o quando ricevete segnali di degrado SMART.



